こんにちは、データサイエンスチームの白石です。
前回は、マルチタスク学習を試してみて、犬猫分類器の精度向上を試みました。
結果としては、明確に改善した、と言い切れるほど大幅な改善はありませんでしたが、マルチタスクの導入によって精度が向上するケースも確認できました。
今回は、Attention 機構と呼ばれる仕組みを導入し、犬猫分類器の精度向上を試みます。
Attention 機構は、現代の深層学習の花形と言える仕組みです。
Attention 機構というと、自然言語処理などでよく使われる技術だ、と思われる方もいらっしゃるかもしれません。歴史的には、Seq2Seq と呼ばれる自然言語処理などで使用されるリカレントニューラルネットワークベースのモデルに対して組み込まれ、大きな注目を集めました。近年では、機械翻訳のために提案された Transformer(※1)とそれをベースにした BERT(※2)などの高度なモデルで全面的に使用され、様々な自然言語処理のタスクで最高精度を更新し続けています。余談ですが、Transformer を提案した論文は、Attention is all you need という挑発的なタイトルを冠しており、それまでリカレントニューラルネットワークをベースにした手法がほとんどだった機械翻訳のタスクの風景を一変させたことで知られています。
一方で、Attention 機構は画像認識の手法でも使用されています。日本で有名なのは、MIRU2019の参加報告でもご紹介した、Attention Branch Network(ABN)(※3)などがあります。ABN では、Attention 機構によって、CNN が出力した特徴量マップのどの領域に注目すればいいのかを自動的に学習し、自動車の車種やメーカーを高精度で認識できるようなモデルの構築に成功しています。また、動画中で人が行っている行動を認識するタスクのための手法である Video Action Transformer Network(※4)のような研究もあり、動画に対する認識でも、その有効性が確認されています。
このように、自然言語処理以外の分野でも、Attention 機構を用いたモデルの提案が行われているのですが、そもそも、Attention 機構とはどのような仕組みなのでしょうか?画像認識で使用することを前提に、簡単に確認していきましょう。
まずは、Attention 機構の一つのやり方である、空間方向の Attention について説明します。「空間」というのは、例えば自然言語処理では入力された単語列の一つ一つの単語の位置に相当し、画像認識では二次元画像中の位置に相当します。下図に、画像認識手法における一例を示します。

入力された画像から、CNN を通じて特徴量マップが抽出される、というのはごく普通の処理です。この特徴量マップに対して、Conv 層を適用し、活性化関数を通すことで、幅や高さはそのままですがチャネル数が 1 の Attention マスクを作成します。活性化関数は Sigmoid を適用することが多いようですが、ReLU を使うケースもあれば、マスクの全体を足すと1になるような Spatial Softmax(空間的なSoftmax)を適用することもあります。このようにして得られた Attention マスクを特徴量マップに掛けることで、重み付き特徴量マップを得ることができます。
Attention マスクは、その値が大きければ大きいほどその領域に注目する、というマスクとして機能します。そのため、犬や猫の画像であれば、犬や猫を識別するのに役立つ部分はマスクの値が大きく、分類に役立ちそうにない領域(例えば背景領域)は値が小さくなることが理想的です。
空間方向の Attention は、Attention マスクを通じて、画像中のこの領域に着目していることがわかり、予測根拠と見なすこともできるため、XAI(Explainable AI)の代表的な実装例となっています。
上記の図では、全結合層の直前の特徴量マップに対して Attention 機構を適用していましたが、Residual Attention Network(※5)のような手法では、CNN(上図にでは、ResNet-34の部分)の様々な段階で Attention 機構を導入することで、分類精度を高めることに成功しています。
