こんにちは、データサイエンスチームの白石です。
前回 は、「画像分類モデルの構築」の初回として、データセットの紹介と、モデル構築のプロセスを紹介しました。前回に引き続き、「画像分類モデルの構築」を進めていきましょう。
今回は、画像分類モデルの構築の最初のステップである、「ベースラインモデルの構築」についてお話していきます。
もしかしたら、今回の記事は新しいことだらけで、全然わからない、そう思われる方もいらっしゃるかもしれません。深層学習の世界は、情報工学、数学、確率論、情報理論等が入り混じっている高度な技術領域ですので、全体を構成している要素すべてについていきなり理解するのは極めて困難です。初学者にとって敷居が高く感じられるのは当然です。
私がお勧めするのは、まずは全体を真似してみて、そのあと気になる部分を深堀して理解する、というプロセスを繰り返すことです。なので、まずは記事中で公開している実装を、「おまじない」だと思ってコピペしてみましょう。そして、細かいパラメータをいじりながら、何が起きるかを観察してみましょう。そのうちに、「どうもこの部分をこのように修正するとこういう結果になるようだ」と徐々にわかってきます。ある程度分かったタイミングで、本記事のような内容に戻ってきたり、参考書を読んだりすると、理解が進むことでしょう。
前置きが長くなってしまいました。
それでは本題の方を始めましょう。
「機械学習導入支援サービス」に関する資料請求・お問い合わせはこちら
改めてですが、ベースラインモデルとは何でしょうか?
ベースラインモデルとは、新しくモデルを作ろうとする前に作成しておく、乗り越えるべき壁となるモデルです。一般的には、汎用的な手法で構築されます。
前回の記事では、ベースラインモデルを Custom Vision などの Web サービスを使って構築する方法と、学習済みモデルをチューニングする方法であるファインチューニングをご紹介しました。
今回の連載では、最終的には自分でモデルを改良していく試行錯誤をできるようになることを目標にしていくため、ファインチューニングによってベースラインモデルを構築してみましょう。
ファインチューニングについても、改めて説明しておきましょう。
ファインチューニングとは、定番のアーキテクチャを使った学習済みモデルをもとに、一部を自分たちの目的に応じて修正し、自分たちのデータで再訓練することです。
