こんにちは、データサイエンスチームの白石です。
第3回では、ベースラインモデルに対してエラー分析を行い、どのようなケースで誤分類が生じやすいのかを確認しました。その結果、毛質や体形に関する情報がうまくモデルに反映されていないのではないか、といったいくつかの仮説が得られました。この連載の以降の記事では、画像分類モデルを改善するための工夫を紹介していきます。
今回は、その仮説をできるだけストレートにモデルに反映させることを狙い、マルチタスク学習という方法を用いて、より良いモデルを構築できないかを検討していきます。今回も、Notebook を用意しているので、そちらも併せてご覧ください。
画像分類モデル中の畳み込みニューラルネットワーク(以下、CNN)によって画像から抽出された特徴量には、犬や猫の品種を分類する際に有用な情報が詰まっていると考えられます。しかし、前回のエラー分析を通して分かってきたのは、「毛質や体形に関する情報」がモデルに十分に反映されていないのではないか、ということでした。この原因として、全結合層の訓練が不十分であった、という可能性はゼロではありません。しかし一般的に、CNN によって良い特徴量が抽出されてさえいれば全結合層部分の訓練は容易であることが多いため、CNN の訓練が不適切であることが多いです。
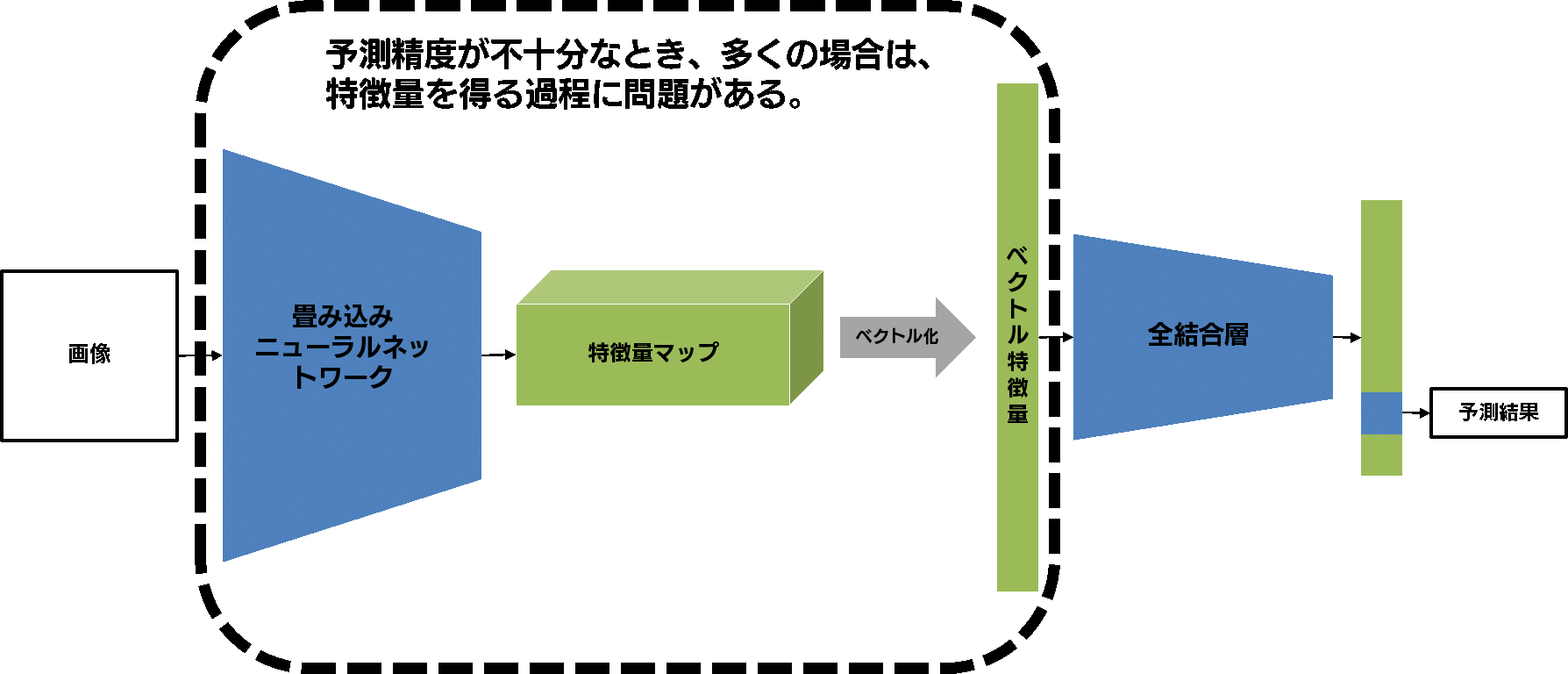
では、どうすれば前回得られたような仮説をうまくモデルに反映し、精度を向上させることができるのでしょうか?