続けて、もう一つの Attention の流儀についてみてみましょう。この方法には名前がついていて、SE-Block(※6)と呼ばれます。下図は、論文より引用した SE-Block の概念図です。
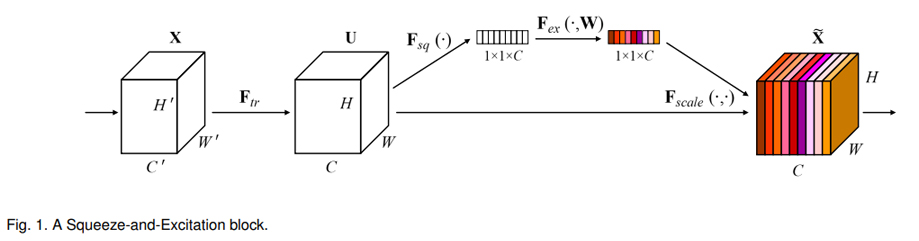
まず、CNN のある段階で得られる特徴量マップ(左から2つ目のブロック)に対して Global Pooling を適用し、幅と高さが 1x1 で、チャネル数はそのままの特徴量(上部の 1x1xC と書かれている白いブロック)を得ます。その後、この特徴量に対して2層の全結合層を適用することで、チャネル数はそのままのマスク(上部の 1x1xC と書かれているカラフルなブロック)を得ることができます。このマスクは、各チャネルをどの程度強調するべきかを表しており、このマスクを元の特徴量マップに掛け合わせることで、注目すべきチャネルを強調した特徴量マップ(右端のカラフルなブロック)を得ることができます。
今回はこちらの Attention 機構は実装しませんが、SE-Block 自体は様々な手法で取り入れられているものになるので、ぜひ覚えておいてください。
以上を踏まえ、今回は最もシンプルに、CNN によって得られた特徴量マップに対する空間方向の Attention を適用し、そのまま分類の全結合層につなぐ、というモデルを構築してみましょう。
今回も Notebook を用意しましたので、こちらも併せてご覧ください。
ひとつ注意点があります。Notebook の上から3つ目のセルまで実行すると、以下のようなテキストとリンク、そしてテキストボックスが表示されます。
これは、今回の Notebook の実行で得られる画像を Google ドライブに保存するための、認証処理です。決して怪しいものではないのでご安心ください。リンク部分をクリックすると、Google アカウントでのログインを求められるので、ログインすると、以下のような画面が表示されます。
こちらを「許可」していただくと、一時的なコードが発行される画面に遷移します。そのコードを Notebook 上のテキストボックスに入力すれば、認証は完了です。
なお、この認証によって、Notebook は Google ドライブ中の「Colab Notebooks」フォルダ内に「output」というサブフォルダを作成し、その中に画像を保存していきます。もしこの保存先に問題があるときは、この次のセルの「OUTPUT_DIR」を書き換えてください。
さて、実装の説明に移ります。まずは、ベースラインモデルからの変更が少ない、最もシンプルなものを実装します。変更すべき箇所は、ネットワークの定義のみです。しかし、せっかく Attention 機構を用いるので、Attention マスクを可視化する機能も実装しましょう。再掲となりますが、以下のようなネットワーク構造を定義していきます。

なお、損失関数に関しては、ベースラインモデルと同様で、クロスエントロピー損失を用います。
前回と同じように、nn.Module を継承し、新しいネットワークである SimpleAttentionNetwork を定義します。__init__内で、attn_conv という Sequential を定義します。この内部では、1x1 の2dConv を適用したのち、活性化関数として Sigmoid を適用しています。Forward メソッド内では、attn_conv によって得られた Attention マスクを特徴量マップに掛け合わせ、重み付きの特徴量マップを得ています。重み付きの特徴量マップに対して Global Average Pooling を適用し、分類の全結合層へと流し込んでいます。
class SimpleAttentionNetwork(nn.Module):
def __init__(self, num_classes):
super().__init__()
base_model = resnet34(pretrained=True)
self.features = nn.Sequential(*[layer for layer in base_model.children()][:-2])
self.attn_conv = nn.Sequential(
nn.Conv2d(512, 1, 1),
nn.Sigmoid()
)
