こんにちは、データサイエンスチームの白石です。
前回 に引き続き、「画像分類モデルの構築」を進めていきます。
前回は、「画像分類モデルの構築」の最初のステップである、「ベースラインモデルの構築」を行いました。
その結果、Test セットに対して92%程度の精度で分類を行うことのできるモデルができました。
今回は、前回構築したモデルを用いて「エラー分析」を行っていきます。
現状のモデルはどのようなケースで分類間違いをしてしまうのかを、具体的な画像を確認しながら見ていきましょう。
前回と同様、Notebook を用意しました。Google Colaboratory に公開している Notebook は誰でも閲覧できますが、実行のためには Google アカウントまたは G Suite アカウントでのログインが必要です。こういった外部サービスの利用は、会社のルールで定められていると思いますので、社内ネットワークから閲覧されている方は、社内のルールを確認することをお勧めします。
問題ない方は、リンク先の Notebook を参照しながら読んでみてください。
※本文中に掲載している犬や猫の画像は、すべて The Oxford-IIIT Pet Dataset(以下、OxfordPet)を引用・加工したものです。OxfordPet は CC4.0 BY-SA で配布されています。
まず、エラー分析の目的を整理しておきましょう。
初回に述べたように、エラー分析の目的は、現状のモデルの課題を発見し、改善のためのヒントを見つけることにあります。
エラー分析のやり方は、いくつかあります。
ここに挙げたもの以外にもあるかもしれません。自分のレベルにあったものを選び、物足りなくなったら、さらに高度な分析を行う、という順序で習得していくのが良いでしょう。
今回の記事では、誤分類してしまった画像をよく見てみる、という最も簡単な方法を基本的には採用しています。そして、必要に応じて個々の画像に対する予測根拠の可視化を行ってみます。本記事では、Grad CAM と Smooth Grad という手法を用いて予測の可視化を行ってみることにします。
エラー分析に入る前に、予測根拠の可視化とは何か、について簡単に説明しておきましょう。
予測根拠の可視化とは、ある入力画像が、なぜあるカテゴリに分類されうるのか、を説明するための方法です。
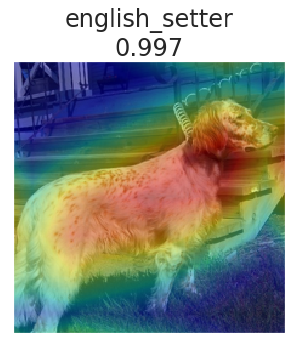
例えば、以下の画像に対して、「english_setter」と分類した根拠は何か、を Grad CAM という手法を使って可視化してみると、以下のようになります。入力画像に対して重ね合わされたぼんやりとした色が、Grad CAM によって得られた予測根拠で、赤橙黄緑青藍紫の順に強い根拠を表しています。
以下の画像では、当たり前と言えば当たり前なのですが、犬がいる部分に対して予測根拠が示されています。また、よく見てみると、犬の頭、特に耳と首付近が最も強くなっていることがわかります。補足ですが、english_setter というカテゴリ名の下についている数字は、予測時にモデルが出力した確率を表しています。このような予測根拠の可視化を通じて、このモデルはこの部分を用いて english_setter と99.7%である、と予測したのだなということが確認できます。
最近 Microsoft が公開した tensorwatch というライブラリには、画像分類モデルの予測根拠を示す、以下のような手法が実装されています。
たくさんありすぎて何を使えばいいのやら、と思われるかもしれませんね。正直に言うと、私もこの中の5本しか論文を読んだことがありませんし、日常的に使っている予測根拠の可視化手法は、実はこのリストには載っていないものだったりします。
各手法の細かい仕組みはひとまず置いておき、今回はあくまでもモデル改善のヒントにするために道具として使うのだ、と割り切って、「これだ」と思ったものを二つ選んで使用することにしましょう。以降の例では、予測根拠の可視化の手法として Grad CAM と Smooth Grad を使っています。
予測根拠の可視化手法は、説明可能な AI(Explainable AI; XAI)という分野の、一つの方向性です。XAI について、より詳しいことを知りたい方は、人工知能学会 HP に掲載されている、『私のブックマーク「説明可能AI」(Explainable AI)』を読まれることをお勧めします。
それでは、本題のエラー分析に入ります。
まずは、混同行列を確認してみましょう。
混同行列とは、分類器によって得られた予測結果を可視化するための表現方法で、どのカテゴリのデータがどのカテゴリとして分類されたのか、を把握することができます。
