こんにちは。データサイエンスチームの白石です。
前回はメトリック学習を用いることで、画像分類モデルの改善ができないかを検討しました。代表的な手法として、Triplet Loss と Center Loss を紹介し、後者に関して実装と実験を行いました。
今回は本連載の内容を振り返りつつ、私自身も試せていない更なる工夫について紹介しようと思います。
第1回では、本連載で使用したデータセットである Oxford-IIIT Pet Dataset(以下、OxfordPet データセット)を簡単に紹介し、Fine-Grained Visual Categorization とは何か、どのようにモデル構築と改善を進めていくのか、という点について説明しました。
第2回では、ResNet-34をファインチューニングすることで、ベースラインモデルを構築する方法を説明しました(Notebook)。また、モデルの実装と実験のための手順を定めて、その内容を説明しました。
実装は以下のような処理の流れを実現しています。

ベースラインモデルの精度として、Validation セットに対して91.6%、Test セットに対して92.1%の分類精度が得られました。
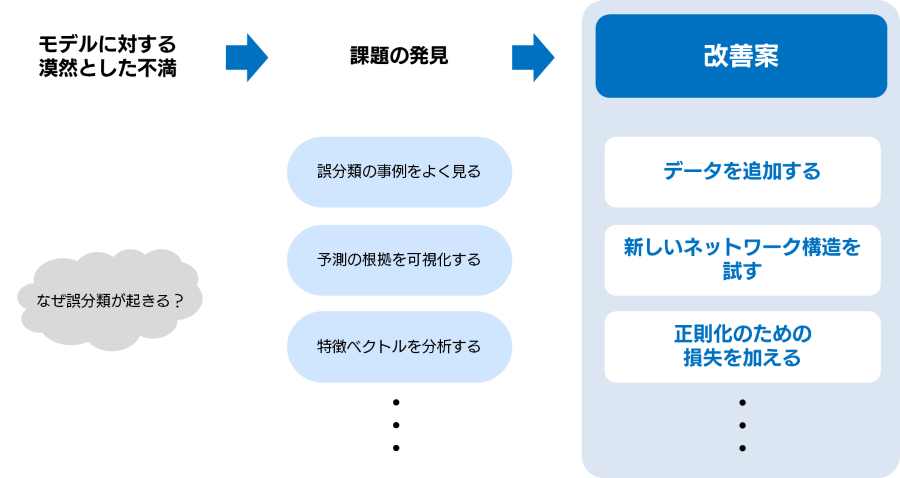
第3回では、ベースラインモデルの課題を見つけるためのエラー分析について説明しました(Notebook)。具体的な誤分類の事例を確認し、いくつかの予測根拠可視化手法を使いながら、毛質や体形といった特徴を分類器がうまくとらえられていないのではないかという仮説を立てました。
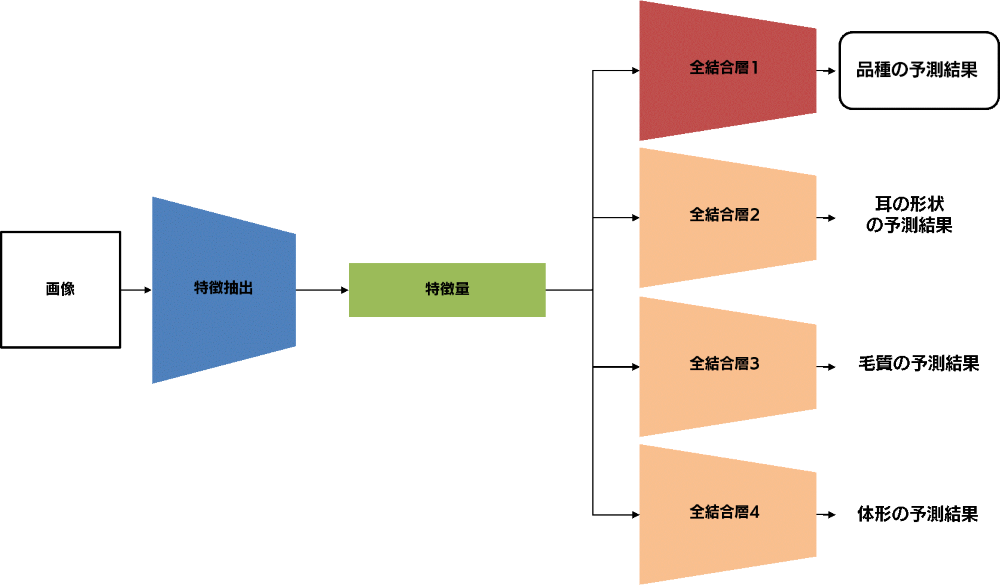
第4回では、第3回で得られた仮説を、直接的にモデルに反映することを試みました(Notebook)。その方法としてマルチタスク学習を採用し、実験を行いました。また、ハイパーパラメータチューニングの基本的な考え方についても触れました。結果としては、Validation セットに対する精度も Test セットに対する精度も、平均的には上回ることができました。
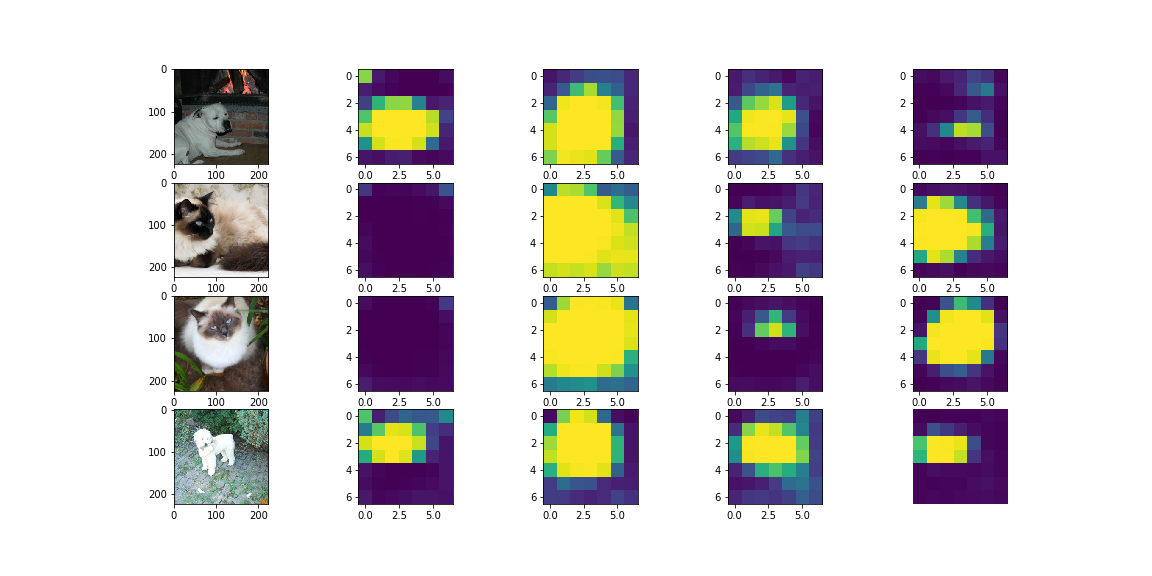
第5回では、Attention 機構を用いることで予測精度の改善ができないかを検討していきました(Notebook1,Notebook2)。特徴量マップに対して1層の Conv 層を使って Attention マスクを生成し、特徴量マップの空間的な重みづけを行うというシンプルな実装と複数枚の Attention マスクを生成するマルチヘッド版の実装を紹介しました。こちらも、平均的にはベースラインモデルの精度を上回ることができました。
最後の第6回では、メトリック学習を用いた精度の向上を試しました(Notebook)。メトリック学習は、CNN を通じて得られる特徴量がカテゴリ内で近く、カテゴリ間で遠くなるようにする正則化の手法であることを学びました。また、その具体例として Triplet Loss と Center Loss を紹介し、Center Loss の実装と実験結果を示しました。精度的にも、ベースラインを平均的に上回り、Test セットに対して93%を超える精度を達成できる場合もありました。
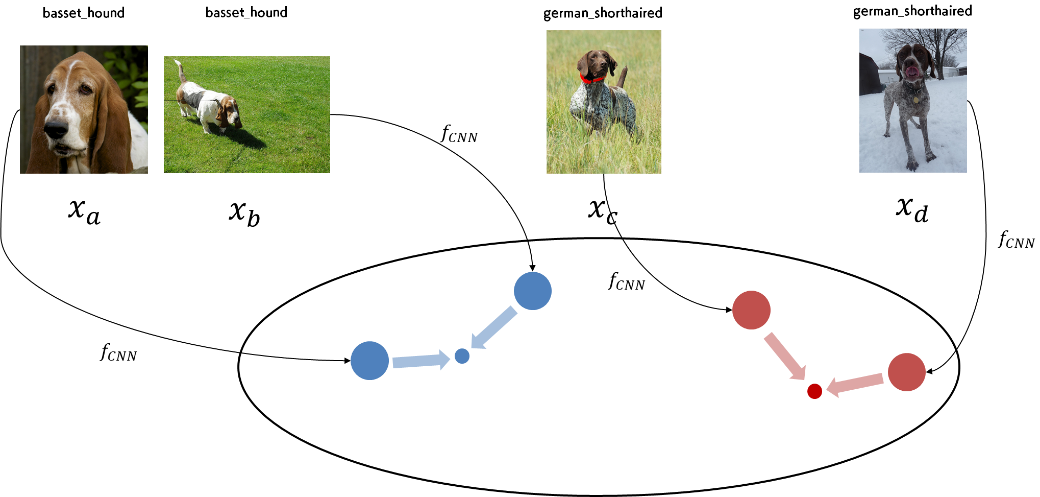
連載の中で行ってきた精度改善の工夫以外とは別のアプローチもまだまだ存在します。そのいくつかを紹介して、連載の締めとしたいと思います。