一般に公開されている多くの学習済み画像認識モデルは、ImageNet(ILSVRC2012) 等の大規模なデータセットで訓練されています。このような学習済みモデルは、1000ものカテゴリをかなりの精度で分類することができます。
例えば、ResNet-34 という著名なアーキテクチャを使用し、ImageNet で学習した学習済みモデルの例を示します。下図の上のパグの画像ですが、この画像をこの学習済みモデルに入力すると、ちゃんと pug と分類されます。一方で、下図の下のハバニーズの画像は、Tibetan_terrier(チベタン・テリア)と分類されます。これは ImageNet にはハバニーズに該当するカテゴリが用意されていないためです。しかし、ハバニーズとチベタン・テリアは比較的よく似た見た目をしている犬種です(画像を検索してみてください!)ので、納得感はあります。
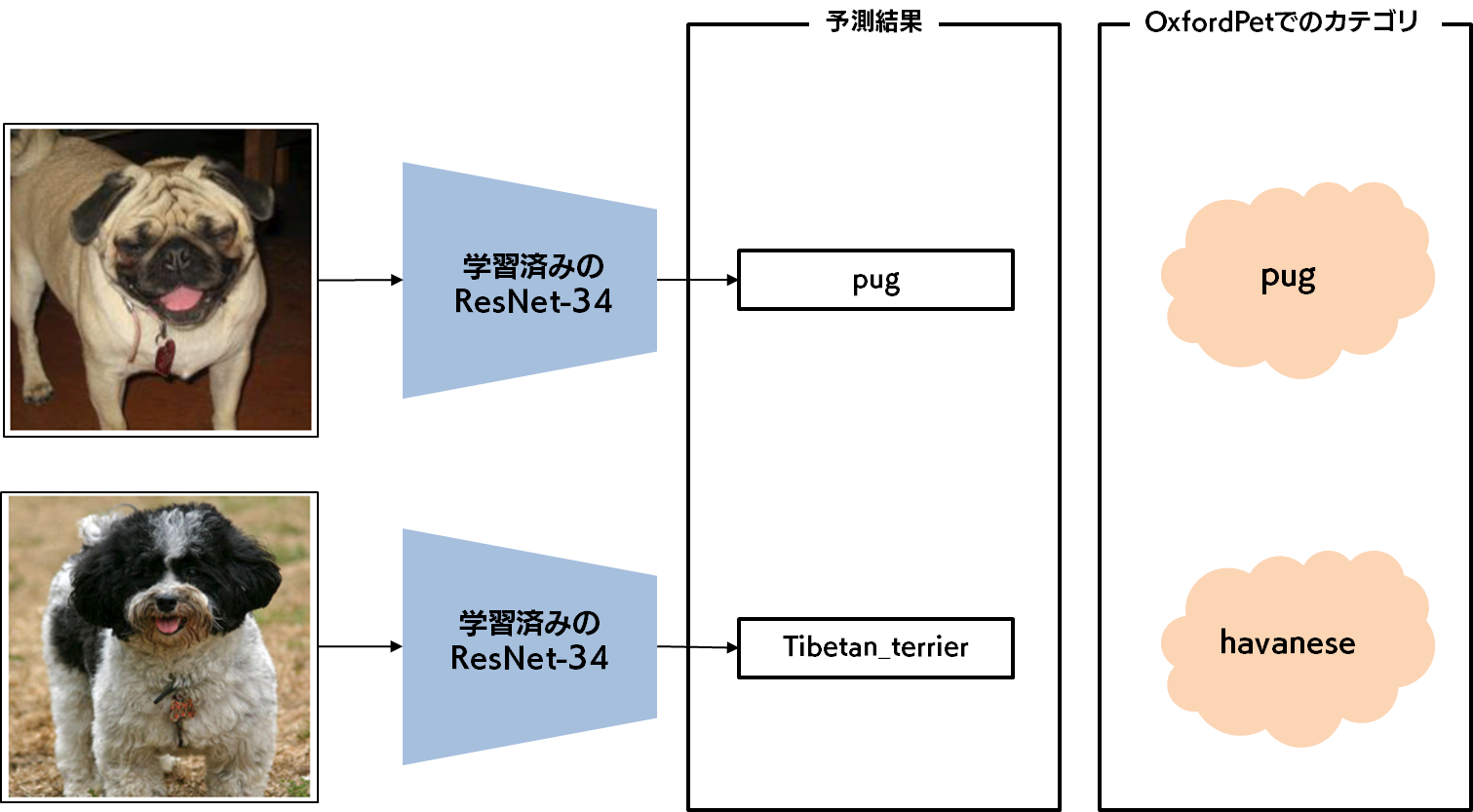
しかし、いくら納得感のある分類結果が得られるからといって、学習済みモデルをそのまま使用することはできません。今回私たちが構築したい画像分類モデルは、Oxford-IIIT Pet Dataset(以下、OxfordPet と呼びます)に含まれる37種の犬種・猫種を分類することを目的としているからです。37種のカテゴリの一部は、ImageNet にも存在しますが、多くのカテゴリは、ImageNet には存在しないカテゴリです。
では、目的のカテゴリに応じた分類モデルを構築するには、どうすれば良いのでしょうか?以下に示す一般的な画像分類モデルのアーキテクチャをもとに説明します。
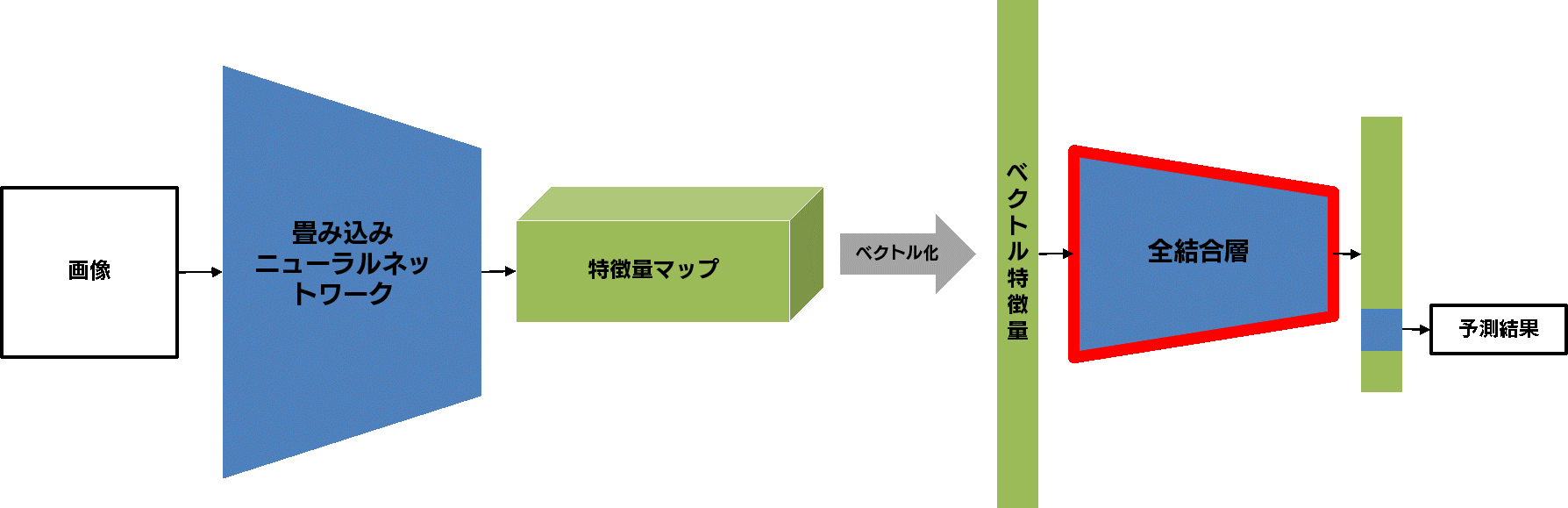
まずは情報の流れを確認しましょう。左側から画像が入力されています。入力された画像は、「畳み込みニューラルネットワーク」によって、特徴量マップと呼ばれる「画像の本質的な情報」へと変換されます。この特徴量マップは簡単な加工によってベクトル特徴量に変換されます。ベクトル特徴量は「全結合層」と呼ばれる比較的単純な分類器に入力され、予測結果が出力されます。