これによって、間違えやすいカテゴリの把握や、例外的だけれど気になる誤分類を発見することができます。
下の図をご覧ください。これは、前回構築したモデルによって得られる、Validation セットに対する混同行列です。Validation セットとは、構築したモデルが過学習に陥っていないかを確認するためのデータセットです。以下の図は、モデルを使って、Validation セット内の画像のカテゴリを予測してみたらこうなりました、ということを表しています。左側に書いてあるカテゴリ名が画像の真のカテゴリを表し、下側に書いてあるカテゴリ名が画像に対する予測されたカテゴリを表します。行列の中のマスに書いてある数字は、そのマスに所属する画像の枚数を表します。
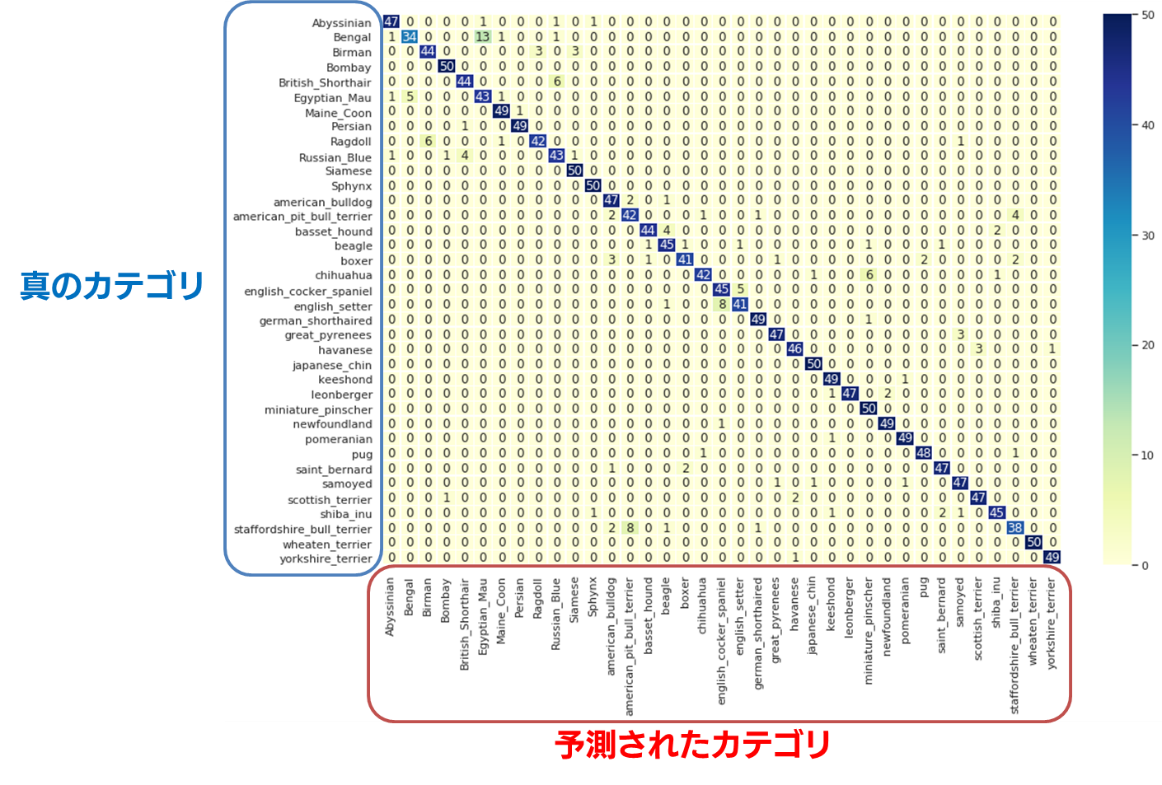
混同行列の対角線に当たるマスは、真のカテゴリと予測されたカテゴリが等しいということを表しています。つまり、ここには、正しく分類された画像の枚数が表示されます。
例えば、「本当は Abyssian で、予測結果も Abyssian だった」という画像は47枚だった、ということがわかります。
一方で、対角線以外のマスは、すべて誤分類を表しています。
例えば、「本当は Abyssian で、予測結果は Russian_Blue だった」という画像が1枚あった、ということを確認できます。エラー分析において重要になるのは、このような「非対角要素」になります。
以下、記述の簡略化のため、「真のカテゴリは X で、予測結果は Y だった」ということを、「X/Y」と表記することにします。例えば、「本当は Abyssian で、予測結果は Russian_Blue だった」というのは、「Abyssian/Russian_Blue」と書きます。
混同行列は画像に限らず、分類モデルを評価する際の最も重要な手掛かりの一つです。作成する際に注意していただきたいのは、行(横方向)が真のカテゴリを、列(縦方向)が予測されたカテゴリを表しているということです。
簡単な検算方法も紹介しておきましょう。各行の合計値は、Validation セットに含まれる各カテゴリの枚数と一致しているはずです。今回、Validation セットは、すべてのカテゴリで50枚ずつ用意していたので、どの行も足し合わせると50になることが確認できます。
さて、基本的な混同行列の見方がわかったところで、少し詳しく混同行列を見ていきましょう。
まず、ぱっと見て、ほとんどの値が混同行列の対角線上に値が集まっていることがわかります。今回のモデルは、Validation セットに対しては91.8%の精度で分類できています。そのため、このように対角線上に9割以上の数字が集まっていることになります。
次に、誤分類に当たる、非対角要素を見てみましょう。まず、Bengal/Egyptian_Mau を表すマスに「13」という大きな数値が入っているのに目が留まります。これは、Bengal の画像が誤って Egyptian_Mau と分類された画像が13枚もあった、ということを意味しています。
また、逆に Egyptian_Mau/Bengal を表すマスにも「5」というそれなりに大きい値が入っています。
このように見てみると、この二つのカテゴリが、相互に間違えやすい、ということがわかります。
他にもこのような組み合わせが無いか探してみると、以下のような組み合わせが、相互に間違えやすい、ということが発見できます。
以上のように、一般的に、分類モデルの精度を改善するときには、解決できたらインパクトの大きい、つまり誤分類が多いカテゴリを最初に確認するのが良いでしょう。
一方で、インパクトは小さいかもしれないけれど、例外的な誤分類からも面白いことがわかることがあります。特に、なんでこんなことも分類できていないんだろう、というタイプの誤分類には、データセットの問題や前処理に関する課題が隠れていることがあったりします。
例えば、3件しかない例外的な誤分類として、「犬か猫か」という大枠すら間違えている、というケースが見られます。具体的には、「Ragdoll/samoyed」「shiba_inu/Sphynx」「scottish_terrier/Bombay」が、それぞれ1件ずつあることが混同行列からわかります。こういった、特殊なケースも丁寧確認していくと、意外と重要な気づきがあるので確認すると良いでしょう。
先ほど混同行列から洗い出した、混同しやすいカテゴリについて、具体的な画像を確認しながら理解を深めていきましょう。
ベンガル(Bengal)とエジプシャンマウ(Egyptian_Mau)は、どちらも体を覆う斑点が特徴的な猫種です。