一つの方向性として、CNN それ自体の改善はあきらめてしまい、モデルに入力する特徴量を増やす、というものがあります。CNN では得られなかった情報を「追加の特徴量」として用意して、分類モデルの精度向上を図ります。例えば、多くのデジタル写真には、EXIF と呼ばれるメタデータが付加されています。そこに含まれるジオタグ(写真が撮影された GPS 座標)を入れることで、写真の地理的な条件を考慮した画像分類モデルを構築することができるでしょう。 また、撮影時刻の情報や、各種センサーから得られる気温・湿度なども考慮した画像分類モデルを構築する、なんていうこともできます。
以下の図をご覧ください。これは、ベースラインモデルを少し改造し、追加の特徴量を入力できるようにしたモデルを示したものです。入力された画像から CNN によって抽出された特徴量に外部から入力された追加の特徴量を結合し、全結合層に流しています。
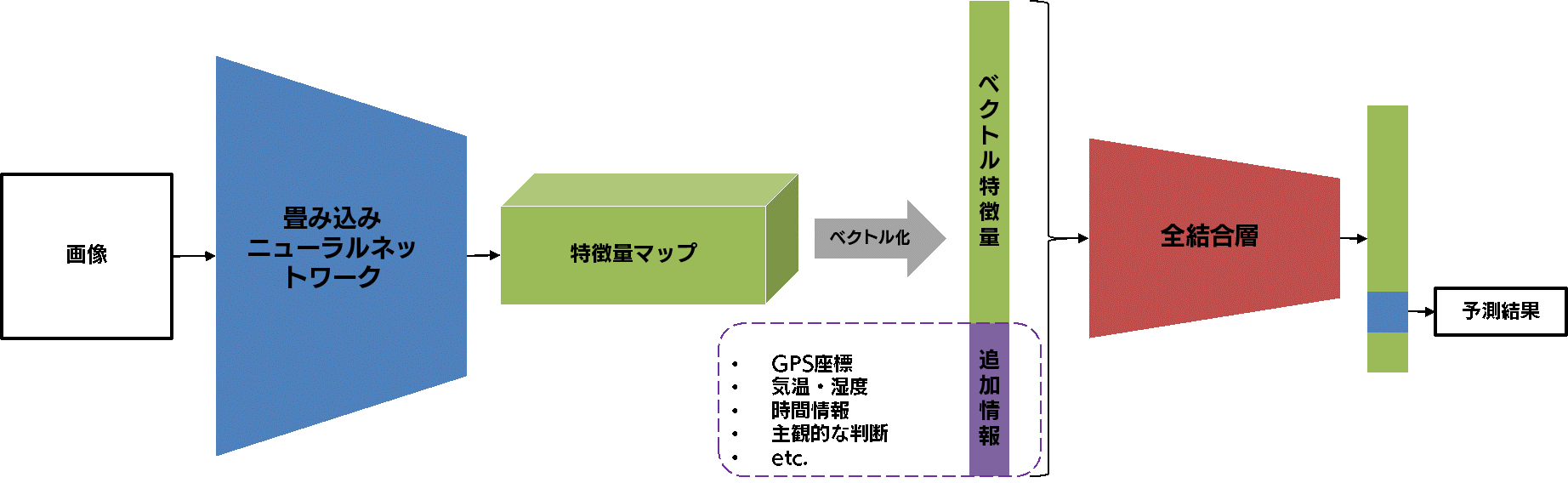
このモデルは、画像から得られる特徴量だけでなく、外部から入力される追加の特徴量も使って分類タスクを解けるように訓練されます。そのため、画像だけでは決して得ることができない情報も考慮した分類モデルを構築することができます。
しかし、このモデルには、推論時に画像以外の情報を必ず入力しなくてはならない、という欠点が存在します。そのため、予測対象の画像と紐づいた追加の特徴量をコンスタントに取得できるようなシステム設計を考えたり、追加の特徴量を改めて集めなおすというデータ整備が必要になったりと、モデルの訓練・運用のコストが増加します。そのため、画像から得られそうな情報をあえて追加の特徴量として用意するのは、少々筋が悪いような気がします。