この図のうち、訓練が必要なのは「畳み込みニューラルネットワーク」と「全結合層」の部分です。ファインチューニングでは、「畳み込みニューラルネットワーク」の訓練は、ほぼ終わっている、とみなします。というのも、「畳み込みニューラルネットワーク」の部分は、大規模なデータセットで訓練された、優秀な「特徴量抽出器」であると言えるからです。一方で、「全結合層」は、自分たちの目的とする分類器のカテゴリ数と種類に合わせる必要があります。
そのため、学習済みモデルのファインチューニングを行う際には、「全結合層」の部分を自分たちの目的に応じて再定義してから臨むことになります。
「機械学習導入支援サービス」に関する資料請求・お問い合わせはこちら
さて、ここからは実際の実装に入っていきます。
学習済みモデルをファインチューニングし、自分たちの目的に合ったモデルを構築していきましょう。
深層学習には様々なフレームワーク(Tensorflow, Keras, fast.ai, Chainer, MXNet 等)がありますが、この連載では、Facebook 製の PyTorch、および torchvision を用いていきます。
今回の内容は、PyTorch のチュートリアル記事である、Finetuning Torchvision Models と範囲的に重なる部分も多いため、興味のある方はこちらもご覧になると良いでしょう。
ファインチューニングは、以下のようなステップを踏むことで実現できます。
実際の構築手順に入る前に、環境の準備について説明しておきます。この記事内では、先ほどご紹介した構築手順の概念を説明するに留めています。Google Colaboratory に Jupyter Notebook を公開していますので、具体的な実装が知りたい方は、適宜そちらをご覧ください。
Google Colaboratory は、Google が公開している Jupyter Notebook の実行環境です。一切の環境構築設定が不要で、無料で利用することができます。深層学習のモデル構築に欠かせない GPU 環境が手軽に用意できるサービスです。また、Jupyter Notebook とは、データ分析や機械学習でよく利用されるドキュメント形式で、実際に動かせるソースコードと、テキストや画像などを単一のファイルにまとめることができるため、分析プロセスの共有や講座資料として用いられています。
