インフラやアプリのシステム運用を主の業務としております 前川敦史です。
「膨大なメールを深層学習して運用効率化ツールを作る2」の方法紹介の続きとなります。
※ 1つ目の記事「膨大なメールを深層学習して運用効率化ツールを作る1」はこちら
その前に今回も小話を挟みますが、友人との宴会の最中に突然会場が暗くなり、誕生日を祝う曲と共に以下のモノが私の前に置かれました。

周りのお客さんからも「まえかわ たかしさんおめでとう」と拍手をいただきました。
ドリカムさんの「HAPPY HAPPY BIRTHDAY」が心地よかったこともあり、名前を訂正するタイミングを逃しました。
さて、前回はプログラムを動かす為の環境構築を行いましたが、今回は膨大なメールから深層学習を行う方法「学習編」を始めたいと思います。
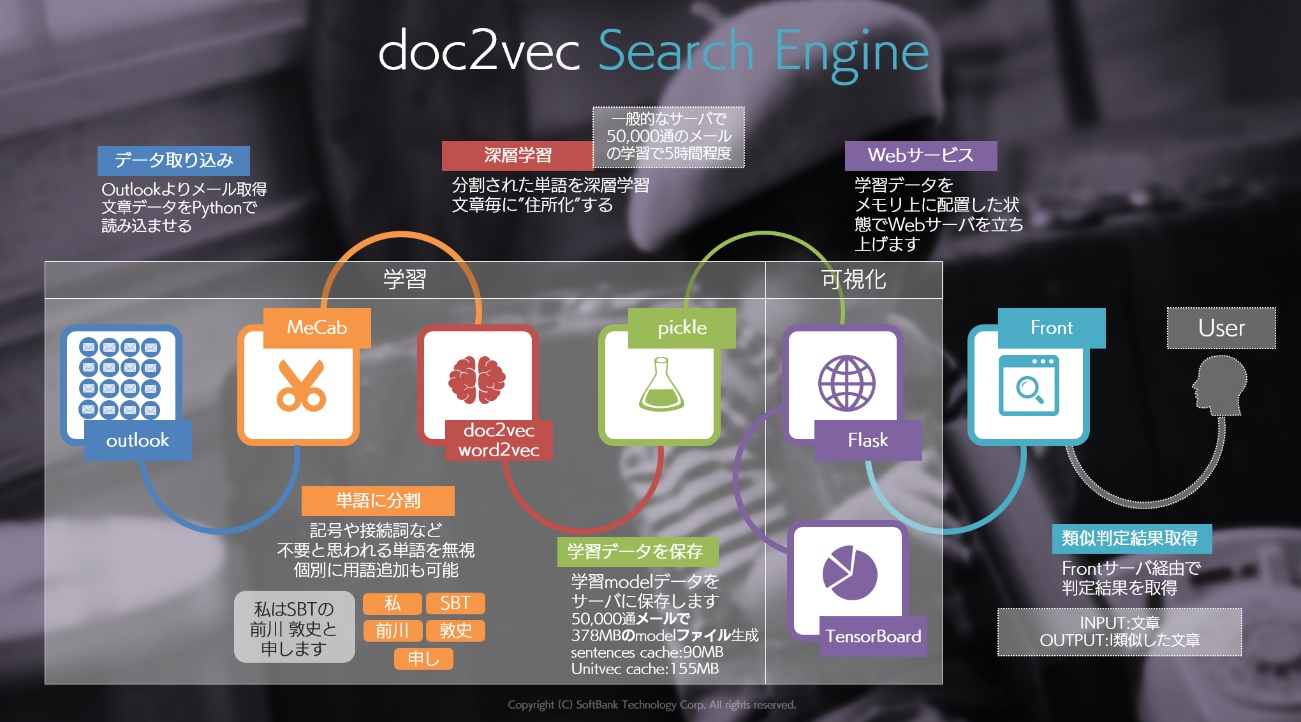
上記が本プログラムの全ての動きを表す図となりますが、今回の記事では図で”学習”と書かれているところを行います(Outlook, MeCab, doc2vec word2vec, pickle と書かれている部分です)。次回で”可視化”の部分を紹介します。
ソースコードの中身について細かく解説したいところですが、今回は私が作成したソースコードをそのまま実行していただき、解説は次回以降で行いたいと思います。
当社のご提供する「機械学習導入支援サービス」資料請求・お問い合わせはこちら
こちらのファイルよりソースコードのダウンロードをお願いします。
sbt_outlook_doc2vec.zip
ダウンロードしたファイルを解凍していただき、コマンドプロンプトで解凍後のディレクトリ「sbt_outlook_doc2vec」に移動してください。
コマンドプロンプトより以下のコマンドを入力してください。
python -m pip install --upgrade pip