self.fc = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(512, num_classes)
)
self.mask_ = None
def forward(self, x):
x = self.features(x)
attn = self.attn_conv(x) # [B, 1, H, W]
B, _, H, W = attn.shape
self.mask_ = attn.detach().cpu()
x = x * attn
x = F.adaptive_avg_pool2d(x, (1, 1))
x = x.reshape(B, -1)
return self.fc(x)
def save_attention_mask(self, x, path):
B = x.shape[0]
self.forward(x)
x = x.cpu() * torch.Tensor([0.229, 0.224, 0.225]).reshape(-1, 1, 1)
x = x + torch.Tensor([0.485, 0.456, 0.406]).reshape(-1, 1, 1)
fig, axs = plt.subplots(4, 2, figsize=(6, 8))
plt.axis('off')
for i in range(4):
axs[i, 0].imshow(x[i].permute(1, 2, 0))
axs[i, 1].imshow(self.mask_[i][0])
plt.savefig(path)
plt.close()
さて、Attention 機構を用いたモデルを実装するにあたってぜひ実施していただきたいのが、Attention の可視化のためのメソッドなり関数を早めに実装し、訓練途中で行われた処理結果を、画像として確認できるようにしておくということです。というのも、せっかく Attention マスクというわかりやすく訓練の進行を示してくれる指標があるわけですから、じっと訓練が終わるのを待ってから確認するよりは、訓練途中であっても随時 Attention マスクを確認し、訓練がうまく進んでいるか否かを確認したほうが、不具合を早期に発見できるためです。実際、Attention マスクは Weight Decay(L2 正則化)などの正則化の影響を受けやすく、結構極端な Attention マスクになることが多いです。例えば、画像に対する Attention マスクでは、画像の四隅に Attention が集中してしまい、そこから動かないといった極端な状態になることがあります。そのため、Attention 機構を用いたネットワークの訓練をするときは、各エポックの終わりなどに、いくつかのサンプルに対してどのような Attention が得られるのかを可視化し、確認しながら進めることをお勧めします。
今回は、save_attention_mask というメソッドを用意して、各エポックの終了時に呼び出すことで、Attention マスクを画像として Google ドライブ上の「Colab Notebooks/output/simple/attentions」以下のファイルに保存できるようにしました。
Attention 機構を使用したモデルに対して、精度の測定を行います。しかし、その前に、訓練済みのモデルでどのような Attention マスクが得られるのかを確認してみましょう。
まずは、訓練を行うことで Attention マスクがどのように出力されるようになるのかを確認してみましょう。
ハイパーパラメータはベースラインと同様にして、一度最後まで訓練させてみて、訓練完了時点でのモデルがどのような Attention マップを出力するのかを確認してみました。下図にその例を示します。
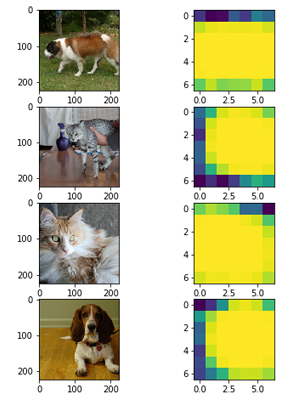
黄色い領域が Attention の集まっている部分です。画面の大部分が黄色いため、Attention マスクはかなり広めになるように訓練されたと確認できます。しかし、犬や猫が存在している領域に合わせて少し偏りが見られます。例えば、一番下の画像は、真ん中より少し右に犬が存在しており、隣に示された Attention の領域が右側に寄っていることに対応しています。よって、Attention マスクは大まかな位置が適切に訓練されていると確認できます。