Google Colaboratory に公開している Notebook は誰でも閲覧できますが、実行のためには Google アカウントまたは G Suite アカウントでのログインが必要です。こういった外部サービスの利用は、会社のルールで定められてるかと思いますので、社内ネットワークから閲覧されている方は、社内のルールを確認することをお勧めします。
以上のことを確認された方は、リンク先の Notebook をご覧ください。なお、詳細な利用方法につきましては、この記事の中では説明は行いませんので、公式のガイド などをご参照ください。
まず、データセットの定義を行います。今回は torchvision の便利な機能である ImageFolder を用いてデータセットを定義します。また、関連の深いバリデーション戦略とデータ拡張についても説明します。
画像分類におけるデータセットとは、画像とカテゴリの組のことを指します。これは、例えば以下の表のように、画像とカテゴリ名をまとめた表として表すことができます。この表を読み取って、データセットとして扱うこともできます。

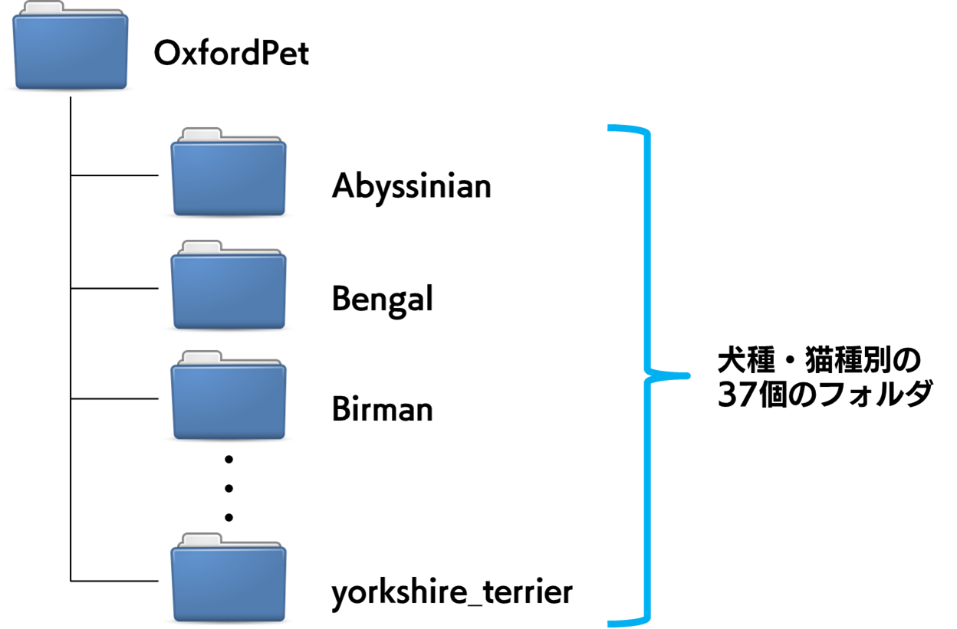
しかし、このような表を用意しなくても、torchvision には ImageFolder という特定のフォルダ構造に画像を格納してさえいれば、そのままデータセットとして扱うことのできる便利な機能が備わっています。
例えば、OxfordPet データセットでは、以下のようなフォルダ構成で画像を格納しておき、ImageFolder を適用すると、PyTorch 内で使いやすい形式である Dataset オブジェクトを作成してくれます。
深層学習に限らず、機械学習モデルの訓練一般で重要になるのが、バリデーション戦略です。バリデーション戦略とは、分類モデルが適切に汎化されているかを確認するための戦略を指します。
汎化とは、訓練したモデルが未知のデータ、つまり教師データに含まれない様々な画像に対しても、それなりの精度で分類できるものになっている、という状態を表す言葉です。訓練に使用したデータをどれだけ上手に分類できるようになったとしても、未知の新しいデータに対してそれなりに上手く分類できなければ、その分類モデルは無価値なのだ、ということをよく理解しておいてください。