前回確認したように、犬や猫の品種を分類するのに有効そうな毛質や体形といった情報は、画像を見ればある程度わかりそうな情報ですので、追加の特徴量として用意することはスマートではない気がします。 そのため、何とかして CNN だけで毛質や体形という情報を特徴量に反映できるように訓練したくなります。そこで有効になるのが、今回のメインテーマであるマルチタスク学習です。
マルチタスク学習とは何なのか、Ian Goodfellow らの教科書「深層学習」では、以下のように説明されています。
少々難解なので、私なりの言葉に置き換えてみます。
要するに、マルチタスク学習とは
という方法です。それぞれの意味を順番に見ていきましょう。
1つのモデルで複数のタスクを解くって、どういうこと? と思われる方も多いかと思いますが、以下にその例を示します。
今回構築するマルチタスクモデルとして、以下のような「複数のタスク」を考えてみました。
このような複数のタスクは、例えば以下のようなモデルで同時に解くことができます。
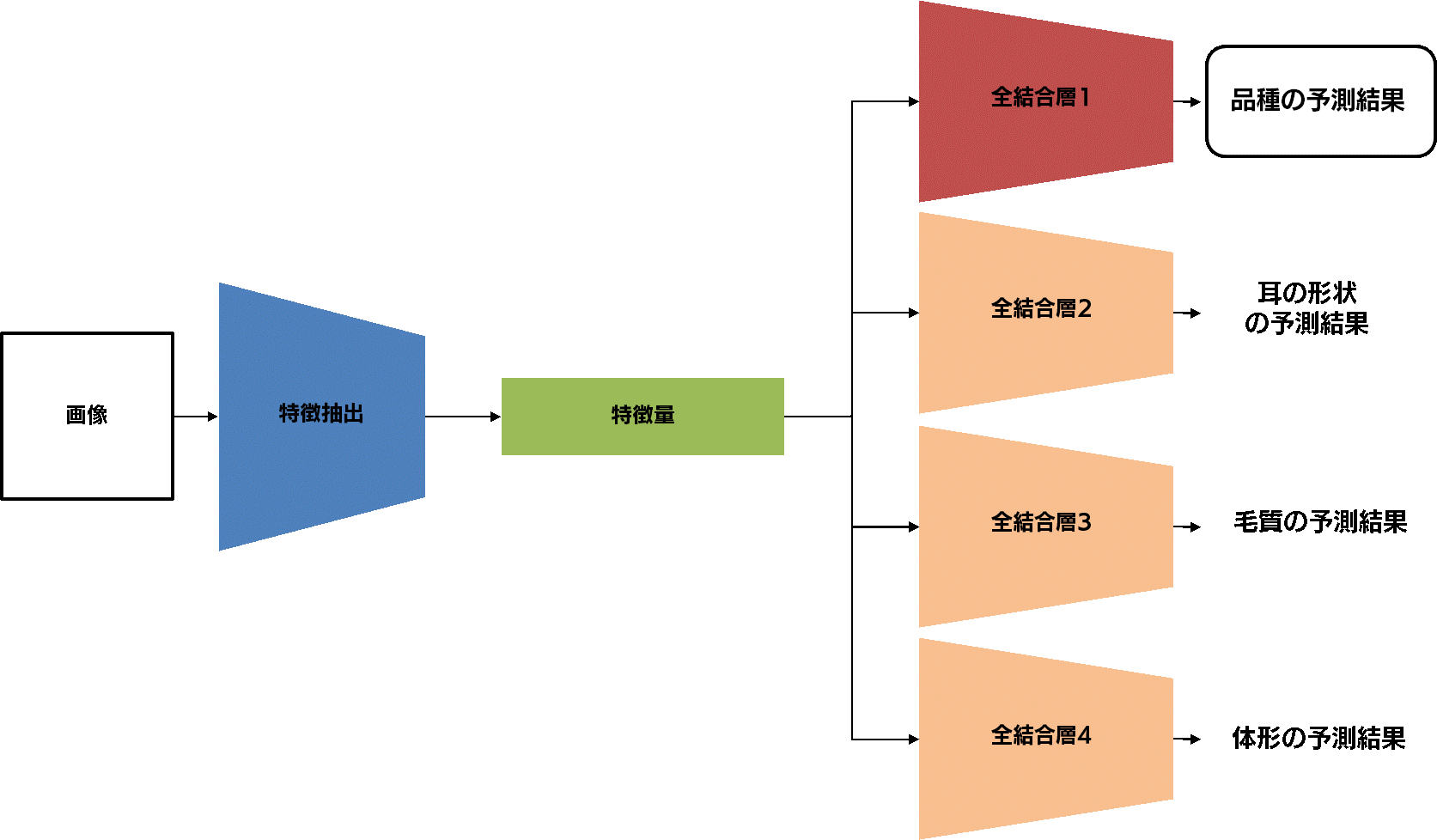
左から入力された画像から、CNN によって特徴量が抽出されます。この特徴量が全結合層1に入力されて犬種・猫種を予測する、という主タスクの部分はベースラインモデルと変わりありません。 しかし、特徴量は主タスクの全結合層以外にも補助タスクに相当する3つの全結合層へと入力されています。 このモデルは、犬種・猫種の予測だけでなく、耳の形状の予測、毛質の予測、体形の予測という、計4つの予測を出力します。これが、1つのモデルで複数のタスクを解く、ということの意味です。
上記のモデルを訓練すると、何が起きるでしょうか?