※ Python のパッケージ管理ツールである pip そのものがアップグレードされます。
さらにコマンドプロンプトより以下のコマンドを入力してください。
pip install -r requirements.txt
※ requirements.txt に記載された Python のパッケージがインストールされます。
requirements.txt に記載されているパッケージ
pypiwin32
mecab-python-windows
numpy
scipy
gensim
scikit-learn
tensorflow
wordcloud
Flask
Outlook からメールを取得して学習させ、学習データを保存するところまでを行います。
Outlook を起動させた状態で
ディレクトリ:sbt_outlook_doc2vec から以下のコマンドを叩いてください。
python learning.py
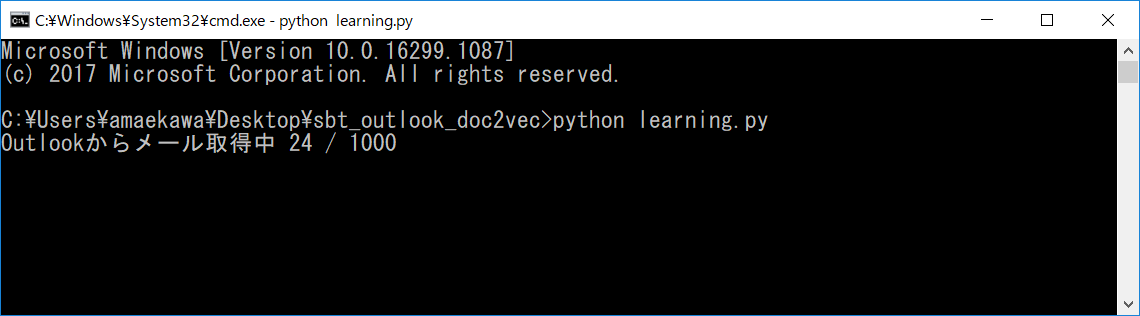
起動中の Outlook の受信トレイから1,000件のメールの取得が始まります。
他のフォルダのメールを取得したい という方は以下を書き加えてください。
earning.py 変更後def make_sentence_from_outlook(): outlook_mapi = win32com.client.Dispatch("Outlook.Application").GetNamespace("MAPI") # Outlook API読み込み outlook_folder = outlook_mapi.GetDefaultFolder(6) # inboxのフォルダを取得