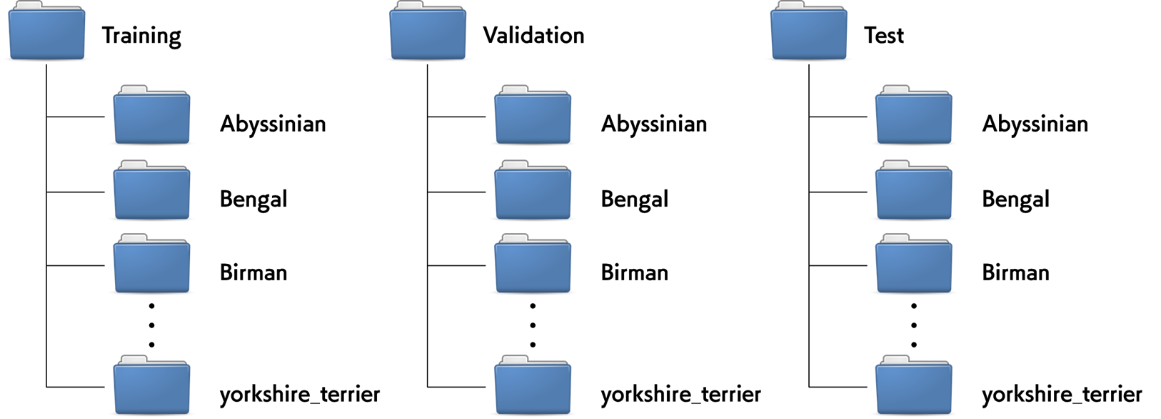
モデルに汎化性能を持たせるためには、データセットを以下のような3つのグループに分割し、それぞれを適切に用いる必要があります。これら3つのグループを用意しておくことが、深層学習における最も標準的なバリデーション戦略です。
ハイパーパラメータという言葉が出てきました。これは重要概念なのですが、解説は次回以降に持ち越しましょう。
今回は、以下のような3つのフォルダを作成し、それぞれに37カテゴリのフォルダがさらにある、という形でファイルを整理しました。Training、Validation、Test それぞれのフォルダは、各カテゴリにつき50枚、50枚、約100枚という割合で分割して画像が格納されています。
Training セットに対して行うデータ拡張を定義しましょう。データ拡張とは、先ほども登場した、モデルの汎化性能を上げるための工夫の一つです。データ拡張の一例として以下のようなものがあります。
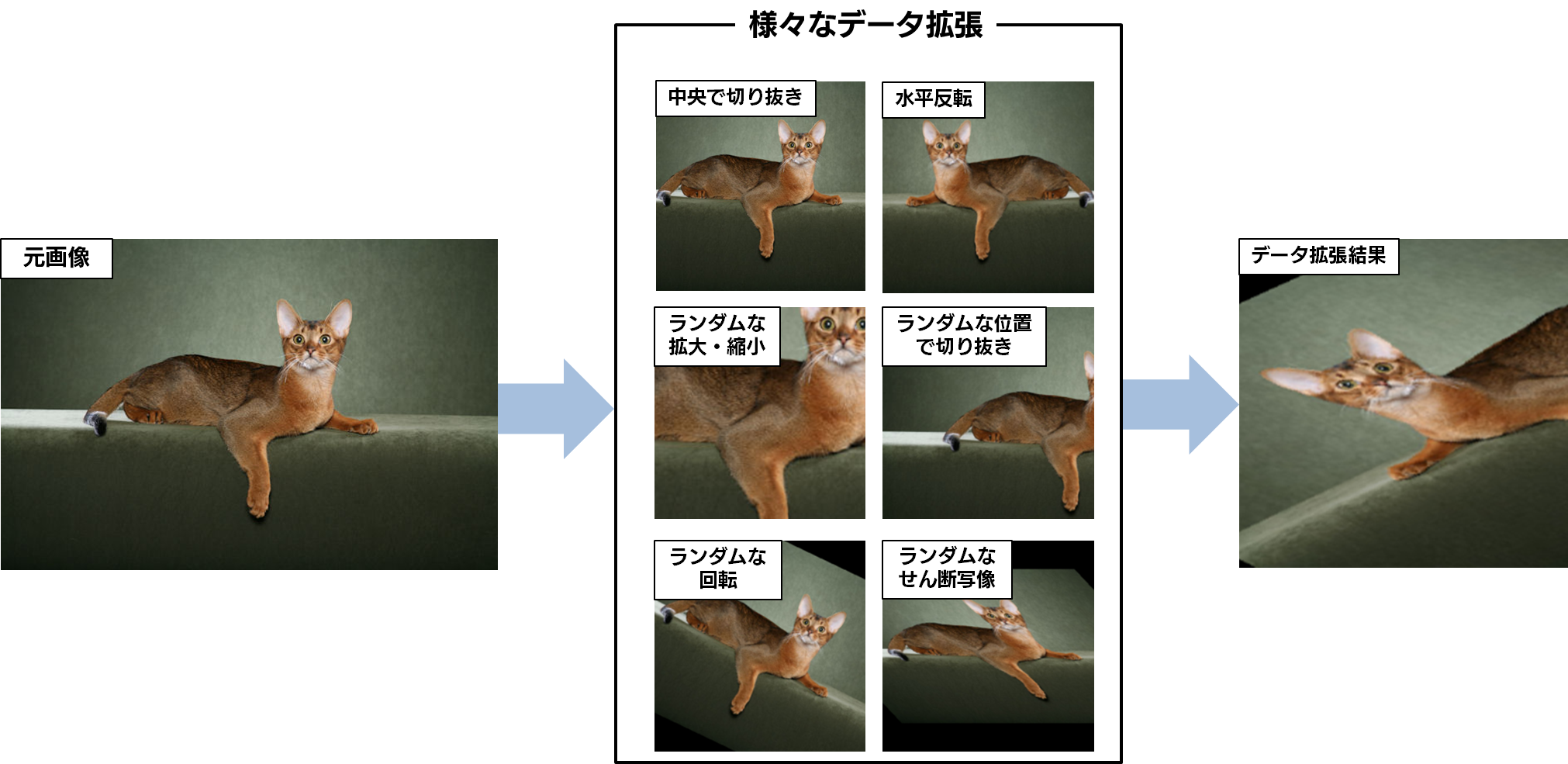
このような処理を学習に使用する画像に加えることで、数少ない Training セットの画像を水増ししてやろう、というわけです。 今回は PyTorch の公式チュートリアル通りのシンプルなデータ拡張を行っており、具体的には、ランダムな拡大・縮小とランダムな位置での切抜きを組み合わせた RandomResizedCrop と、ランダムな水平反転である RandomHorizontalFlip を適用します。
学習済みの ResNet-34 の全結合層を独自のものに入れ替えて、モデルを定義しましょう。
いきなり出てきた ResNet-34 とは何でしょうか? これは ResNet という著名な画像認識のアーキテクチャのバリエーションの一つなのですが、詳細については、今後の機会に持ち越しましょう。torvhvision の models を参照すると、様々な画像認識の定番アーキテクチャと、その学習済みモデルを得ることができます。
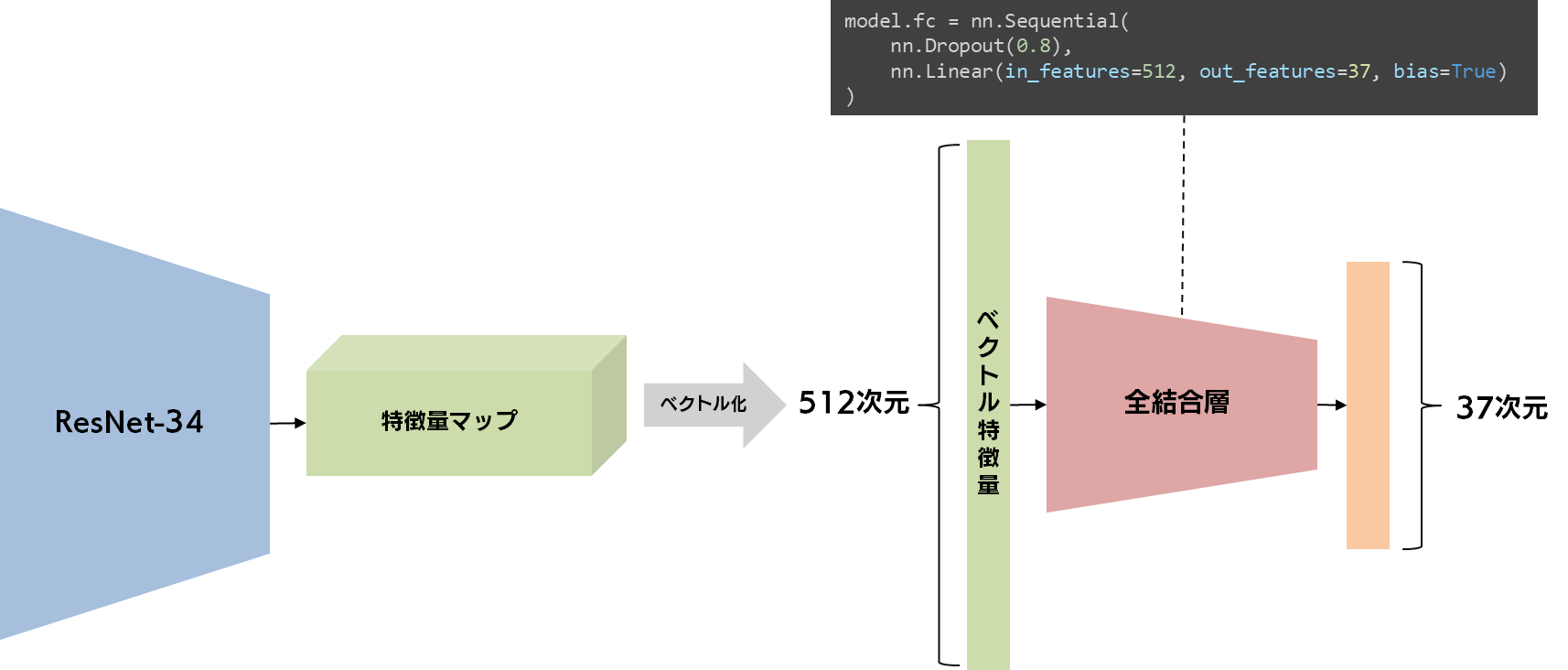