それでは、精度を確認してみましょう。今回は30回ほど実験を行い、その際に算出された正解率を示しています。
左右にスクロールしてご覧ください。
| Validation 精度 | Test 精度 | |
|---|---|---|
| ベースライン | 91.6 | 92.1 |
| Attention モデル | 91.57±0.31 | 92.29±0.25 |
おや、と思われるかもしれませんが、今回のモデルは、ベースラインモデルとほとんど変わらないか、少し悪い精度となっています。Validation セットに対する精度が良かったモデルでは、Validation セットに対して 92.25%、Test セットに対して 92.43%と、それなりの精度となっていますが、今一つ伸びがありません。
実は、このモデルのようなシンプルな Attention 機構を施しただけのモデルでは、明らかに精度が良くなるということはほとんどありません。このようなモデルが必要となる場面は、「精度は現状維持でいいから、予測の根拠を明確にしたい」という場合が考えられます。評価指標だけでなく、そのような機能面からのアプローチも、一つの改善ではあります。
「機械学習導入支援サービス」の詳細はこちら
閑話休題。上記のようなシンプルな Attention 機構は、Attention マスク自体は適切に訓練できる一方で、精度がいまひとつ、という欠点を抱えていました。これには様々な理由が考えられますが、一般には、Attention マスクが注目する領域にメリハリがなくなってしまったり、ごく一部の領域しか注目しなくなってしまう、という問題があります。例えば、犬や猫の画像だと、Attention マスクが犬や猫の全身を含むかなり広い領域になっていたり、逆に犬や猫の顔だけに集中したりという結果となることが多いです。そのため、前回のマルチタスク学習で見たときのように、得られる特徴量の中に、品種を見分けるときに抑えておきたいポイントが得られないという可能性が出てきます。
そこで、Attention 機構をマルチヘッド化することを試みます。ここで言うマルチヘッド化とは、Attention 機構を複数用意して、それぞれが微妙に異なる役割を分担させることで、画像中の情報を漏れなく反映できるようにする、ということを意味します。理想的には、あるヘッドは犬や猫の耳に着目し、別のヘッドは犬や猫の顔に、また別のヘッドは犬や猫の足に、とヘッドごとに異なる部位の特徴を収集し、最終的に品種の分類に活かせる特徴量をつくる、ということが求められます。実際には、そこまで明確に、各ヘッドの担当部位が異なるように訓練するのは難しいのですが、イメージとしてはそのようなものだとお考え下さい。
マルチヘッドの Attention 機構を持つ画像分類モデルは、以下のような構造になります。
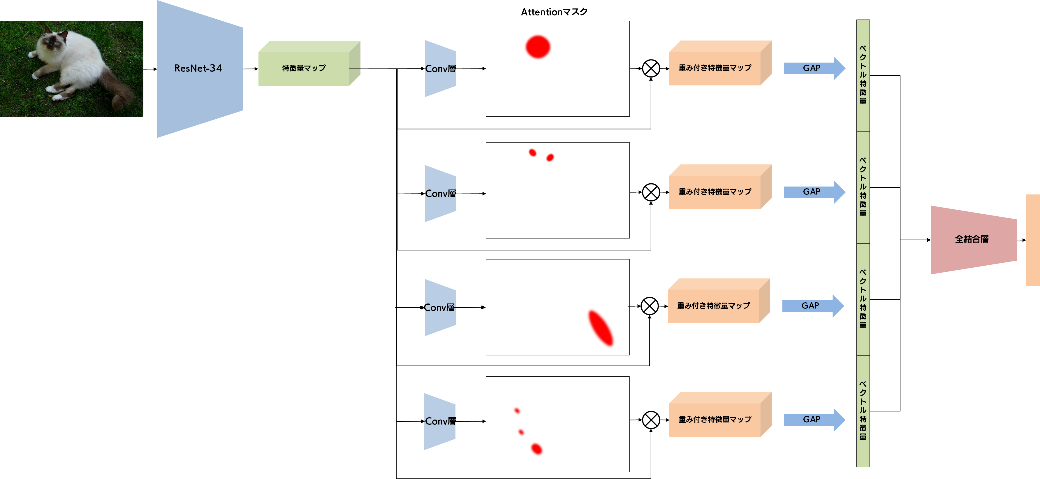
こちらも Notebook を用意していますので、併せてご覧ください。
マルチヘッドの Attention 機構の仕組みは単純ですが、Tensor の次元数が増えるため、実装するにあたっては頭の中が混乱してしまうかもしれません。そのため、各行で操作対象の Tensor がどのような形状になっているのかを確認しながら一行一行丁寧に進めましょう。また、複数のヘッドが、できるだけ異なる領域に注目できるように、注目領域の重なりに対して損失を与える、Diversify 損失も定義します。
マルチヘッドに対応した MultiAttentionNetwork を定義します。__init__ に num_masks という引数を設けていますので、マスクの枚数を指定することができるようにしています。前述のシンプルなモデルでは、1x1Conv 層の出力は1チャンネルの Attention マスクでしたが、ここで、1x1Conv 層の出力を M チャネルに変更します。このようにして得られた Attention マスクは、(M, H, W)という形状をしています。これは、HxW という大きさの M 枚のマスクが得られたことを意味します。
そして、それぞれのマスクを、特徴量マップに適用することで、M 個の重み付き特徴量マップを得ることができます。その後、各重み付き特徴量マップに Global Average Pooling を適用します。すると、M 個の 512 次元特徴ベクトルを得ることができます。このような複数の特徴ベクトルをどのように扱うのかについては、様々な方法があり得ますが、今回は単純に結合し、Mx512 次元の特徴ベクトルとしました。
