こんにちは。 データサイエンスチームの白石です。
2019年7月29日(月)~8月1日(木)まで行われた MIRU2019 に参加してきました。
本記事では、その様子を簡単にではありますがレポートいたします!

MIRU(画像の認識・理解シンポジウム)は国内で最大規模のコンピュータビジョン(以下、CV)のシンポジウムです。 規模だけでなく、質的にも優良な研究成果が集まる学会です。
毎年場所を変えて開催されており、今年は大阪の中之島にある国際会議場(グランキューブ大阪)で行われました(上の写真は、学会のトップページにも掲載されている、重要文化財である大阪市中央公会堂です)。
今年の参加者数は1000人超で、大学と企業で半々だったようです。一方で、投稿者は75%が学生で、投稿論文は70%以上が英語だったそうです。投稿論文の70%以上が英語、ということからわかるように、本学会は国際学会を目指している優秀な若手研究者が集まる、登竜門的な学会であると言えるかと思います。企業参加者も多いことからわかるように、企業が次世代の研究者をリクルーティングする場としても機能しています。
私は今回が初参加だったので、様々な研究発表についていけるのか最初はちょっと不安だったのですが、結果として、非常に濃密な時間を過ごすことができ、大変満足感がありました。
他にも、スポンサー企業による展示や、実際に動くものを見せるデモ発表、複数人のパネリストによる議論を聞く特別企画など、盛りだくさんの内容でした。
本来ならば面白いと思った講演や発表についてそれぞれ感想を書いていくべきなのかもしれませんが、各日に1つずつ、最も印象に残った発表を中心に取り上げることにします。
MIRU 初日はチュートリアル4連発でした。
チュートリアルは、ある分野の入門的な内容を、その分野の専門家に解説してもらい、聴講者はそれを聞いて学んでいく、というお勉強要素の強いセッションです。4つのチュートリアルはどれも大変面白く、充実した内容だったのですが、1つだけ、感想を書きたいと思います。
4つあるチュートリアルのうち2つ目に行われた、東京大学の松井助教による、「近似最近傍探索の最前線」について簡単に紹介します。
最近傍探索とは、入力されたベクトル(query)に対して最も近いベクトルを大量のベクトルデータの集合の中から獲得する、という問題です。例えば入力された画像から何らかの特徴量(ベクトル)を抽出し、それを使って、最も近い特徴量の画像を検索する際などに必要となる技術です。
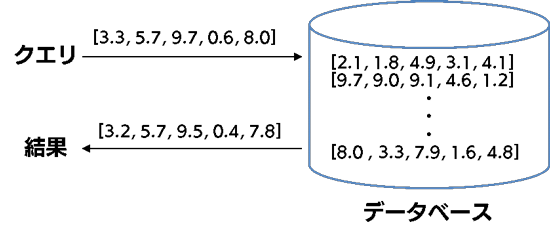
一般には、このベクトルデータの集合が増えれば増えるほど、query ベクトルと個々のベクトルとの類似度を計算する回数が増加し、計算に必要なコストが増大します。 そこで、本チュートリアルのタイトルにある「近似」最近傍探索という技術が必要になってきます。これは、愚直にすべてのベクトル間の距離を計算するのではなく、近似的に近いベクトルを取得する、ということを目的とします。