ResNet-34 は、入力された画像を512次元のベクトル特徴量へと加工しますが、ここまでの処理はあまり変更せずにそのまま活用したい部分です。私たちが修正しなければならないのは、全結合層の部分を、512次元のベクトル特徴量をもとに37カテゴリの分類ができる、別の全結合層に書き換えてあげることです。
具体的には、学習済みモデルの属性である fc(fully-connected、全結合)を自分たちの目的である、37カテゴリの予測を行うための Sequential モジュールに書き換えてあげましょう。この内部では、ドロップアウトという、これまた汎化性能を上げるためのモジュールと、線形結合層が含まれています。これによって、元の1000カテゴリの分類器から、37カテゴリの分類器に修正することができました。
深層学習のモデルは、損失と呼ばれるネガティブな意味を持つ数値を、できるだけ小さくすることを目標にして訓練されます。その損失の計算方法を定義するものが、損失関数です。損失関数の直感的なイメージとしては、現在のモデルのパラメータや出力結果がどれだけ望ましくないのか、という度合いを計算するものだ、と考えておけば良いでしょう。
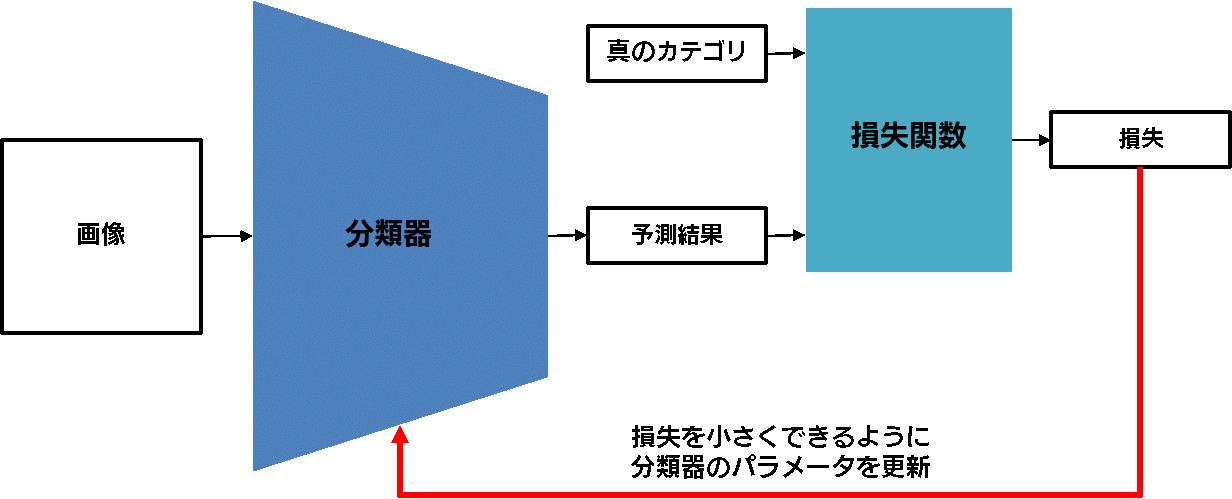
具体的には、画像分類のような分類問題では、損失関数としてクロスエントロピーという指標が用いられます。クロスエントロピーは、分類器の予測カテゴリと真のカテゴリを比較し、予測が外れていたら大きくなるような指標です。
今回は画像分類のモデルを構築していますので、シンプルにクロスエントロピーを用いています。クロスエントロピーのような定番の損失関数以外にも特殊な損失関数が存在しますが、こういった特殊な損失関数については、この連載の別の回で見ていくことになるでしょう。
先ほど、損失をできるだけ小さくできるようにモデルのパラメータを更新する、と言いましたが、その具体的な処理を行ってくれるのが、オプティマイザです。オプティマイザ(Optimizer)は、その名前の通り、「モデルのパラメータを損失ができるだけ小さくなるように最適化する(=Optimize)」という役割を担っています。
一般的に、オプティマイザというと、いわゆる最適化アルゴリズムのことを指すことも多いですが、この記事では、下記に説明する、最適化アルゴリズムや早期打ち切り、学習率のスケジューリングなどをまとめてオプティマイザと呼ぶことにします。