まず、ベースラインモデルと同様、CNN は、犬種・猫種を予測するための特徴量を抽出できるように訓練されます。 一方で、CNN によって抽出された特徴量を用いて、耳の形状、毛質、体形「も」予測できるように訓練されます。これによって、主タスクである犬種・猫種分類にとって本来であれば有用であるはずの情報(すなわち、耳の形状、毛質、体形)が特徴量から抜け落ちてしてしまわないように CNN を訓練することができるわけです。
ベースラインモデルでは、たまたまあるカテゴリ内で生じているパターンを手掛かりとして画像を分類してしまう、つまり汎化性能が無い特徴量を学んでしまう、という結果に陥ることがあります。このような過学習に陥ってしまわないために、深層学習では様々な工夫を行うことがあり、一般的にこのような工夫を、正則化(Regularization)と呼びます。 正則化によって、Training セットのあるカテゴリの画像で偶然生じているパターンによってモデルが訓練されるのを抑制することができます。マルチタスク学習は、単に1つのモデルで複数の出力を得たい、という実用上の目的で使われることもありますが、過学習に陥らないように学習を安定化させる、という正則化の手法なのです。
マルチタスク学習を行うにあたって、補助タスクを訓練するための追加データの整備が必要になります。これは、前述した追加の特徴量を用いるモデルとは異なり、訓練時にのみ必要なデータです。そのため Training セットに対する追加データを整備するだけで良く、Validation セットや Test セット、そして、実際に運用する際の実データ、に対しては必ずしも必要ではありません。そのため、追加データの整備は、比較的低コストに抑えることができます。
とはいえ、追加データの整備というのは、やはりそれなりに時間のかかるものです。理想的には、一枚一枚の画像に対して、補助タスクの教師信号となる耳の形状や毛質、体系を確認し、Excel に記録していく、というデータ整備が必要です。しかし、主に時間的な制約によって、このようなデータ整備が困難である場合があります。
具体的には、今の私の状況です。今月は様々なイベントが立て続けにあり、なかなかデータを整備する時間が確保できませんでした。そこで、一枚一枚の画像に対してデータを整備するのではなく、以下のように、カテゴリごとにデータを整備することにしました。
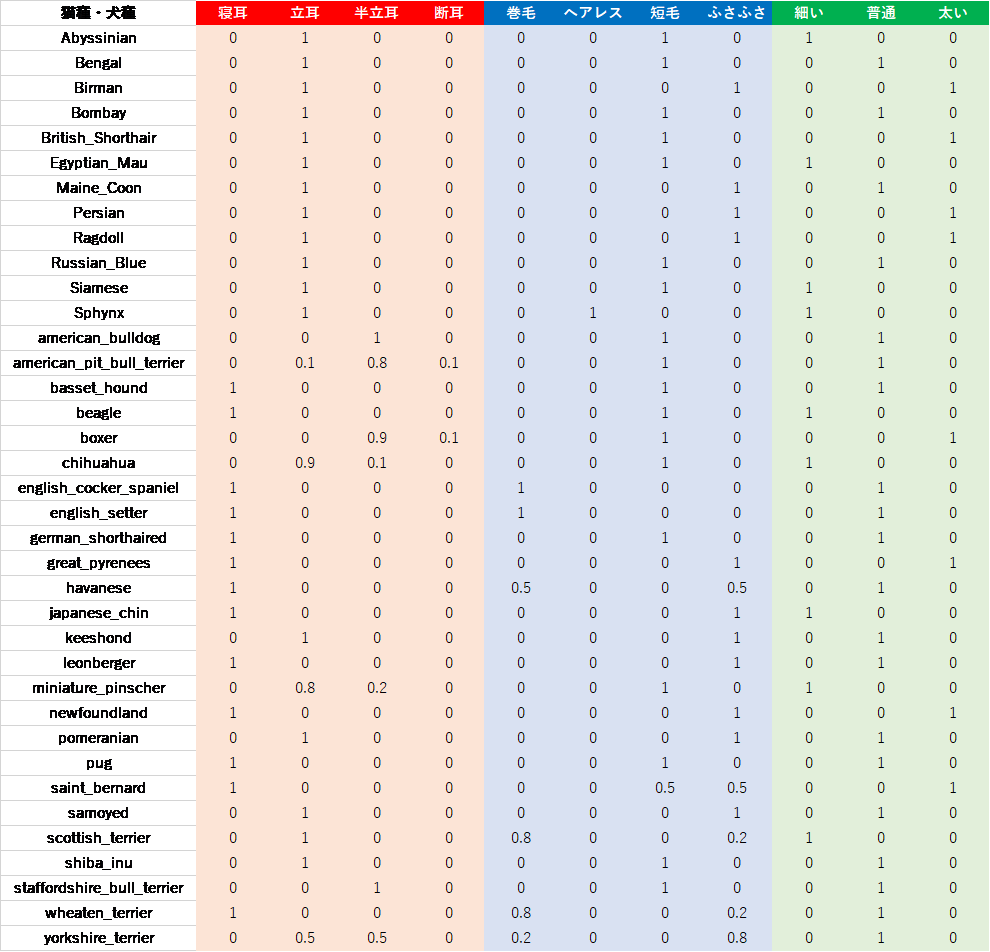
この表は以下のような手順で作成しました。まず、耳の形状、毛質、体形について、Training セットの画像をざっと確認し、だいたいこれくらいの種類がありそうだ、と洗い出し、列の項目を確定させました。その後、各品種に対して、各項目がどの程度含まれているのか主観で記載していきました。例えば、Abyssinian は Training セット中のどの画像でも耳が立っているから、「立耳」に1を記載し、american_pit_bull_terrier は、Training セット中の8割は耳の半分までが立っているが上半分が寝ている「半立耳」だが、「立耳」の画像や「断耳」されている画像も少数あるので、それぞれ0.1と記載しました。また、havanese の毛質は、「巻毛」と「ふさふさ」の中間かな、ということで0.5ずつを記載しています。