今回は、画像から特徴量を抽出するネットワークを ResNet-34で固定し、そこから得られる特徴量を改善する、という観点から、いくつかの工夫について紹介してきました。しかし、画像分類のアーキテクチャには様々なものがあり、より深いネットワーク(ResNet-101, 152)や、より幅が広いネットワーク(Wide-ResNet(※1), ResNeXt(※2))、あるいは大規模な強化学習(Neural Architecture Search)によって最適化されたネットワーク(EfficientNet(※3))など、さまざまなアーキテクチャが提案されています。
たとえば、torchvision で pretrained モデルが使用できる ResNeXt-50-32x4d を使って、今回の OxfordPet データセットで実験してみると、以下のような結果となります。
Notebook も用意しましたので、こちらもご参照ください。
左右にスクロールしてご覧ください。
| Validation 精度 | Test 精度 | |
|---|---|---|
| ベースライン(ResNet-34) | 91.6 | 92.1 |
| ResNext-50-32x4d | 93.8 | 93.5 |
今までの試行錯誤を上回る高精度が、簡単に得られることがわかります。一般に、深層学習のモデルは、深ければ深いほど、そして近年では幅も多少広いほうが、精度が良くなるというように言われています。一方で、基本的には精度が良いモデルにはそれなりの計算資源が必要です。クラウド環境でそのようなモデルを学習しようとすると、高スペックの仮想マシンを長時間動かす必要があるため、多大な費用が掛かる可能性があります。また、推論に使用できるハードウェアが限定されることもあります。
Google Colaboratory 上で条件をそろえて ResNet-34 と ResNeXt-50-32x4d の速度比較を行ってみると、バッチサイズ1のデータに対して、ResNet-34 では1回あたり216ミリ秒、ResNeXt-50-32x4d は1回あたり412ミリ秒と、後者の方が2倍近い時間がかかることが確認できます。
推論速度を犠牲にして精度をとるのか、精度を犠牲にして推論速度をとるのか?これはアプリケーションが求める推論速度と、費用対効果の問題になります。精度や推論速度を加味しながら、自分たちのアプリケーションに最も適しているアーキテクチャを選択しましょう。
今回の連載では SGD に限定していましたが、最適化アルゴリズムもまた、多種多様です。「何もわからないときはとりあえず Adam 使っておこう」とか、「似たドメインのデータセットに対するファインチューニングには学習率小さめの SGD が良いかも」とか、機械学習エンジニアの各人の中で経験則が蓄積されてはいると思いますが、本当に何が最良の選択なのかを決める方法はまだ確立されていないというのが現状です。
また、最適化においてもう一つ重要なスケジューラーについても、様々な方法が提案されています。例えば、ReduceLROnPlateau は、Validation 損失などの指標が一定期間改善しなかったら学習率を減少させ、学習の効率を上げるというスケジューラーです。また、CosineAnnealing に代表されるいくつかのスケジューラーは、学習率を定期的に増やしたり減らしたりして、局所最適に陥っている状態から抜け出しやすくするというスケジューラーです。いずれも PyTorch で実装されていますので、興味のある方は試してみると良いでしょう。
