はじめまして、データサイエンスチームの白石です。
幅広くデータサイエンス・機械学習の分野の研究・開発を行っています。ブログの第一回目ということで、どんな記事にしようかなと考えてみたのですが、自己紹介も兼ねて、「深層学習とわたくし」といった趣の記事を書いてみようと思います。
深層学習がブレイクしたきっかけとしてよく挙げられるのは、2012年の大規模画像認識のコンテストである ImageNet Large Scale Visual Recognition Challenge(ILSVRC)における、トロント大学チームの圧倒的な勝利です。 この年、私はちょうど新卒一年目でした。当時はデータサイエンスの分野に進むということは微塵も考えていませんでしたし、こういったアカデミックなトレンドも耳に入ってこない状況でした。
状況が変わったのは、上司がデータサイエンス部門への異動を勧めてくれた時でした。もともと学生時代に物体検出を用いた研究を行っていたこともあって、機械学習の分野には多少のなじみがあったというのが理由でした。
そういうわけで、2014年からデータサイエンス部門で新米データサイエンティストのキャリアが始まりました。当時の仕事内容はマーケティング分野の広告効果の分析が多く、機械学習というよりは、統計的なモデリングを主に行っていました。
2014年の末ごろだと思いますが、私は「深層学習」というワードに出会います。松尾豊先生の『人工知能は人間を超えるか』が発売されたのが2015年3月ですから、多くの人とそう変わらない時期に、私も深層学習に出会ったわけです。
当時の私は、実は深層学習にかなり懐疑的でした。
こういったネガティブな反応は、ニューラルネットワークを触ったことのある多くの人が抱く感想だったのではないでしょうか。
というわけで、私はしばらくの間は深層学習については本格的に取り組んではいませんでした。当時の仕事内容から、深層学習を使う必要があまりなかったというのも理由の一つです。
とはいえ、一応、深層学習の手法でこんなことを実現したというニュース記事や、こんなことをやってみましたというブログ記事をウォッチしてはいました。
そんな中、2016年末に pix2pix という手法と出会います。
この手法は、画像の生成モデルと呼ばれるもので、入力された画像をもとに、目的とする違和感のない画像を出力する、というものでした。例えば、線画から自然なカバンの画像を生成したり、衛星写真から地図のように領域が塗り分けられた画像を生成することができています。
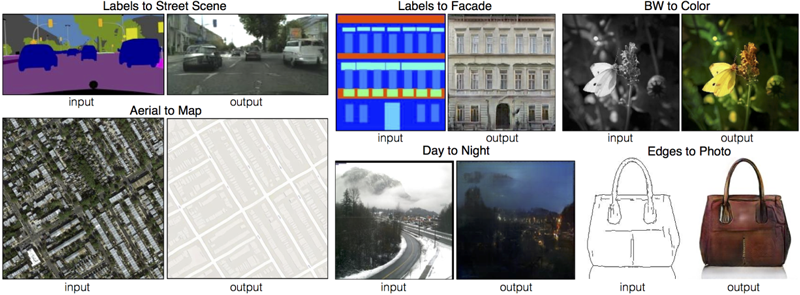
公式のプロジェクトページで実際にデモを触れるようになっていたのも驚きでした。適当に描いた線が猫の画像に変換されるのを体験して、深層学習が持っている可能性が一気に広げられた感覚を覚えました。
このような画像の生成モデルは、当時進行中であった案件に直接的に役立つものではありませんでしたが、私を深層学習の入門へと動機づけるものとして十分なインパクトを持っていました。 以後、なんとなく趣味で深層学習の論文を読み始めるようになりました。その習慣は今も続いていて、現在では、月に5から10本くらいは読めているかな、という状況です。最近は、業務時間中に論文を読むことも増えてきました。
深層学習のいいところは、画像であれ、テキストであれ、音声であれ、ある程度共通のフレームワークの中で扱うことができるという点にあります。 社内で深層学習エンジニアを育てたいという企業様は、いっそのことビジネスとは無関係なものを作ることを通して、深層学習の基礎を学んでみるというのも一つの手なのではないでしょうか。
せっかくなので、自分が最近作った、あまりビジネスでは見ないタイプの深層学習の手法について紹介してみようと思います。
Visual Question Answering(VQA)と呼ばれるタスクが機械学習の分野にはあります。以下の画像をご覧ください。
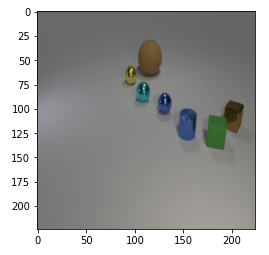
何やら幾何学的な物体が置かれていますね。これらの物体は、球・円柱・立方体、ゴムらしきマットな材質・メタリックな材質、大きい・小さいといういくつかの条件を組み合わせたものです。VQA では、このような画像に対して以下のような質問文が与えられます。
「There is a cyan shiny sphere that is behind the tiny blue metallic cylinder; Is there a small blue ball that is on the right side of it?」