以上の説明から察していただけたかもしれませんが、ここに示している表は、完全に筆者の主観によって定められていることにご注意ください。より本格的に行うのであれば、各種ケネルクラブのスタンダードを定めた資料を元に追加データを作成する必要があるでしょう。
さて、ここからは実装を見ていきます。先ほどの図を再掲しましょう。
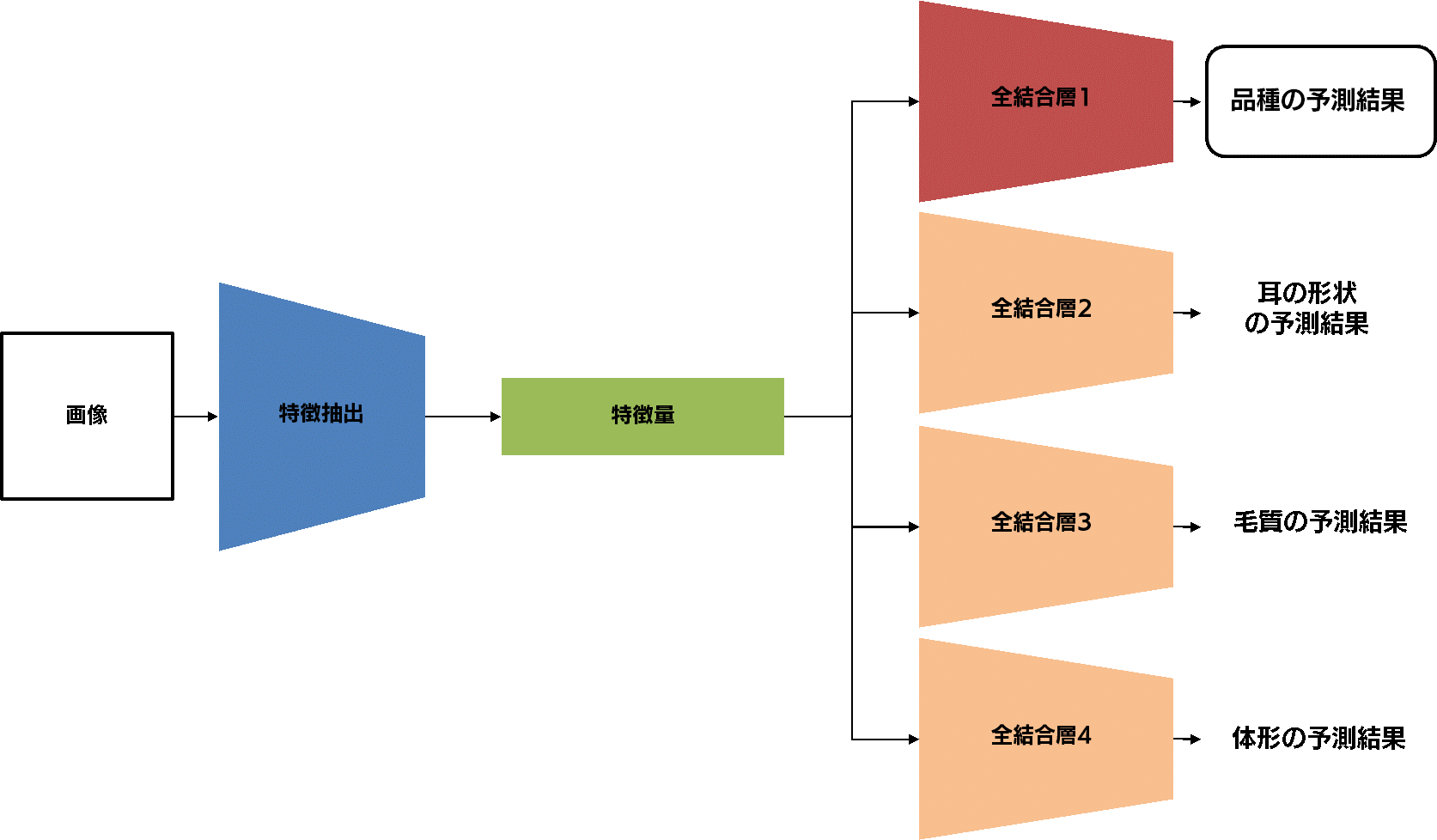
この図をそのまま実装してみましょう。 Notebook 中の MultiTaskModel の実装をご覧ください。PyTorch では、独自のモデルを構築する際には、torch.nn.Module を継承し、__init__ や forward をオーバーライドしたり、独自のメソッドを定義したりすることで記述していきます。特に注目していただきたいのは、__init__ と、独自に定義した predict メソッドです。__init__ はいわゆるコンストラクタで、その中で、今回構築するモデルの部品を定義しています。predict メソッドでは、複数枚の画像から成るミニバッチを入力とし、各部品を通して最終的な4つの予測値を得る処理を記載しています。上図の処理の流れと、predict メソッド内の処理が対応していることを確認出来たら次に進みましょう。
マルチタスク学習では、主タスクの損失であるクロスエントロピー損失(以下、CELoss)以外にも、補助タスクの損失も定義する必要があります。今回はバイナリクロスエントロピー損失(以下、BCELoss)を用いています。
補助タスクの損失がなぜ CELoss ではなく BCELoss なのか、気になるかもしれません。BCELoss は、通常2値分類のタスクに対して用いる損失で、ターゲットが0から1までの間の値をとるときに使用されます。今回の補助タスクは、何個かあるカテゴリの内の1つを予測するという一般的な多値分類タスクではなく、各カテゴリに割り当てられたスコアを予測する、というものです。各カテゴリに割り当てられたスコアは、0以上1以下の値であるという点で、一見すると確率のような値ですが、私の主観によってつけられた、なんの根拠もない数値です。そのため、このような主観的なスコアに対する損失関数として BCELoss が本当に適切なのか、私自身もっと研究しなくてはいけないわけですが、今回の記事では、差し当たってこの損失関数を使うことにしました。
さて、上記のように定義した各タスクに関する損失は、統合されて以下のようにまとめられます。この統合された損失関数は、Notebook 中の training 関数の真ん中付近で実装されています。
\(Loss_{all} = L_{clf} + \lambda_{ear} L_{ear} + \lambda_{hair} L_{hair} + \lambda_{fig} L_{fig}\)
式中にいくつか出現する \(\lambda_{xxx}\) は、その補助タスクをどの程度重視するか、という重みだと思って下さい。例えば、すべての重み \(\lambda_{xxx}\) が0ならば、この損失関数は品種の分類以外には興味が無いベースラインモデルと同一のものになりますし、\(\lambda_{hair}\) を10、その他を0にすれば、毛質を当てることを重視した損失だ、ということになります。