こちらは初期フォルダ配下の既読というフォルダのさらに下にある重要というフォルダを設定したという例になります。def make_sentence_from_outlook(): outlook_mapi = win32com.client.Dispatch("Outlook.Application").GetNamespace("MAPI") # Outlook API読み込み outlook_folder = outlook_mapi.GetDefaultFolder(6) # inboxのフォルダを取得 outlook_folder = outlook_folder.Folders('既読').Folders('重要') # ここを追加
また、Outlookメール取得の際、お使いの環境によって以下のようにセキュリティの問題で取得時にメッセージが表示される事があります。
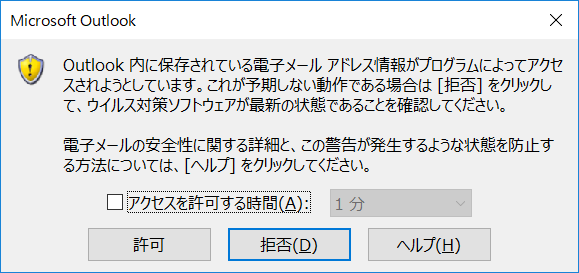
1通開く度に"許可"を押す必要がありますので手間となります。
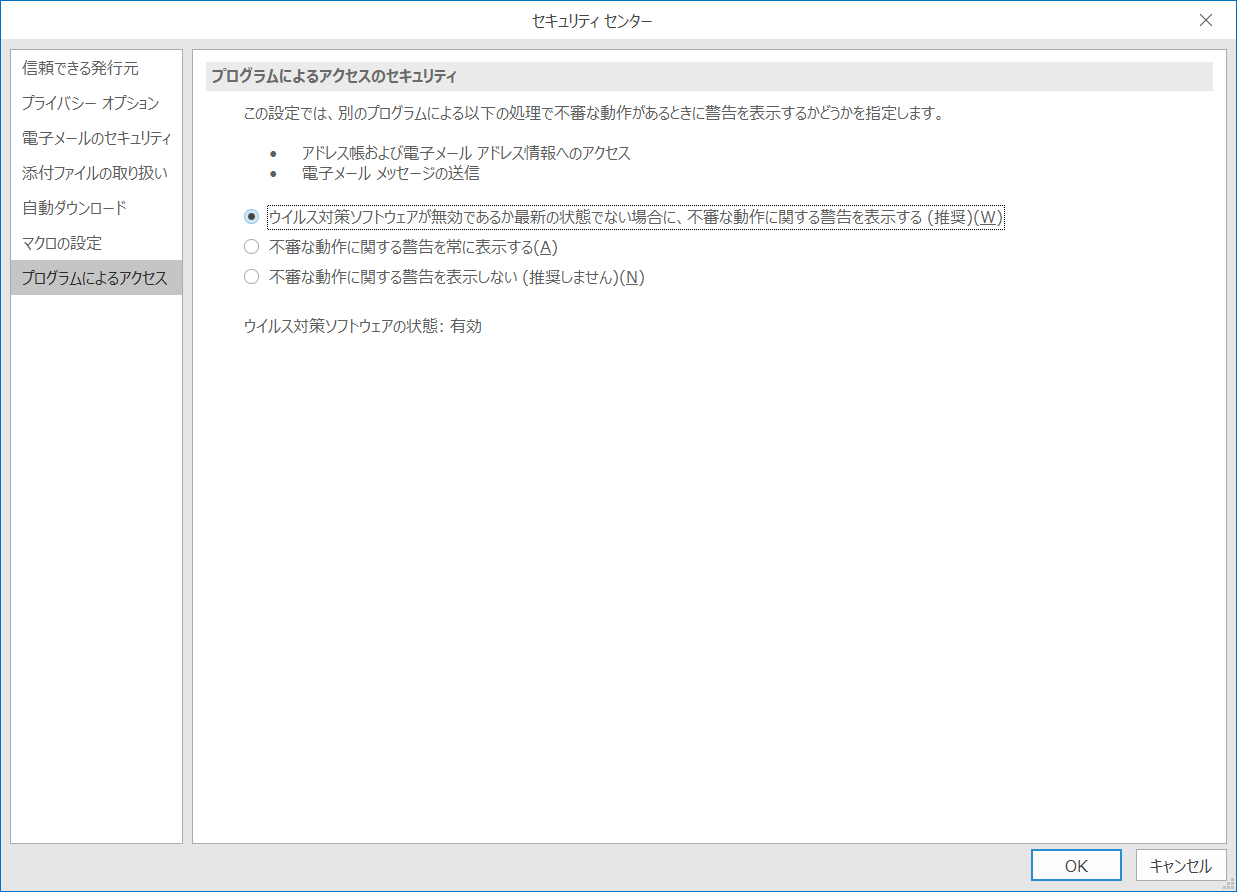
その際は Outlook → オプション→セキュリティセンター から以下の設定をご確認ください。
ウィルス対策ソフトウェアが無効であるか最新でない場合に、不審な動作に関する警告を表示する(推薦) を選択して OKを押しますとこちらの警告は出なくなります。
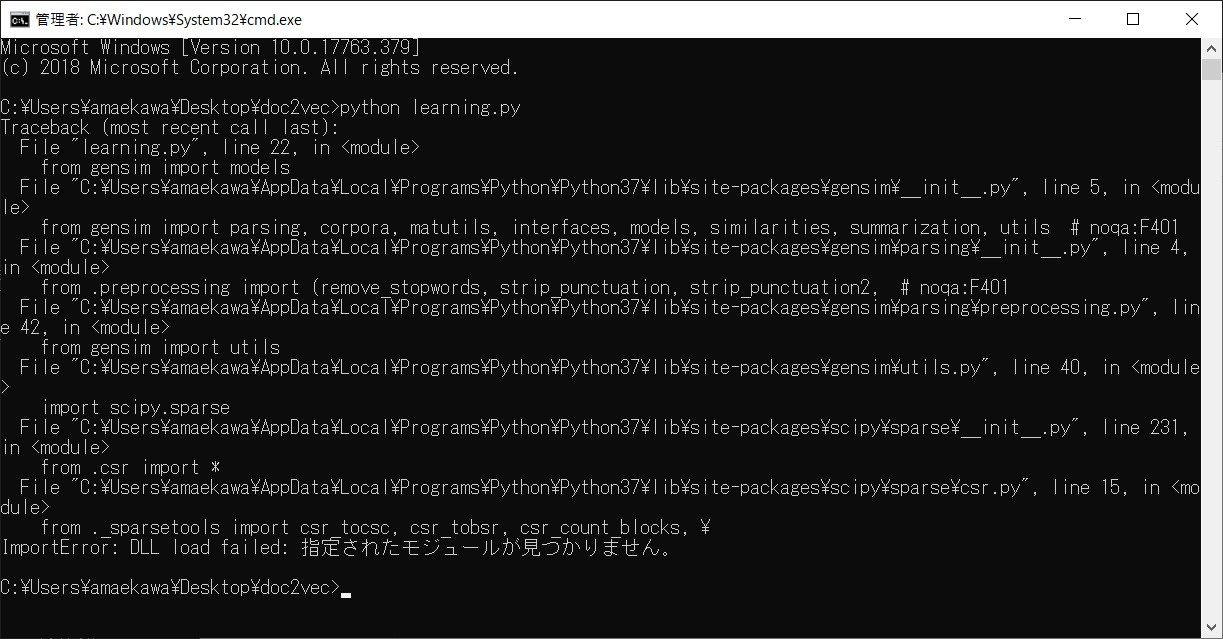
以下のエラーが出た方は、”Visual Studio 2017 用 Microsoft Visual C++ 再頒布可能パッケージ” のインストールをお試しください。
ImportError: DLL load failed: 指定されたモジュールが見つかりません。
以下ページの x64: vc_redist.x64.exe のリンクよりダウンロード可能です。
https://support.microsoft.com/ja-jp/help/2977003/the-latest-supported-visual-c-downloads