特徴ベクトルが得られたあとは、全結合層に流し込んでいます。
class (nn.Module):
def __init__(self, num_classes):
super().__init__()
base_model = resnet34(pretrained=True)
self.features = nn.Sequential(*[layer for layer in base_model.children()][:-2])
self.attn_conv = nn.Sequential(
nn.Conv2d(512, 1, 1),
nn.Sigmoid()
)
self.fc = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(512, num_classes)
)
self.mask_ = None
def forward(self, x):
x = self.features(x)
attn = self.attn_conv(x) # [B, 1, H, W]
B, _, H, W = attn.shape
self.mask_ = attn.detach().cpu()
x = x * attn
x = F.adaptive_avg_pool2d(x, (1, 1))
x = x.reshape(B, -1)
return self.fc(x)
def save_attention_mask(self, x, path):
B = x.shape[0]
self.forward(x)
x = x.cpu() * torch.Tensor([0.229, 0.224, 0.225]).reshape(-1, 1, 1)
x = x + torch.Tensor([0.485, 0.456, 0.406]).reshape(-1, 1, 1)
fig, axs = plt.subplots(4, 2, figsize=(6, 8))
plt.axis('off')
for i in range(4):
axs[i, 0].imshow(x[i].permute(1, 2, 0))
axs[i, 1].imshow(self.mask_[i][0])
plt.savefig(path)
plt.close()
class MultiAttentionNetwork(nn.Module):
def __init__(self, num_classes, num_masks=4):
super().__init__()
base_model = resnet34(pretrained=True)
self.features = nn.Sequential(*[layer for layer in base_model.children()][:-2])
self.attn_conv = nn.Conv2d(512, num_masks, 1, bias=False)
nn.init.xavier_uniform_(self.attn_conv.weight)
self.fc = nn.Sequential(
nn.Linear(512 * num_masks, 256),
nn.ReLU(True),
nn.Dropout(0.5),
nn.Linear(256, num_classes),
)
self.mask_ = None
self.num_masks = num_masks
def forward(self, x):
x = self.features(x)
attn = torch.sigmoid(self.attn_conv(x)) # [B, M, H, W]
B, _, H, W = attn.shape
self.mask_ = attn
x = x.reshape(B, 1, 512, H, W)
attn = attn.reshape(B, self.num_masks, 1, H, W)
x = x * attn # [B, M, 512, H, W]
x = x.reshape(B * self.num_masks, -1, H, W) # [BM, 512, H, W]