ここからは、このモデルを訓練し、Test セットに対する精度測定を行うのですが、その前に、以前の記事から何度か話題に挙げていたハイパーパラメータに関する説明を行います。その後、ハイパーパラメータチューニングの方法について説明し、得られたハイパーパラメータを示します。
ハイパーパラメータは、モデルの訓練の方法を指定するパラメータのことで、モデル内で使われる訓練対象となるパラメータと区別するために、「ハイパー」という修飾がつけられています。
ハイパーパラメータとして、例えば以下のものが挙げられます。
このように、様々な要素に対してハイパーパラメータが用意されています。モデルを適切に訓練するためには、これらのパラメータに対して、最適ではないにせよ、それなりに良い組合せを選ぶ必要があります。そのため、様々なハイパーパラメータの組合せを用意し、Training セットで訓練して、Validation セットで評価指標(例えば、分類精度)を算出する、という作業を繰り返しながら、よりよい組合せを探索することが求められます。
しかし、深層学習の訓練は1回に数時間~数週間かかることもあり、様々なハイパーパラメータの組合せについて網羅的探索して評価する、というのは非現実的です。今回のような比較的単純なモデルではあまり気にする必要が無いかもしれませんが、大規模なモデルになればなるほど、1回の訓練にかかる時間長くなってしまうため、ハイパーパラメータチューニングにかかる時間が非常に長くなってしまいます。
ではどのようにハイパーパラメータをチューニングするのか、私が採用している4つの手順をお伝えします。
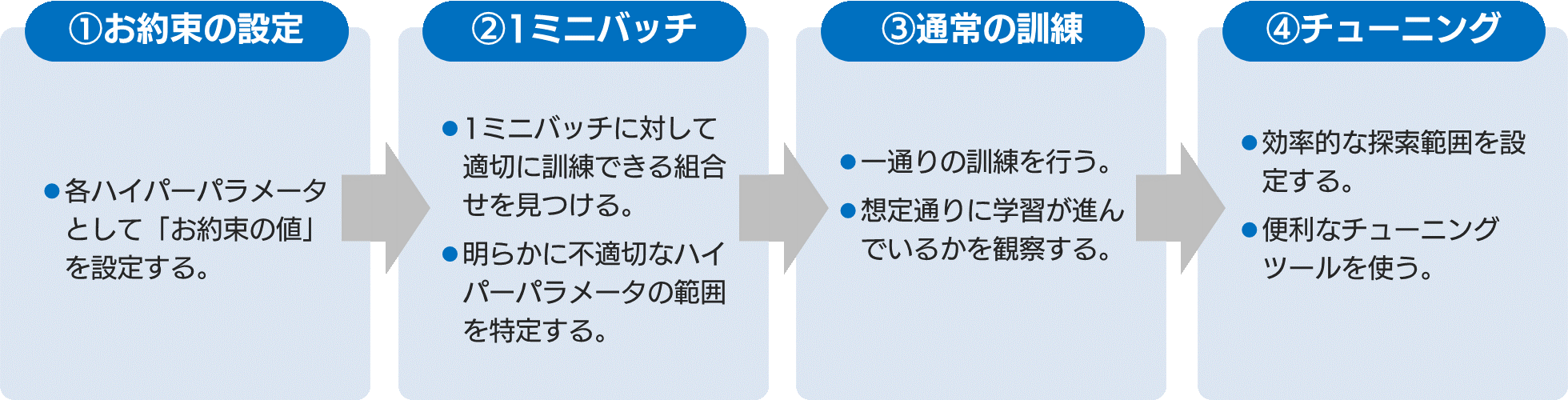
以上のように、ハイパーパラメータのチューニングは、ある程度経験則が必要なうえ、時間もかかる、大変な作業です。
今回は、シンプルに各補助タスクの重み(\(\lambda_{ear}, \lambda_{hair}, \lambda_{hair}\))のみをチューニングし、その他のハイパーパラメータはベースラインモデルにそろえる、ということにしておきます。ツールは、手元の PC にインストールされていた、Ax (Adaptive Experimentation Platform) を使用しました。探索範囲はいずれも、0.0~2.0の範囲とし、50通りのハイパーパラメータの組合せを探索しました。このチューニングの結果、\(\lambda_{ear}=1.7\)、\(\lambda_{hair}=0.48\)、\(\lambda_{fig}=0.25\) という各損失の重みを得ることができました。
なお今回、ハイパーパラメータチューニングに関する処理は、Notebook には記載していません。先ほど紹介したツールを使って、ぜひご自身の手で試してみてください。
さて、以上のようにチューニングした結果を用いて、モデルの訓練を行い、Validation セットと Test セットを使って分類精度を評価してみました。Notebook で実行していただければわかりますが、精度は多少ばらつきますが、おおむね Validation セットに対する分類精度も Test セットに対する分類精度も、ベースラインよりは向上するのではないかと思います。