最適化アルゴリズムは、各パラメータの勾配(損失を減らすためにパラメータを更新すべき方向)を用いて、実際にパラメータを更新していく作業を担います。
最適化のアルゴリズムは多種多様ですが、今回は、最もスタンダードな SGD(stochastic gradient descent)を用いていきましょう。学習率(learning rate)は0.001を用い、モメンタム(momentum)は0.9とします。いずれも、比較的よく使われるスタンダードな値ですので、あまり深く考えず、とりあえずはこれで行きましょう。
深層学習のモデルは、ミニバッチ学習と呼ばれる方法で訓練されます。ミニバッチ学習では、何回も教師データを使いまわして、徐々に最適なモデルに訓練していきます。
このとき、教師データを使いまわす回数のことを、エポック数と呼びます。ここで問題になるのが、最適なエポック数が、事前に全く分らないということです。エポック数が少なすぎると訓練が足りないということが生じやすくなりますし、多すぎると過学習になってしまいます。そのため、ミニバッチ学習は、過不足の無いエポック数で止める必要があるわけです。
多くの場合は、Validation セットを用いて、この問題を回避します。
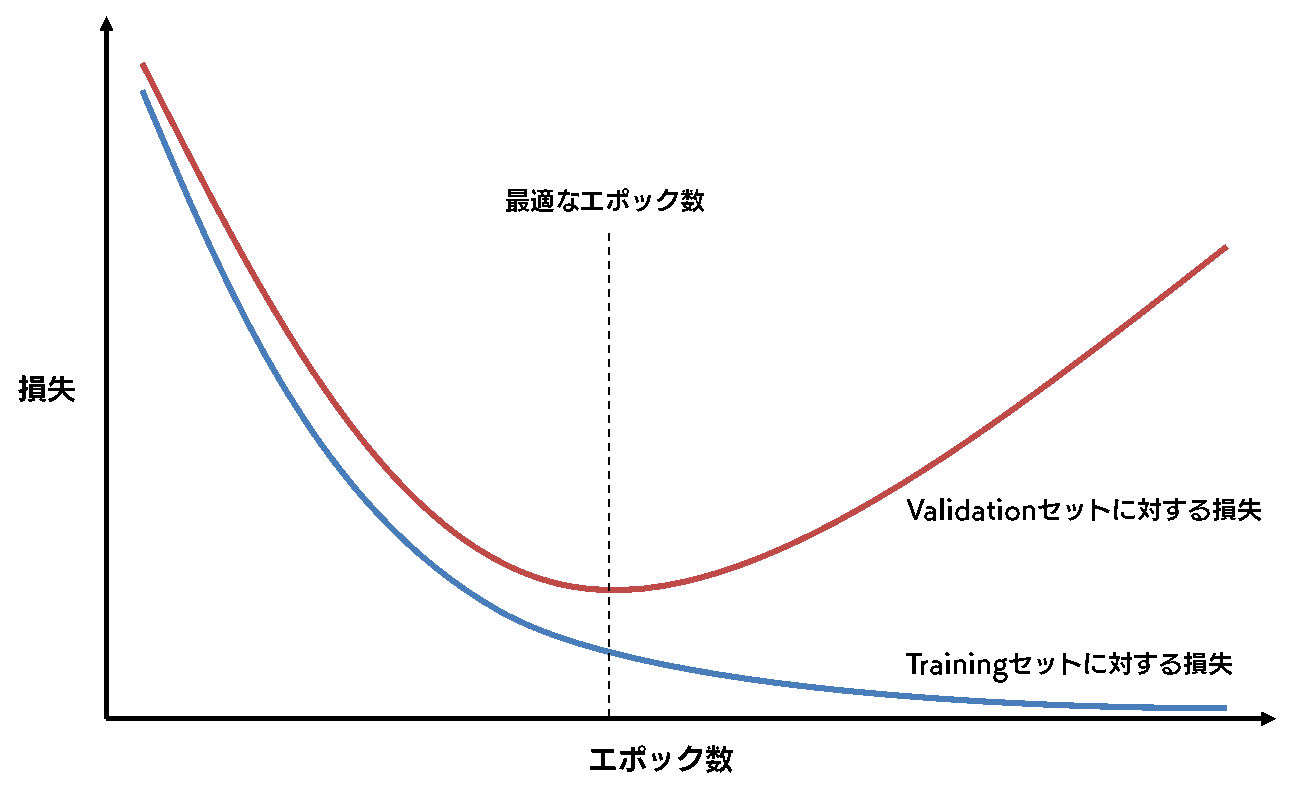
Training セットでモデルを訓練しつつ、各エポックで Validation セットでの損失や精度を算出することで、モデルの汎化性能を測定します。こうすることで、Validation セット、つまり訓練に使用していないデータに対する損失や精度が悪化する直前のタイミングで訓練のサイクルをストップすることができ、過学習を防ぐことができます。
学習率は、深層学習に使用する最適化アルゴリズムでは必須の数値です。深層学習のモデルの中のパラメータは、大雑把に言ってしまえば、損失をもとに計算された勾配(プラス方向/マイナス方向にいくらという値)に対して学習率を掛け合わせた値を足して更新されていきます。つまり、学習率が大きければそれだけ大幅にパラメータは更新され、学習率が小さければほとんどパラメータ更新されない、というわけです。