私が近似最近傍探索に対して持っている知識は、OpenCV の FLANN というアルゴリズムを少しだけ学生時代に触ったことがあるハズ、というあいまいな記憶と、Yahoo Japan の NGT や Microsoft の SPTAG なんかのニュース記事を読んだことがある、という程度だったのですが、そんな私でも非常にわかりやすい内容で、大変勉強になりました。
発表スライドは、Speaker Deck にて公開してくださっている ので、興味のある方はぜひご覧になってください。かなり丁寧に作られている資料なので、ある程度この分野に興味のある方であれば、ふむふむと読み進めることができるのではないかと思います。時間の無い実務者の方は、7ページ目のフローチャートだけでも見ておくと、自分たちのデータに適したライブラリを選択できるので、いざというときに役立つと思います。
2日目はいよいよ学会の本格スタートです。オープニングの後の特別公演では、スウェーデン王立工科大学の牧教授が、深層学習で用いることのできる、Feature Contraction という正則化手法について、ていねいに解説していただきました。また、欧州における AI をめぐる大学や投資家の動きについての紹介も行われました。
この日最も印象に残ったのは、招待講演のいちばん最初に行われた Attention Branch Network(以下、ABN)に関する発表でした。この論文は、CV 系のトップ学会の一つである CVPR 2019 のオーラルに採択された論文です。画像分類のための CNN ベースのアーキテクチャで、CNN によって抽出された特徴マップ(Feature Map)から着目するべき領域(Attention map)を算出し、その着目領域に対して重みづけをしたうえで認識するという、いわゆる Attention 機構を提案しています。下図は論文から引用した、ABN の大枠を説明した図です。
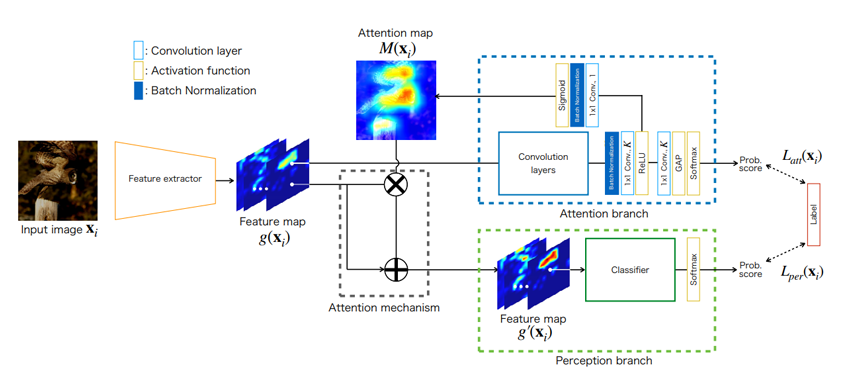
私の読んでいる論文に偏りがあるだけかもしれませんが、CV 分野における Attention 機構は、特徴量マップに対して1~2層の Conv 層を適用して Attention マップを得る、といった割と簡素な仕組みであることが多いという印象でした。そのため、ABN を最初に読んだときは、Attention 機構が Attention Branch という、それなりの深さを持っているモジュールとして設計されており、目からウロコになった覚えがあります。
当日は、中部大学の藤吉教授が登壇されていました。私はすでに CVPR に採択されたものを読んでいたこともあり、内容に関してはふむふむと聞いていたのですが、最後に触れられた「CVPR オーラル発表までの経緯」というスライドが興味深かったです。
そのスライドでは、本研究が CVPR に採択されるまでの経緯が説明されました。論文のもととなっている手法は2017年には着手が始まっていて、CV 系トップ学会の一つである ECCV 2018 に一度リジェクトされてしまったそうです。しかし、その際のフィードバックや、昨年の MIRU2018 のオーラル発表、NVIDIA のイベントである GTC Japan でのポスター発表などを経て、ようやく CVPR 2019 でアクセプトされたとのことでした。