なお、本当に今回の工夫が有効なのかを確認するために、私の手元の環境で10回ほど実験し、各精度の平均と標準偏差を算出しました。ちなみに、最も Validation 精度が良かったモデルは、Validation 精度が92.58%、Test 精度が92.57%となりました。
左右にスクロールしてご覧ください。
| \(\lambda_{ear}\) | \(\lambda_{hair}\) | \(\lambda_{fig}\) | Validation 精度 | Test 精度 | |
|---|---|---|---|---|---|
| ベースライン | 0 | 0 | 0 | 91.6 | 92.1 |
| マルチタスクモデル | 1.7 | 0.48 | 0.25 | 91.92±0.34 | 92.35±0.23 |
よし、マルチタスクモデルでベースラインを上回る分類モデルを構築できたぞ!と手放しに喜んでしまっていいものでしょうか。Test 精度の0.25%の精度向上は、1カテゴリあたり Test データが約3600枚あるということを前提にすると、約9枚分に相当します。これだけ苦労して9枚分しか改善できていないとしたら、なんだか複雑な気持ちになりますよね。
本連載では、特に具体的な目標は設定していませんが、実際のモデル構築・改善の業務では、評価指標を改善したときに得られるビジネス上のインパクトを考慮したうえで、目標精度を定める、というプロセスが必要になります。今回改善できた0.25%という値が、ビジネス上大きなインパクトを持つのであればそれは成功と言えるでしょうし、ほとんどインパクトをもたらさないのであれば失敗と言うべきでしょう。
マルチタスクモデルによって、どのような事例がうまく分類できるようになったのか確認してみましょう。ここでは、最も Validation 精度が良かったモデル(Validation 精度: 92.58%, Test 精度: 92.57%)で、確認していきます。特に、今回のモデルの特徴である、マルチタスク学習がどのように影響しているのかを重点的に見ていきます。
まずは Validation セットに対する混同行列を確認してみましょう。以下が今回得られたモデルの混同行列です。パッと見たところ、前回とあまり変わらないように見えますが、Validation 精度は1%程度改善しているので、実はいろいろと変わっています。
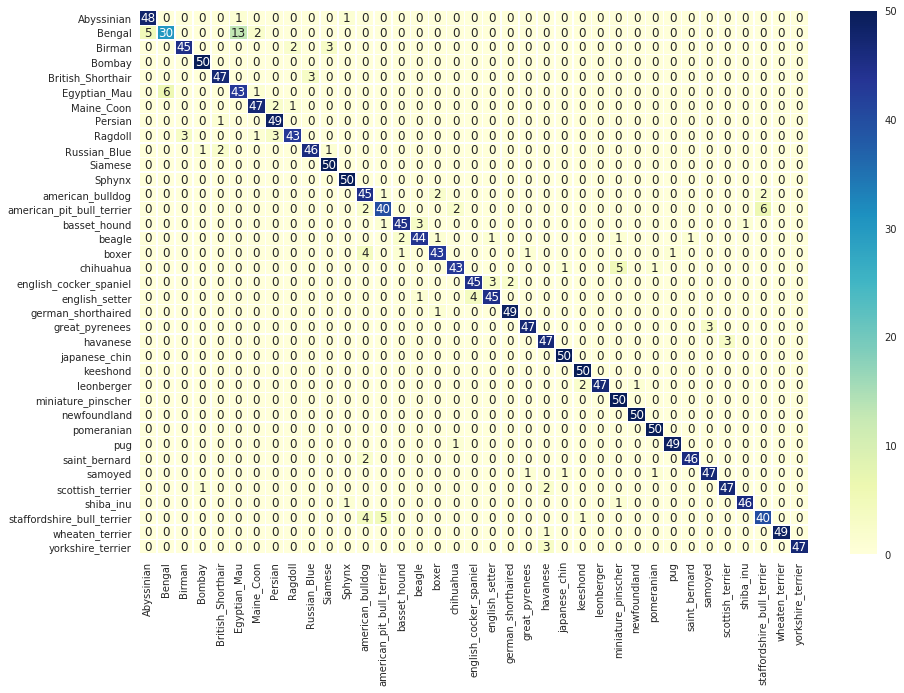
前回、american_pit_bull_terrier と staffordshire_bull_terrier を見分けるポイントとして、american_pit_bull_terrier は断耳されることも多いため、耳の形状によって見分けられるのかもしれない、という仮説を立てていました。ただし、すべてのピットブルテリアが断耳するわけではないため、american_pit_bull_terrier は「立耳」「半立耳」「断耳」をそれぞれ0.1, 0.8, 0.1というスコアにしておきました。staffordshire_bull_terrierは「半立耳」に1.0というスコアを入れています。今回のモデルでは、ベースラインモデルと比べて、2犬種の混同は18件から19件となり、ほとんど変化なし、という結果となりました。