日本語訳してみましょう。
「小さく青のメタリックな円柱の後方に、シアンの輝く球体があります。その右側に、小さく青いボールはありますか?」
少々くどい質問文ですが、画像を見ながら考えれば、答えが「yes」と導けます。
VQA では、このように、画像と質問文が提示され、質問に答えるというタスクを達成することを目指します。
CLEVR データセットと呼ばれる公開のデータセットでは、このような画像と質問文の組合せが、大量に用意されています。このデータセットには、yes/no だけでなく、特定の条件を満たす物体の個数を数えたり、形状や色を答えるような問題も含まれています。 ちなみに、このデータセットに対する人間の正解率は92.6%です。質問文が少々くどくて読み取りにくいことを考慮しても、意外に難しい問題であることがわかります。
VQA を解くためには、以下の3つの能力が、機械学習モデルに備わっている必要があります。
このような能力を備えたモデルを構築するための手法が様々に提案されていますが、今回は、スタンフォード大学の提案している MAC Network を、勉強も兼ねてイチから PyTorch で実装してみました。
この手法では質問文を読み解く部分、画像を読み解く部分は、いずれも一般的な手法である双方向 LSTM や、学習済みの ResNet-101 を用いています。肝となるのは推論部分でして、MAC cell という特殊なセルを用いた再帰的なネットワークになっています(深層学習に触れたことのある方は、LSTM cell や GRU cell のようなリカレント系のセルの特殊なバージョンだと考えていただければよいかと思います)。
>MAC cell は、以下のように、ControlUnit、ReadUnit、WriteUnit という3つの部品から成り立っています。
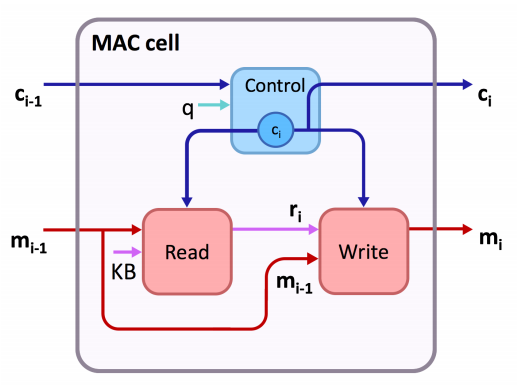
ControlUnit では、質問文情報(図中のq)をもとに、画像からこのような情報を取得せよ、という Control 情報を抽出します。この Control 情報をもとに、ReadUnit では実際に画像(図中のKB)から Read 情報を抽出します。そうして、読みだした Read 情報を、WriteUnit で Memory 情報に反映させます。
このような流れを何度か繰り返しながら、Control/Memory 情報を更新していき、質問に答えられるような情報を抽出していきます。面白いのは、Control Unit と Memory Unit の内部で Attention 機構が使われていることです。Attention 機構とは、という説明をし始めると長くなってしまうので、詳細な説明は省略しますが、質問文中のどの部分に注目して Control 情報を抽出するか、画像中のどの部分に注目して情報を抽出するかを、決められるような仕組みだとお考え下さい。
実装自体2日くらいではたいした苦労もなくできたのですが、チューニングが少々厄介で、実装当初は正解率50%前後をうろうろしていました。うまくチューニングして1台の GTX 1080ti で40時間ほど学習させてあげると、以下のように、Control Unit や ReadUnit 内で行われている質問文や画像に対する Attention が観察できます。左側が質問文に対する Attention、右側が画像に対する Attention(Attentionされている領域は明るい)です。 まずは全体を見渡して、次に目的の小さく青いボールに注目し、それがシアンの輝く球体の右側にあるな、という確認をしながら推論している、ということがなんとなくですが読み取れるかと思います。質問文中に対する Attention と画像に対する Attention がおおむね一致しているのも面白いですね。
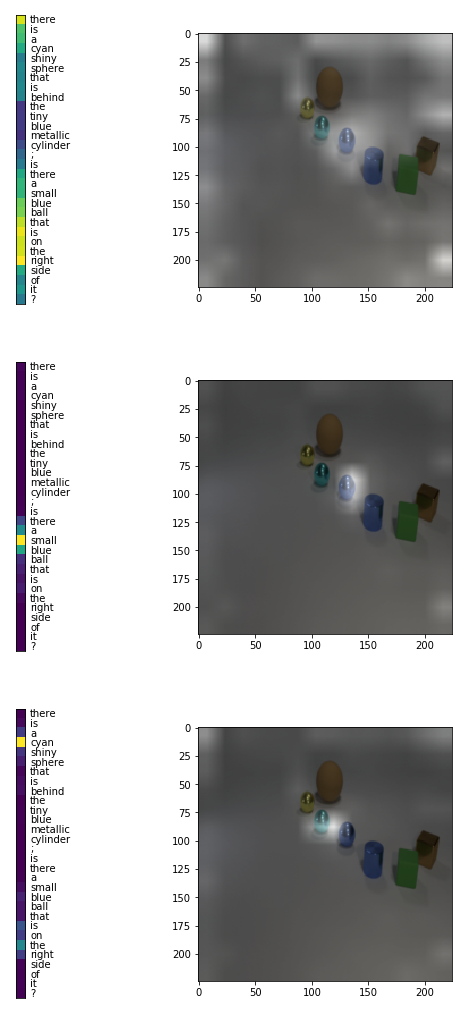
残念ながら、現状の正解率は90%程度で、論文で報告されている98.9%よりも低くなってしまっています。今後は、実装上の問題を確認したり、細かいチューニングをしていく予定です。
以上、私自身と、最近の個人的な趣味の取り組みについて、簡単にですが紹介させていただきました。
今後は、機械学習をめぐる動向についての調査や考察、あるいは初学者向けの入門記事のようなものを書いていくつもりです。
今後もよろしくお願いします!