国際学会に論文を通すためには、素晴らしい手法を考案しましたというだけでは不十分で、国内外の発表の機会を通じたフィードバックを謙虚に論文に反映し、様々なデータを使った実験によって有効性を証明することが大切だ、ということがよくわかるお話でした。
3日目は、松尾教授による特別講演からスタートしました。講演は大きく2つの内容から成り、1つは今後の AI の発展のための理論的な仮説、もう1つはビジネス側から考える AI の発展の方向性について、が語られました。前者では例えば、コンピュータにとっての意味処理は「動物 OS 系と言語アプリ系」のモデルで説明できるのではないか、という仮説を披露されていました。また、後者では例えば、1960年から始まったインターネットの発展と比較することで、現在の AI ブームは、インターネットの発展における1990年代後半に当たるのではないかという議論をされていました。
3日目に最も印象に残ったのは、中部大学藤吉研究室(2日目に続き!)の「複数ネットワークの共同学習における知識転移グラフの自動最適化」でした。
この研究の要点は、Knowledge Distillation(知識蒸留)と Deep Mutual Learning(相互学習)というネットワークの訓練プロセスを、共同学習という統一的な枠組みで捉えなおすという内容でした。
本研究のエッセンスを簡単に説明します。
まず、Knowledge Distillation とは、学習済みの教師ネットワークの持っている知識を、未学習の生徒ネットワークに伝えようという訓練方法で、知識蒸留とか、単に蒸留と訳されます。よく使われる例として、比較的低速だが高精度な学習済み教師ネットワークを、軽量な生徒ネットワークを使って蒸留することで、教師ネットワークの知識を概ね受け継いだ高速なネットワークに変換できる、ということが知られています。さらっと、「知識を受け継ぐ」と書きましたが、一般的には、各ネットワークの出力分布(各カテゴリに対する予測の確率分布)をできるだけ一致させるように訓練することで実現できます。
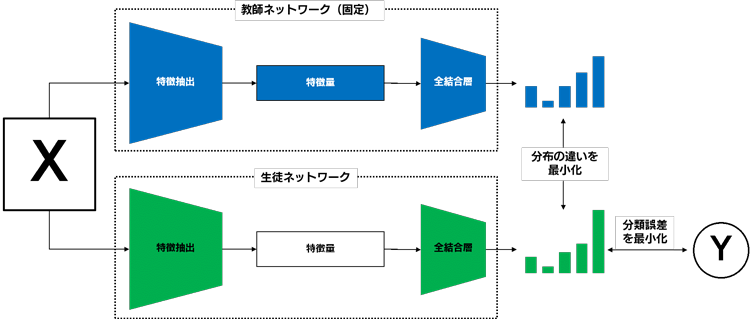
一方で、Mutual Learning とは、未学習の2つの生徒ネットワークを同時に学習させ、Knowledge Distillation の場合と同様にお互いに知識を伝え合うことで、高精度に学習ができるというテクニックです。2つの生徒ネットワークは同じアーキテクチャの時もあれば、異なるアーキテクチャの時もありますが、いずれにせよ知識の伝達として出力分布ができるだけ一致するように訓練されます。
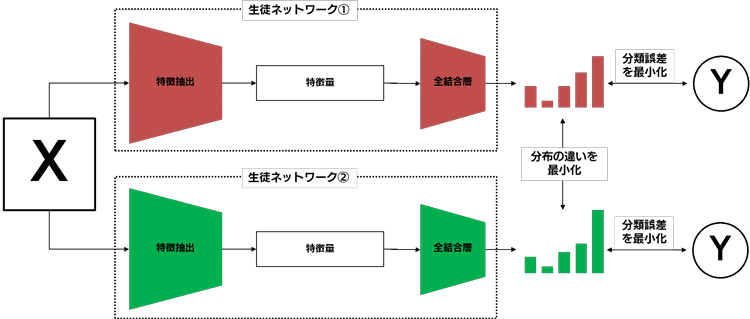
これら2つの手法は、下図のように有向グラフとして表現することで、同一の枠組みで捕らえることができます。
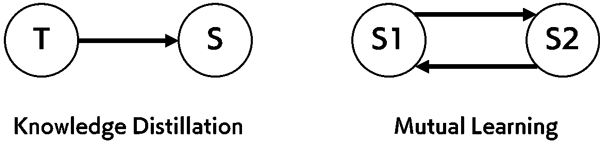
各ノードが教師または生徒ネットワークで、ノード間に張られているエッジは、知識転移の方向を表します。また、エッジには個別の損失関数が定義されており、損失関数の内部では、損失を接続されているエッジに対してどのように伝播させるのかを制御するゲートが定義されています。