今回の連載では、torchvision のチュートリアルなどで採用されている最も基本的なデータ拡張を用いました。データ拡張に関しても様々な研究が進んでおり、各種深層学習のライブラリで、それらの成果が随時追加されています。例えば、torchvision では、画像中のまとまった領域を消去する RandomErasing(※4)という、データ拡張手法が用意されています。RandomErasing を適用すると、下図のような形になります。一番左の画像を入力されると、画像中の一部の矩形領域が消去されます。人間は、ある程度まとまった部分が見えていかなったとしても、他の領域から画像全体を推測し、画像を分類することができます。そのため、このようなデータ拡張を行って画像分類モデルを訓練することは、理にかなっていると言えます。

また、データ拡張そのものを自動化・最適化しようという流れとして、自動データ拡張(AutoAugmentation(※5), Fast AutoAugmentation(※6))の手法も研究されています。後者の高速なバージョンでは、CIFAR-10データセットに対して、3.5GPU 時間(1GPU で3.5時間)で最適なデータ拡張ポリシーを決定できるとされており、実用的な時間で使えるようになってきており、実装も github で公開されています。
問題とするデータセットの絶対量が足りない、といったときに、外部のデータセットから、「雰囲気が似ている画像」を集めて事前学習を行い、良い特徴量を作ろうという試みや、ラベルがついていないデータに対して、比較的信頼できる疑似ラベルを付けて訓練するという半教師あり学習という手法があり、それぞれの分野で研究が進んでいます。
MetaFGNet(※7)という手法では、大規模な拡張データセットを用意し、その中から問題のデータセットのドメインに類似した画像をサンプルし、事前学習に使用することで、データセットの絶対量の不足を補おうとしています。
また、大規模なデータを対象とした場合でも、ごく最近の例として、Semi-Weakly Supervised(※8)という Facebook AI Research が公開した手法では、ユーザーがつけたハッシュタグのようなやや乱雑で本来ついているべきラベルがついていないといったケースが頻発する、規則性が乏しい拡張データを使っています。拡張データをもとに事前学習(弱教師あり学習)を行い、本来のデータセットである ImageNet でファインチューニングした後、それを用いて拡張データに疑似ラベルを付けて、最後にもう一度疑似ラベル付きの拡張データでファインチューニングするという、やや複雑な手順が必要です。この手法によって、(疑似ラベルを付与された)教師データを十億枚規模にまで増やすことができ、ImageNet データセットにおける現時点での世界最高精度を達成しています(Top1 Accuracy 85.4%)。
半年以上続いた本連載も今回でおしまいです。画像分類を通じて深層学習に入門するというコンセプトの連載でしたが、実際には初心者から中級者を目指すための記事という、初学者向けにしては少々ハードルの高い内容になってしまったかもしれません。
記事を書きながら自分自身もまだ勉強が足りない部分があるなあ、と痛感する部分も大きかった本連載ですが、データサイエンスの分野は、非常に広い知識領域が必要な分野ですので、定期的な学びなおしが必要であるということを常々感じています。
本連載が、皆様の深層学習モデルの構築の一助となれば幸いです。
それでは、また別の機会にお会いしましょう。
第4回で行ったマルチタスク学習に関して、全画像に対して追加データを整備して再チャレンジするというお約束をしていました。ここでは、その再チャレンジの成果を説明していきます。結論から先に申し上げますと、残念ながら、前回のマルチタスク学習に比べて精度が良くはなっておらず同程度という結果となっています。
左右にスクロールしてご覧ください。
| Validation 精度 | Test 精度 | |
|---|---|---|
| ベースライン | 91.6 | 92.1 |