x = F.adaptive_avg_pool2d(x, (1, 1)) # [BM, 512, 1, 1]
x = x.reshape(B, -1)
return self.fc(x)
def divergence_loss(self):
mask = self.mask_ # [B, M, H, W]
B, M, H, W = mask.shape
device = mask.device
flatten_mask = mask.reshape(B, M, -1)
diag = 1 - torch.eye(M).unsqueeze(0).to(device) # [1, M, M]
max_val, _ = flatten_mask.max(dim=2, keepdim=True)
flatten_mask = flatten_mask / (max_val + 1e-2)
div_loss = torch.bmm(flatten_mask, flatten_mask.transpose(1, 2)) * diag # [B, M, M] x [1, M, M]
return (div_loss.view(-1) ** 2).mean()
def save_attention_mask(self, x, path, head=4):
B = x.shape[0]
self.forward(x)
x = x.cpu() * torch.Tensor([0.229, 0.224, 0.225]).reshape(-1, 1, 1)
x = x + torch.Tensor([0.485, 0.456, 0.406]).reshape(-1, 1, 1)
fig, axs = plt.subplots(min(B, head), self.num_masks+1, figsize=(16, 2 * min(B, head)), squeeze=False)
plt.axis('off')
mask = self.mask_.detach().cpu()
for i in range(min(B, head)):
axs[i, 0].imshow(x[i].permute(1, 2, 0))
for j in range(0, self.num_masks):
axs[i, j+1].imshow(mask[i, j], vmin = 0, vmax = 1)
plt.savefig(path)
plt.close() Diversify 損失は、Diversified Visual Attention Networks for Fine-Grained Object Classification(※7)で提案された損失関数で、複数の Attention マスク同士ができるだけ異なる領域を担当するようにする正則化の損失です。下図は論文から引用したもので、4 枚の Attention マスクが、普通に訓練するとほとんど同じ領域を担当してしまっていたのが、Diversify 損失を加えることで、異なる領域を担当するようになった、ということを表しています。

実際には、分類損失との兼ね合いで、本当に Attention マスクが全く異なる領域を担当するようになることは稀ですが、正則化のための損失はそういうものです。興味のある方は、精度は落ちるとは思いますが、lambda_divergence という Diversify 損失の強さを決めているパラメータを大きめにして実験してみると、複数の Attention マスクの重なりがほとんどなくなることを確認してみると良いでしょう。
精度の測定に入る前に、先に Attention マスクがどのようになるのかを確認してみましょう。以下はヘッド数が 4 であるとき、つまりマスク数が 4 つの場合の可視化例です。一目見て気づくのは、どの画像に対しても大きめのマスク、中ぐらいのマスク、小さめのマスクが生成されている、ということです。さらによく見てみると、大きめのマスクは犬や猫の体全体を覆うマスクになっており、中くらいのマスクは上半身に、小さめのマスクは顔に対応しているように見えます。
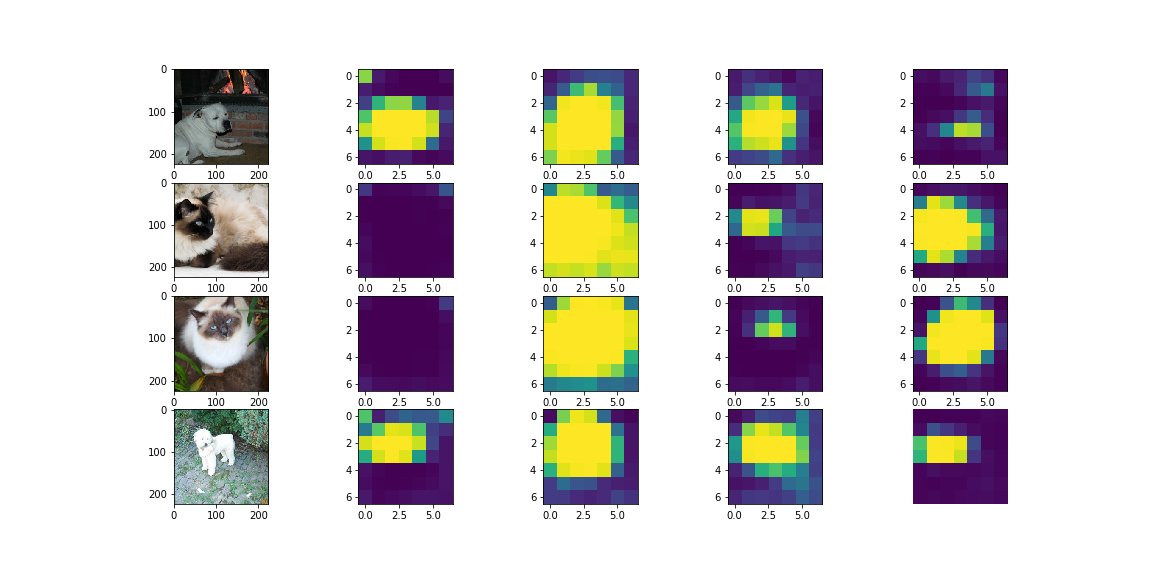
