こんにちは、データサイエンスチームの白石です。
前回の記事 で、初学者向けの記事を書くと宣言していましたので、さっそくですが入門記事のようなもの書いていきます。とはいえ、あまり教科書的な内容もどうかと思いますので、できるだけ実践的な内容をお伝えできるよう、心がけていきます。
今後数回に分けて、「画像分類モデルを作ろう」と題して記事を書いていく予定です。具体的な画像分類モデルを構築してみることを通じて、深層学習のノウハウを学んでいきましょう。
今回は、実際のモデル構築に入る前の、予備知識や準備、そしてモデル構築の進め方について書いてみました。
まずは、今後数回にわたってお世話になるデータセットを紹介しておきましょう。この連載では、少しチャレンジングなデータセットである、Oxford-IIIT Pet Dataset というデータセットを使っていきます。
このデータセットは、犬25種と猫12種の合計37種の写真から構成されているデータセットで、「犬」や「猫」という大まかな分類よりも細かいサブカテゴリ、つまり「犬種」や「猫種」まで見分けて分類するというタスクのためのデータセットです。 このデータセットは、CC BY-SA 4.0 のもと配布されています。
少しデータセットの中身を覗いてみましょう。
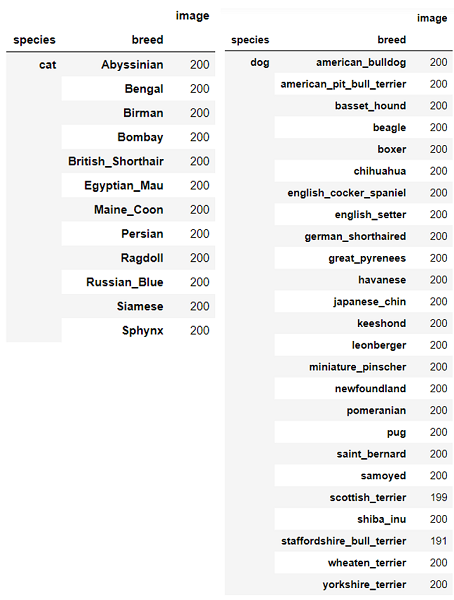
まずは、以下の表をご覧ください。これは、データセットに含まれている画像の枚数を、カテゴリ毎に集計したものです。犬25種類と猫12種類それぞれのカテゴリに、画像が何枚用意されているかがわかります。概ね、各カテゴリに200枚の画像が用意されていますが、一部の犬種では200枚に届いていない、ということが確認できます。
次に、具体的な画像を見てみましょう。以下に、各カテゴリから1枚ずつ選出した画像を示します。

ひとくちに犬、猫といっても、さまざまな見た目の種類がいることがわかります。例えば、耳が立っているもの・寝ているもの、毛が多いもの・少ないもの、色がまだらのもの・単色のもの、といった具合です。また、写真によっては、きちんと顔が写っているものもある一方で、背を向けているものもあります。背景も屋内、屋外、単色など、さまざまです。
もっと他の画像も見てみたい、という方は、データセットを本データセットの公式ページからダウンロードして解凍し、エクスプローラーでサムネイル表示にして、ざっと眺めてみると良いでしょう。
「犬」や「猫」といった比較的常識に属するカテゴリの、さらに細分化されたサブカテゴリまで分類する画像分類タスクを、Fine-Grained Visual Categorization(高精細な画像分類:FGVC)と呼びます。
FGVC では、多くの場合以下のような難しさを抱えています。
今回チャレンジする Oxford-IIIT Pet Dataset の分類も、以上のような難しさを抱えていると言えるでしょう。
FGVC の難しさがわかったところで、画像分類モデルを構築する際の、お勧め手順を示しておきます。
順番に説明していきます。
画像分類に限らず、データ分析を行う際には、まずは自分たちがどのようなタスクを解こうとしているのか、どのようなデータを使おうとしているのか、ある程度理解しておく必要があります。
画像分類の場合は、すでに示したように、カテゴリごとの画像枚数を確認したり、一枚一枚の画像をざっと眺めてみたりして、混同しやすそうなカテゴリはないか、どういった特徴をつかめればちゃんと分類できそうか、人間でも間違えてしまいそうな例はどのくらいあるか、などを確認しておきます。
特に注意するべきは、各カテゴリの画像の枚数の偏りです。今回はどのカテゴリも均一な枚数ですが、場合によっては特定のカテゴリのデータだけ極端に多かったり、逆に極端に少なかったりします。そのような場合は、損失関数にカテゴリ毎の重みをつけてあげたり、Focal Loss のような特殊な損失関数を使用したり、学習時のサンプリング方法を工夫する必要が出てくるので、注意しましょう。
自分たちが解こうとしているタスクは、どのくらい難しい問題なのでしょうか? 多くの場合、易しい問題と難しい問題との間にはっきりした境界があるわけではありません。そのため、機械学習モデルの構築は、「やってみないとわからない」ということがほとんどです。
難しいタスクを解決するためには難しい手法が必要になることがありますが、それを試す前に、まずは基本的な手法で何とか解決できないかを確認してみましょう。
