前編 に続き、次は犬種を見ていきましょう。
アメリカン・ピット・ブル・テリアとスタッフォードシャー・ブル・テリアは、血統的に極めて近い犬種です。

スタッフォードシャー・ブル・テリアはもともと闘犬として、ブルドッグや各種テリアを交配し作出された犬種です。しかし1920年代には闘犬としての利用を止められ、やや軽量で温厚な性格に改良されました。こちらは American Kennel Club に正式な犬種として登録されています。そのため、犬種が満たすべき特徴が「標準(スタンダード)」として定められています。例えば、本犬種の色に関するスタンダードでは、ブラック&タンやレバー(赤みがかった茶色)は認められていません。
一方で、アメリカン・ピット・ブル・テリアは、スタッフォードシャー・ブル・テリアの闘犬らしい力強さを温存することを目的に作出されています。また、闘犬としての慣習も残っており、断耳されることもあるようです。こちらは、闘犬としての性格が色濃いため、American Kennel Club には登録されておらず、スタンダードが存在しません。イギリスの United Kennel Club では登録されており、そちらではスタンダードが定められていますが、スタッフォードシャー・ブル・テリアのような色に関する制約はありません。
さて、これら二つの犬種を見分けるポイントですが、いろいろ調べてみたのですが、残念ながら確実に見分けることのできる点はなさそうです。ピット・ブルは闘犬だから怖い顔をしているはずだ、と思われるかもしれませんが、そんなこともありません。
見た目で分かる範囲では、色のスタンダードの違いを何とか有効活用できないか、ということが考えられます。また、ピット・ブルの方は断耳されている可能性もあります。これらの差異をモデルがうまく学習できれば、決定的とまではいきませんが、一部の個体の予測については改善できるかもしれません。
この二つの犬種も、今回のデータセットの難所と言えるでしょう。

イングリッシュ・コッカー・スパニエルとイングリッシュ・セターはあまり近い犬種ではありません。血統的にも遠いですし、大きさもだいぶ違います。では、なぜ大きな混同が起きてしまっていたのでしょうか?

実は、english_cocker_spaniel/english_setter の誤分類は、すべて同じ個体の写真でした。子犬であることから、コッカー・スパニエルの特徴の一つである耳周り巻き毛や胴体の毛がまだ伸び切っていないことが誤分類の原因である可能性があります。参考までに、コッカー・スパニエルの成犬の画像を以下に示します。同じ犬種とは思えないほど、子犬と成犬では特徴が異なっていることがわかります。

一方で、english_setter/english_cocker_spaniel の方はどうでしょうか? いずれの例も特徴的なブチ模様の顔や胴体が見られるので、イングリッシュ・コッカー・スパニエルと誤認するとは考えにくいです。こういう時は、画像分類モデルが画像中のどこを根拠に分類を行っているかを確認してみましょう。
以下のイングリッシュ・セターの画像をご覧ください。

簡単に見方を説明しましょう。2枚の画像の上部に書いてあるカテゴリ名と数値は、english_setter である確率を32.9%、english_coker_spaniel である確率を61.0%と予測した、ということを表しています。どちらのカテゴリもそれなりに高い確率になっており、「english_setter と english_coker_spaniel の間で迷ったけれど、english_coker_spaniel にした」というニュアンスがくみ取れると思います。
2枚の画像中には、それぞれのカテゴリに対する予測根拠を示されています。まずは確率の高い、つまり最終的に予測結果として出力された english_coker_spaniel の方を確認しましょう。緑色のハイライトされている部分がありますが、これが予測根拠となった個所となります。この例では、耳の広い範囲が予測根拠とされており、耳の巻き毛が比較的強い個体だったがために、english_cocker_spaniel として誤分類されてしまったのだ、と解釈できます。
一方で、english_setter の方の予測根拠は、耳の内側と鼻梁付近に予測根拠が集まっていますが、胴体には予測根拠が全く見られません。そのため、イングリッシュ・セターの特徴的な胴体のブチ模様が予測根拠として使われていないのではないか、と解釈ができます。
実は、この画像に関する予測根拠を Grad CAM で見てみると、これとは少し異なる予測根拠が確認できます。以下にその比較を示します。

english_setter の予測根拠は、english_cocker_spaniel の根拠とそんなに変わらないようにも見えますが、やや、english_setter の根拠の方が胴体に対して広がりがあることから、多少は胴体の模様も反映しているのだ、と解釈できます。そのため前回構築したモデルは、english_setter のブチ模様を学んではいるが、学び方が不十分なのではないか、という解釈もできます。
もう一枚、別の画像も確認してみましょう。

こちらの画像も2種類の犬種で迷った挙句間違えているようです。しかし、予測根拠の画像を確認してみても、いったいどこに予測根拠があるのか分かりません。よくよく見ると、実は、どちらのカテゴリの予測根拠も目の部分にわずかに示されています。ただ、この結果が納得できるものかというと少々疑問です。
Grad CAM の方も見てみましょう。