このようにして複数のネットワーク間の知識転移や教師信号をもとにした訓練をグラフで表現すると、例えば以下のような3つ以上のノード(教師ネットワークや生徒ネットワーク)からなる有向グラフでも、複数のネットワーク間の知識転移と訓練を表現できます。このような知識転移グラフで表現できる訓練プロセスを、本研究では共同学習と呼んでいます。
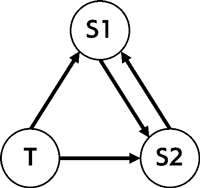
このように、一見まったく異なる2つの訓練プロセスを一般化することで、これまで前提としていた要素をハイパーパラメータとして捉えなおすことができます。そして、これらの要素をチューニングすることで、より様々なネットワーク間の知識転移の可能性を模索することができる、というわけです。実際、3つ以上のネットワーク間の知識転移をチューニングすることで、例えば、教師信号と接続せずに、教師ネットワークからの蒸留のみの方が良いモデルが得られることもある、といった面白い例が紹介されていました。
この研究は、MIRU 長尾賞 に選ばれました。
さて、いよいよ最終日です。この日は午前中からオーラル発表・招待講演が続き、最後のインタラクティブセッションが行われました。
そして、プログラムの最終セッションである、特別企画「企業と大学、両方を経験した研究者が語る真実!ほんとにオススメなのは・・」が行われました。大学と企業のどちらも経験されている方々が登壇されていて、どの登壇者も、「企業と大学という、そんな単純な二者択一の問題ではないよね」という前置きはしつつも、ご自身のキャリアや何を重視して自分が仕事をする場所を決めてきたのか、というお話をされていて、興味深く聞かせていただきました。
最終日に最も印象に残ったのは、電気通信大学の柳井研究室の研究成果です。 本発表では、「弱教師あり」領域分割(セグメンテーション)に関する最新の研究成果を聞くことができました。
セグメンテーションというタスクでは、非常に手間のかかるアノテーション作業(物体の領域をカテゴリごとに塗り分けるという、途方もない作業)を経て作られる教師データが必要になります。しかし、本研究が扱っている「弱教師あり」セグメンテーションというタスクでは、教師信号としてカテゴリ情報のみを必要とし、それ以上の教師データを必要としないタスクです。
もしも、弱教師ありセグメンテーションが高精度に実現できるようになれば、セグメンテーションという、画像認識系のタスクの中でもかなり面倒なアノテーション作業が不要になるかもしれない、というわけです。
弱教師ありセグメンテーションでは、一般的に、教師信号として与えられているカテゴリ情報を「分類するのに役立つ領域」と「物体領域」にギャップがあることが問題になります。例えば、画像中に存在する動物名を答えるという画像分類問題を解くときに、動物の顔さえ見れば大体の動物はわかる、という状況を想定してみてください。顔の領域のみが「分類するのに役立つ領域」で、しっぽや足などを含む「物体領域」は、分類にそこまで直接敵に役立つ領域ではありません。このギャップは、Class Activation Map(以下、CAM)によって示される予測根拠領域が、物体の領域全体を覆うのではなく、物体の一部に集中してしまう現象として知られています。