ここで、以下のような戦略を考えます。「学習率が小さすぎると、全然パラメータが更新されず、モデルの訓練に時間がかかりそうだ。なので、最初のうちは大雑把にパラメータを更新し、それなりに損失が小さくなったタイミングで、微調整を行えるようにパラメータの更新が大きくなりすぎないようにしよう。」
このような戦略は、最初はそれなりに大きい学習率で訓練をはじめ、訓練が進むにつれて徐々に学習率を小さくする、ということで実現できます。
今回は、PyTorch に実装されている StepLR という機能を使って、3エポックごとに学習率を0.9倍に減らしていく、というスケジュールにしてみました。
もっとも、学習率を徐々に小さくしていく、という戦略には、近年異論も提起され始めているようです。機会があれば、それについても、今後の記事で触れたいと思います。
さて、以上でファインチューニングに必要な要素はそろいました。ここからは、これらを組み合わせていきます。と言いつつ、ここでは、あまり細かいことを書くことはしません。以下の図をご覧ください。

大きなミニバッチ学習のループ処理があり、内部では各エポックで行われる学習処理と評価処理が行われています。また、各ループの最後に、学習率を変更したり、Validation セットに対する損失をもとに早期打ち切りをするか否かを判断したりしています。モデルの訓練が終わった後に、最終的な Test セットに対する評価の処理を行っています。
このようにして構築した分類器は、Test セットに対して、 分類精度92.1%を得ることができました!
今回の実験で、様々な犬種・猫種を92.1%の精度で分類することのできるベースラインモデルができました。Google Colaboratory で実行してみた方は、これよりも少々精度が良かったり悪かったりするモデルができているかもしれません。これは、モデルの訓練の一部に乱数が使われていることが原因です。
今回得られた92.1%という精度は、満足のいくものでしょうか?場合によってはそうでしょうし、場合によってはまだまだ改善が必要だ、と感じられることでしょう。これからの記事では、このベースラインモデルの分類精度を超えるための様々な方法について検証していきます。そのプロセスを通じて、画像分類モデル構築のノウハウをご紹介していければと考えています。
次回は、今回構築したモデルの弱点を探る、「エラー分析」に着手します。
それでは、また次回!