まず検討する価値があるのは、各社が提供している画像分類のサービスやツールです。
Microsoft であれば、Cognitive Service の Custom Vision があります。Custom Vision は、画像分類や物体検出といったタスクに対するモデル構築を支援してくれるサービスで、モデルの学習と評価だけでなく、エッジデバイス向けのモデルの出力機能や Web API 化機能も備えています。
このような既存のサービスやツールは、最先端の手法と比べれば劣ってしまう部分もあるでしょう。しかし、タスクによっては実用的な精度でのモデル構築を、安定して実現してくれるため、特にビジネスユーザーであれば真っ先に検討する方法となります。
次に、各所で公開されている学習済みのモデルをチューニングすることで目的の分類モデルを作る、ファインチューニングと呼ばれる方法を検討しましょう。こちらは、既存のモデルに多少のチューニングを加えることで、各種サービスやツールの精度を超えることを目標とすると良いでしょう。
ここまでの検証で得られたモデルを、ベースラインモデルと呼ぶことにしましょう。ベースラインモデルとは、画像分類モデルを改善していくうえで、「超えるべき壁」として立ちはだかるモデルのことを指します。
もしも、ベースラインモデルで得られる分類精度が十分であれば、これ以上の検証は必要ありません。実用化に向けて、システムに組み込み、活用していきましょう。
しかし、ベースラインモデルの精度が不十分だった場合は、何らかの対策を立てる必要があります。
ベースラインモデルに精度上の問題があるとき、「データが足りませんでしたね、データをもっと集めましょう」とか「画像の解像度が粗いですね、もっといいカメラや撮影条件を整えましょう」という話になりがちです。
もちろん、これは間違いではありません。実際に多くのデータ分析では、データを記録する際の不備やノイズの多さが致命的な問題となっていることも多いです。
しかし、やみくもにデータ収集を頑張るより前に、できることがあります。
エラー分析です。
なぜ今のモデルは不十分な精度なのか、どのようなカテゴリなら分類できていて、どのようなカテゴリは間違えてしまうのか、どのような理由で誤分類をしてしまうのか、逆に、なぜ特定の画像については正しい分類ができているのか、よく分析してみましょう。
分析の過程で、「このような情報を学習することができれば、きっとうまくいくはずだ」、「このような追加情報があれば簡単に分類できるかも」というアイディアを、頭をひねって考えましょう。
アイディアは、完全にオリジナルなものである必要はありません。多くのアイディアは、既存の方法の組合せや、既存の方法の真似から出発するものです。
深層学習の世界では、多くのアイディアが、論文という形で公開されています。似たようなデータ、似たようなタスクに対して、どのような手法が提案されているのか、調査してみましょう。論文そのものを読めないとしても、その解説記事を読んだり、Github などで公開されている実装を参考にしたりすることは、できるはずです。
ところで、アイディアというのは、深層学習の世界にだけ落ちているわけではありません。昔からあるレガシーな画像処理技術と組み合わせて前処理を工夫するとうまくいくこともあります。あまり視野を狭くせず、さまざまな技術や知識を総動員して、アイディアを練りましょう。
実際にエラー分析をやってみると、さまざまなアイディアが浮かんでくることでしょう。ここまでたどり着いたとき、あれも試してみたい、これも試してみたい、そんな状態になっているはずです。
思いついたアイディアに優先度をつけ、1つ1つ検証していきましょう。多くのアイディアは、残念ながら絵に描いた餅に終わることでしょう。苦労して実装した新しいモデルが、ベースラインモデルを下回ってしまうということはよくあることです。
しかし、粘り強くアイディアを検証することで、精度の向上という明確な成果をもたらすはずです。
アイディアを実装する、検証する、エラーを分析してアイディアを洗練させる、というサイクルを回して、より良いモデルを目指す、というのが画像分類モデルの改善のための最重要な作業となります。
今回は、画像分類モデルを構築する連載の初回ということで、実際のモデル構築に入る前の、予備知識や準備、進め方について書いてみました。
次回からは、実際に Oxford-IIIT Pet Dataset を用いて、画像分類モデルを構築していきましょう。
それではまた次回!
関連ページ
深層学習入門:画像分類モデルを作ろう(2) |