| マルチタスクモデル (カテゴリごとのラベル) | 91.92±0.34 | 92.35±0.23 |
| マルチタスクモデル (インスタンスごとのラベル) | 91.80±0.35 | 92.38±0.24 |
そのため、これから説明する内容は半ば失敗談となっており、半ばその失敗を克服して上記の精度まで挽回した記録になっています。Notebook を用意しましたので、詳しい実装については、そちらをご確認ください。
全画像に対して耳の形状、毛質、体形という情報を整理するのは、意外と時間がかかり、全7390枚の画像に対して、およそ12時間かかりました。その作業の中で、以下のような問題が生じていました。
要するに、ラベル付けの基準があいまいだったということになります。早い段階で、このような混乱が生じることを予期し、基準を整理するべきだったのかもしれませんが、まずは一度すべての画像にラベルを付けて、実験してみてから考えることにしました。
さて、上記のようなデータ整備上の問題もあり、何か一工夫加えないとモデルの訓練がうまくいきそうにないことがわかってきました。
そこで、損失関数に少し手を入れることにしました。前回のマルチタスク学習では、サブタスクの損失を、Binary Cross Entropy 損失(以下、BCE Loss)としていました。前回はカテゴリごとのラベル付けだったために、例えば pit_bull_terrier の耳の形状を、(寝耳, 立耳, 半立耳, 断耳)=(0, 0.1, 0.8, 0.1)という形で、各カテゴリへの重みとして表現していました。そのため、通常の分類損失である Cross Entropy 損失(以下、CE Loss)がそのまま使えないという理由があったため、BCE Loss を採用していました。しかし、よくよく考えてみると、このような状況では、KL Divergence を使う方が良いのではないか、という考えに至りました。
KL Divergence(Kullback–Leibler divergence)は、確率分布間の距離を表す指標で、目標とする確率分布(先ほどの例でいうと、(0, 0.1, 0.8, 0.1)が確率分布です)と、モデルが出力した確率分布(各カテゴリの予測確率からなるベクトル)との差異を定量的に評価する指標です。
今回はインスタンスごとに明確なラベル付けがなされているため、BCE Loss や KL Divergence ではなく、通常の分類損失である CE Loss を使う想定でした。しかし、これがなかなかうまくいかず、モデルの訓練が混乱している様子が確認でき、精度はベースラインモデルと同等にとどまりました。そのため、訓練を安定化させるために、Label Smoothing と呼ばれるテクニックを採用することにしました。
Label Smoothing は、分類モデルの訓練の安定化のために用いられる正則化手法です。分類モデルでは、各画像は1つのカテゴリにしか属さないので、対応するカテゴリだけが1その他が0になっている確率分布である one-hot 表現を出力することが理想となります。しかし、このような出力を理想とするのは、少々極端な目標です。というのも、データセットの中には、ほとんど見た目が類似しているカテゴリがあったり、場合によってはラベル付けに間違いがあったりします。このような状態のデータセットで one-hot 表現を目標とするのは、望ましくない特徴量をもとに分類するような分類モデルを作ってしまう可能性を高めてしまいます。
Label Smoothing では、そのような目標を少し緩めるためにノイズを入れ、正解とされているカテゴリ以外にも値が入っている状態を目標とします。