弱教師ありセグメンテーションでは、CAM などの手法によって得られた物体領域の候補を元手に、Conditional Random Field(条件付確率場, 以下 CRF)によって、類似する特徴を持つピクセルへ領域を拡張して疑似教師データを作成し、セグメンテーションモデルを再訓練する、ということを繰り返す手法が一般には使われているそうです。
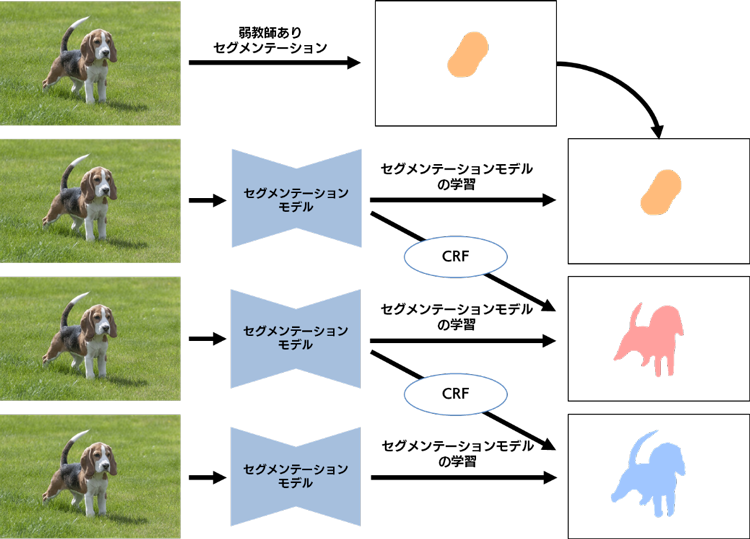
しかし、このやり方は、CRF によって生成される疑似教師データにノイズが含まれてしまうと、そのノイズを学習することになってしまい、どこかで精度が下がってしまう危険性があります。
そこで本研究では、CRF によって得られる変化領域を無防備に採用せず、吟味することにしています。つまり、すでに物体領域であるという前提を置いている領域(Knowledge)をもとに、CRF によって変化する領域(Advice)が本当に信用できるのかを算出し、採用するか否かを判定する、というわけです。信頼度の計算の詳細は省略しますが、簡潔に言えば、Knowledge の側から Advice を予測しやすく、かつ Advice の側からからも Knowledge を予測しやすいのであれば、その Advice を採用する、という双方向の計算によって信頼度を算出しているようです。
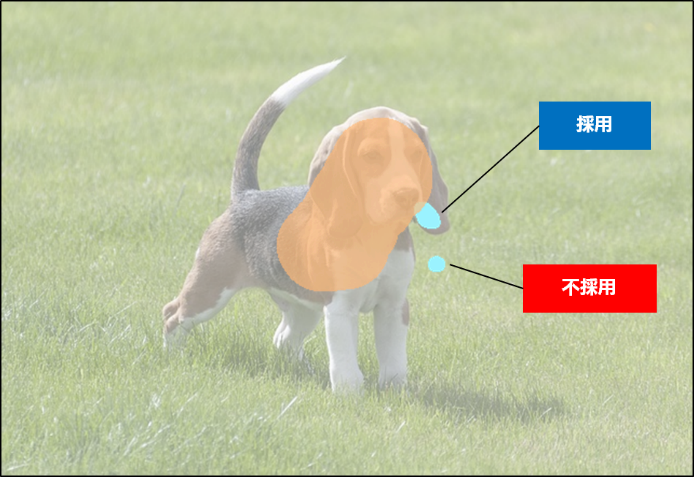
個人的な興味として、隣接する問題設定である、Weakly Supervised Object Localization、すなわち弱教師ありの物体位置推定に興味があり、いろいろとサーベイをしていたので、話の取っ掛かりからぐっと興味を惹かれました。 本研究は、Pascal VOC 2012 データセットのセグメンテーションタスクにおいて state of the arts(現時点での世界最高精度)を達成し、今年10月末から11月頭に行われる ICCV 2019 に採択されたそうです。
以上、簡単にではありますが、MIRU2019 の参加報告とさせていただきます。
すでに国際会議に通っている招待講演はもちろん聴き応えがあったのですが、初出に近いであろうオーラル発表・ポスター発表の中にも国際的な潮流の原点になりうる研究が集まっており、全体的にハイレベルな内容だったかと思います。
こういった学会は、本当の初心者が行っても、そう簡単には面白さがわからないとは思いますが、ある程度この分野の研究を追いかけていたり、具体的な課題を持っていたりする人が行くと、とても楽しく、実り多いイベントなのではないかと思います。
本記事で紹介できなかった数々の発表からも、いくつものアイディアをいただきました。すぐに、というのは難しいとは思いますが、自分の仕事へ反映させることができればと思います。
発表者・運営の皆様、参加者の方々ありがとうございました。また来年も参加したいと思います。