こちらは、先ほどのように「予測根拠が見えない」、ということは無いのですが、どちらのカテゴリに対してもほとんど見分けがつかない結果が表示されてしまいます。エンドユーザ向けにこういった予測根拠を見せてしまうと、「使えない」という印象を与えてしまうかもしれませんね。
このように、予測根拠の可視化は、必ずしも明確な示唆を提示してくれるわけではありません。今回は、モデルを構築する人間が、改善のためのアイディアを得るために行っているので問題はありませんが、エンドユーザに対して提示する場合は、注意が必要です。
予測根拠の可視手法は未成熟な部分があります。一つの手法で完璧に予測根拠を説明できるとは思わないほうが良いでしょう。例えば、Grad CAM は Smooth Grad に比べると、予測根拠が見やすい形で表示されるのですが、解像度が低く、根拠として示される領域が曖昧になってしまうという欠点があります。また、複数の手法の間で相容れない解釈が成立してしまうこともあります。
以上のように、予測根拠の可視化は解釈がなかなか難しい面もあります。いずれにせよ、english_setter のブチ模様が十分に学習できていないのではないか、という解釈を得ることができました。ここから、毛の模様をモデルに十分に学習させると精度が改善するのではないか、という改善案が得られました。
最後に、そもそも犬か猫か、という基本的な大分類すら間違ってしまっている、という3枚の例を紹介します。
一つ目は Ragdoll/samoyed という例です。ラグドールもサモエドも白いもふもふの毛が特徴的ですので、予測根拠もおおむね同じ部分に示されています。かなり迷った挙句 samoyed と予測しており、他にはこのような例が無いため、例外的な画像であると言えるでしょう。

二つ目は scottish_terrier/Bombay という例です。真っ黒な体は確かにボンベイと捉えられても仕方がないですが、寝転がっているため、顔が良くわかりませんね。また、子犬であることから、犬種特有の顔立ちがまだ見えていない、というのが誤分類に影響していそうです。
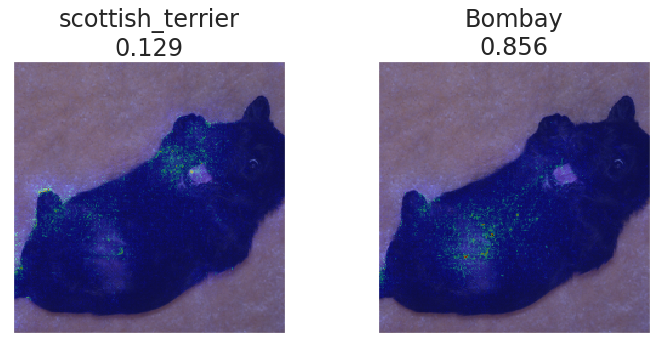
成犬は以下の画像のように、顔周りのボリュームのある毛が特徴的です。

最後は、shiba_inu/Sphynx という例です。
画像を確認してみましょう。この画像はそもそも変わった構図になっており、端っこに犬がいます。Validation セットに対しては、CenterCrop という、画像の中央で切り取る前処理を行っていたのでした(切り取る範囲は、画像の赤点線で囲まれた部分)。これは、複数枚の画像を用いてミニバッチを作成する際に必要な前処理なのですが、1枚1枚の画像を予測する場合は、モデルによっては、切り取らずにそのままモデルに入力することも可能です。
ちなみに、本画像は、画像全体をモデルに入力しても「Sphynx」と予測され、右端で切り抜いた部分画像を入力したときは「shiba_inu」と予測されます。この例は極端な例ではありますが、評価対象の画像に加える前処理も、今後の検討材料にするべきでしょう。

ところで、今回の誤分類の画像を確認していく中で、Validation セット中に以下の4枚のような「データセットの不備」と呼ぶべき問題が見られました。
まず、shiba_inu、つまり柴犬のカテゴリに以下の2枚の画像が含まれていました。

明らかに柴犬ではない、この犬種は何でしょうか? おそらくですが、オーストラリアン・シェパードではないかと考えられます。前回構築したモデルは、saint_bernard と予測していました。なお、オーストラリアン・シェパードは、今回のデータセットではカテゴリに含まれていません。
続けて、saint_bernard、つまりセント・バーナードに以下の2枚の画像が含まれていました。

少し怖いように見えて味のある顔立ちをしているこの犬は、セント・バーナードではなく、ボクサーですね。前回構築したモデルも boxer と分類しています。
以上のような不適切な例は、もしかしたら、Train セットや Test セットにも含まれているかもしれません。しかし、前回までの評価の基準と今後の評価の基準を合わせたいので、今後は Validation セットのみから取り除くことにします。
誤分類の事例を見てきた中で、以下のような、モデル改善のアイディアが出てきました。
一方で、特に以下の3つの分類については、人が見てもわからず、ちょっと難しそうだぞ、ということを確認しておきましょう。
その他に得られた知見としては、「大きい小さいという情報を画像分類に活かすのは難しいかもしれない」「子犬の分類は、成犬の特徴が表れていないので難しい」「画像の端に分類の対象物がいることがあるため、対策すれば精度が挙げられそうだ」といったことが挙げられると思います。
今後は、今回得られたアイディアをできるだけ反映できるようなモデルを構築していきます。もちろん、それだけでなく、より一般的な改善の手法も試して行く予定です。
「深層学習の教材だと思って読み始めたら、犬猫講座だった!」そんな声が聞こえてきそうです。
ですが、データ分析において、このようなデータの背後にある現実を知るのは、とても大切なことです。
実際のデータ分析の仕事でも、このようにデータと現実がどのような対応関係にあるのかを確認しながら、モデルの改善案を出していきます。データ分析はともすれば孤独で無味乾燥な作業になりがちです。
データの背後に存在する現実と良く親しみ、楽しみながらデータを分析できることを目指しましょう。
それでは、また次回!
関連ページ
深層学習入門:画像分類モデルを作ろう(1) |