エジプシャンマウは原始的な種で、この模様は自然にできたものですが、ベンガルの方は比較的新しい種(1970年代)で、イエネコとベンガルヤマネコを交配してできたアメリカ原産の猫種で、縞模様は人工的に作られたものだそうです。
見分け方について調べてみたのですが、決定的な方法は見つけられませんでした。エジプシャンマウの方がやや小さいそうなのですが、画像だけだとなかなか大きさに関する判断は難しいです。そのため、この2種の分類は、今回のデータセットにおける難所と言えるでしょう。
バーマン(Birman)、ラグドール(Ragdoll)、シャム(Siamese)は、いずれも顔の部分がやや黒く、体が白いという特徴を持っている猫種です。

本来のバーマンは、ミャンマー原産の猫種のことを指すらしいのですが、現在見ることのできるバーマンは、シャムとペルシャとの混血だそうです。そのため、バーマンとシャムは血統的に近い猫種で、よく似ているのは当然と言えます。とはいえ、バーマンはペルシャのようなふさふさの毛をもつ一方で、シャムはスムースな毛であることがわかります。このような毛質の情報をモデルに上手く学習させることができれば、バーマンとシャムの誤分類は減らすことができそうです。

では、バーマンとラグドールはどうでしょうか? ラグドールは、バーマンを先祖に持っているという説もあり、二つの猫種は血統的に近いようです。
一応、見分けるポイントとしては、バーマンの足先に生じる「ミテッド」があるそうです。これはあたかも白い靴下をはいているような見た目をしています。

しかし、ミテッドはラグドールにも表れることもあるそうで、見分けるための確実な情報とは言えないようです。この2種の見分けも、今回のデータセットの難所でしょう。
ブリティッシュショートヘアとロシアンブルーは、どちらも青みがかった灰色の毛が特徴的な猫種です。

ロシアンブルーは第二次世界大戦の影響で絶滅しかけた種で、ブリティッシュショートヘアとシャムの交配によってかつての姿に近い状態で作出されたそうです。なので、現在見ることのできるこれら二つの猫種は、血統的に近い位置にある猫種です。

この二種は、確かに色だけを見るとどちらがどちらなのか、見分けがつきにくいですが、ブリティッシュショートヘアの方が明らかにずっしりとした体形をしており、ロシアンブルーの方はシャムの影響を受けてスマートな体形をしています。
写真の角度によって少し見分けにくいこともありそうですが、このような体形の違いをうまく分類器が学習できるようにすることが、改善案として考えられます。
関連ページ
深層学習入門:画像分類モデルを作ろう(1) |