しかし、これらのマスク画像を列方向に眺めてみると、なんとなく 2 列目は犬や猫の全身に対応しているように見えますが、その右のマスクは犬では上半身に、猫では顔に対応しているように見えます。逆に、一番右の列では、犬では顔に、猫では上半身に対応しているようです。そして、一番左の列では、犬の上半身に対応しているように見えますが、猫にはマスクがかかっていません。各列のマスクがどのような領域や特徴に対応しているのか、なかなか解釈が難しい、ということがこの例だけからもわかるかと思います。Attention 機構のヘッド数を増やすと、このような解釈の難しさが生じてしまうことにご注意ください。
さて、このような工夫を加えると精度はどうなるのでしょうか?こちらも、30 回ほど実験を行って、その平均とばらつきを確認しています。なお、先ほどと同様、ハイパーパラメーターチューニングは行っていませんが、ヘッドの数は 4 で固定し、生成されるマスク画像の確認をしながら lambda_divergence を調整しました。
左右にスクロールしてご覧ください。
| Validation 精度 | Test 精度 | |
|---|---|---|
| ベースライン | 91.6 | 92.1 |
| Attention モデル | 91.57±0.31 | 92.29±0.25 |
| マルチ Attention モデル | 91.96±0.44 | 92.45±0.30 |
Validation 精度も、Test 精度の平均はかなり良くなっていることが確認できます。また、先ほど説明したシンプルな Attention モデルよりも精度は向上する傾向がみられます。なお、最も良いモデルは、Validation 精度が 92.47%、Test 精度が 92.79%のモデルでした。
しかし、依然として精度のばらつきは大きく、確実にベースラインを超えるモデルになる、とは言えない状態です。ここには、訓練のプロセスに不安定な要素が入っていることが想像できます。Attention マスク用の Conv 層や全結合層の初期化方法や、ミニバッチ作成時のサンプリング方法など、考えられる要素はいくつかありますが、このあたりの話題については私自身もまだ勉強中です。
以上のように、Attention マスクを用いることで、犬種と猫種の分類モデルの精度向上を目指しました。結果としては、前回と同様、「明らかに上回っている」とは言えない状況ではありますが、Test セットに対する精度は 92.79%と今までで最高の精度を出すことができました。
この連載も大詰めですが、次回はまた別の方向からモデルの精度向上を目指します。
それではまた次回!
(※1)Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems. 2017.
(※2)Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
(※3)Fukui, Hiroshi, et al. "Attention branch network: Learning of attention mechanism for visual explanation." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
(※4)Girdhar, Rohit, et al. "Video action transformer network." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
(※5)Wang, Fei, et al. "Residual attention network for image classification." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.
(※6)Hu, Jie, Li Shen, and Gang Sun. "Squeeze-and-excitation networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
(※7)Zhao, Bo, et al. "Diversified visual attention networks for fine-grained object classification." IEEE Transactions on Multimedia 19.6 (2017): 1245-1256.