今回の苦肉の策である、品種ごとのスコア付けという追加情報が、あまり機能しなかったという可能性があります。断耳と半立耳の見た目はだいぶ異なるため、これをうまく反映させれば、この2犬種の混同はもう少し改善できる気がします。
British_Shorthair と Russian_Blue は色合いが似ているために間違えやすいと思われる2つの猫種ですが、体形が見分けるポイントである、ということを前回示しました。今回の追加情報では、British_Shorthair は「太い」にしており、Russian_Blue は「普通」にしました。
ベースラインモデルでは合計10件の混同が見られていたのですが、今回のモデルでは、5件にまで抑えられています。誤分類が半減した、と言えば聞こえはいいですが、もともとの数がそこまで多くないこともあって、本当に補助タスクが功を奏したと断言していいのかは難しいところです。
english_cocker_spaniel と english_setter は、目の前に存在していれば大きさが異なるので見分けが着くのですが、画像では確かに見分けが難しい犬種です。english_setter の方は、毛皮がまだら模様になっていることが多いので、毛皮にもっと注目したモデルが作れれば良いのでは、という仮説を前回立てていました。今回は毛皮の模様や色を予測するという補助タスクは採用せず、「巻毛」「ヘアレス」「短毛」「ふさふさ」といった毛質に関わる補助タスクを採用しています。毛質を分類する補助タスクを設けることによって、毛皮の模様や色の情報もある程度 CNN によって抽出されることを期待していました。
この2犬種では、ベースラインモデルでは13件あった混同は、7件にまで減少しました。こちらも、混同が半減しています。
マルチタスク学習では、追加データの整備、モデルの変更、ハイパーパラメータの増加によるチューニング作業、といったコストが発生しますが、この労力に見合った精度向上が得られるかというと、「やってみないとわからない」というのが現実です。 特に追加データの整備は非常に時間がかかることがあります。そのため、今回のように、カテゴリと補助タスク用の教師信号がある程度連動しているような場合は、まずカテゴリごとにざっくりとした追加データを作ってみて、うまくいく予感がしたら、本気を出して追加でデータを整備してみる、といった手順が有効かと思います。今回の実験で、私自身も、少しうまくいきそうな気がしたので、改めてデータ整備を行ったうえで、再実験をしてみようと思います。
実は、今回の実験は、一枚一枚の画像に追加データを整備できなかったこともあって私自身ドキドキしながら行っておりました。今回の工夫によって明確な精度向上が見られた、と断言するにはなかなか難しい改善しか得られなかったのは残念でしたが、実際のモデル構築業務も、こういう改善と言えるか言えないか微妙なラインの結果に終わるということは、よくあることです。より厳密な改善の有無を示すことが必要な場合、統計的な仮説検定を行うことで改善案の有効性を判断するということが必要になることもあるでしょう。
次回はまた少し異なる観点から、モデルの改善を試みます。それでは、また次回!