これによって、ある特定のカテゴリに過剰に適合することなく、モデルを訓練することができるようになりますし、多少のアノテーションのミスも吸収してくれます。しかし、注入するノイズが大きければ大きいほど、もともとのラベルが無意味になってしまいますので、この割合 α はハイパーパラメータとしてチューニングする必要があります。

今回の実験では、あまり細かいチューニングを行っていません。そのため、必ずしも最適な値になっているとは限りませんが、α=0.2としました。
以上のように、Label Smoothing を用いることでやや曖昧な基準で行われてしまったアノテーションを有効活用して分類モデルを作ることができました。しかしながら、先に精度の比較を示したように、以前のマルチタスク学習で使ったカテゴリ毎のアノテーションを使った場合とくらべて精度が向上したわけではありません。
マルチタスク学習は、基準が曖昧な今回のようなサブタスクには、やや不向きだったようです。マルチタスク学習にこのような落とし穴があることは、一つの大きな学びだったといえます。今度また犬や猫の画像にチャレンジする際には、ケネルクラブなどのスタンダードを参考にしながらあらかじめ明確な基準を設けるようにしたいと思います。
(※1)Zagoruyko, Sergey, and Nikos Komodakis. "Wide residual networks." arXiv preprint arXiv:1605.07146 (2016).
(※2)Xie, Saining, et al. "Aggregated residual transformations for deep neural networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
(※3)Tan, Mingxing, and Quoc V. Le. "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks." arXiv preprint arXiv:1905.11946 (2019).
(※4)Zhong, Zhun, et al. "Random erasing data augmentation." arXiv preprint arXiv:1708.04896 (2017).
(※5)Cubuk, Ekin D., et al. "Autoaugment: Learning augmentation policies from data." arXiv preprint arXiv:1805.09501 (2018).
(※6)Lim, Sungbin, et al. "Fast autoaugment." arXiv preprint arXiv:1905.00397 (2019).
(※7)Zhang, Yabin, Hui Tang, and Kui Jia. "Fine-grained visual categorization using meta-learning optimization with sample selection of auxiliary data." Proceedings of the European Conference on Computer Vision (ECCV). 2018.
(※8)Yalniz, I. Zeki, et al. "Billion-scale semi-supervised learning for image classification." arXiv preprint arXiv:1905.00546 (2019).
関連ページ
深層学習入門:画像分類モデルを作ろう(1) |