「detected Windows; aliasing chunkize to chunkize_serial」という警告が出ますが気にせず実行してください。
※ Windows だとパフォーマンスが遅いので、一部機能を変換しているという意味となります。

以下のように「終了」と表示されていれば学習データの生成が完了となります。
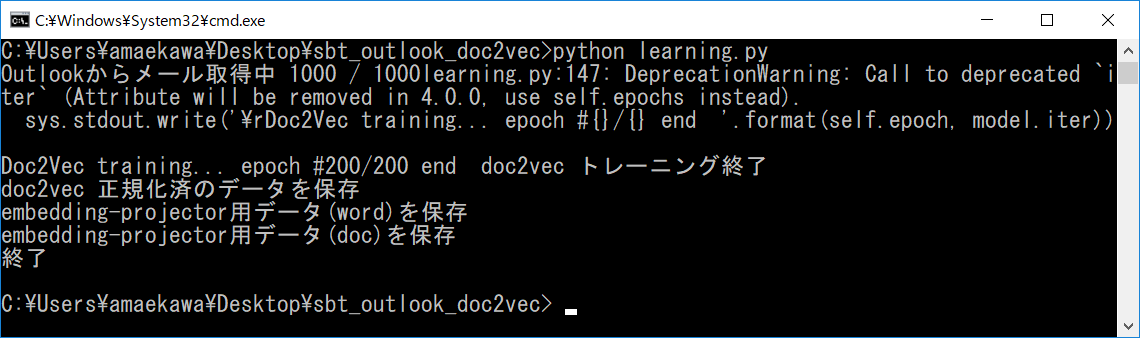
左右にスクロールしてご覧ください。
| model(から始まる全てのファイル) | Doc2Vec が生成したファイルとなります。 類似した単語や文章を計算する際に使用します。 |
|---|---|
| subjects.pickle | Outlook の件名リストを格納しています。 |
| model_l2norm_list.pickle | 類似判定の結果表示スピードを向上させるため、あらかじめ途中まで計算を行った数値を格納しています。 |
| word_tensor.tsv.gz word_metadata.tsv.gz doc_tensor.tsv.gz doc_metadata.tsv.gz |
次回使用する予定の TensorBoard(embedding-projector)用のファイルとなります。 学習したデータを資格的に確認することができます。 |
1000件のデータで学習した内容について精度を確認します。
以下のコマンドを入力してください。任意の文字は自分の名前などを入れてください。
python word2vec_test.py "任意の文字"
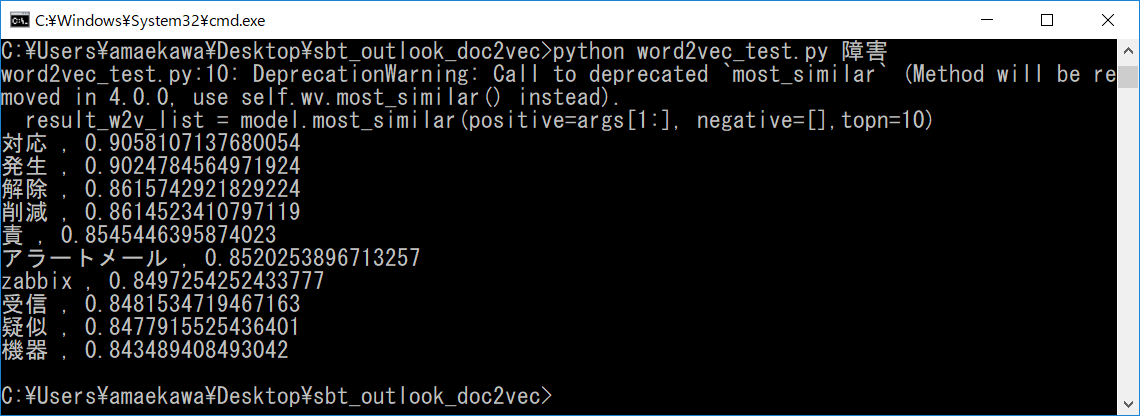
類似した単語が10件表示されます。
左に単語、右に類似度を表す数値(1に近いほど類似性が高い)が出力されます。
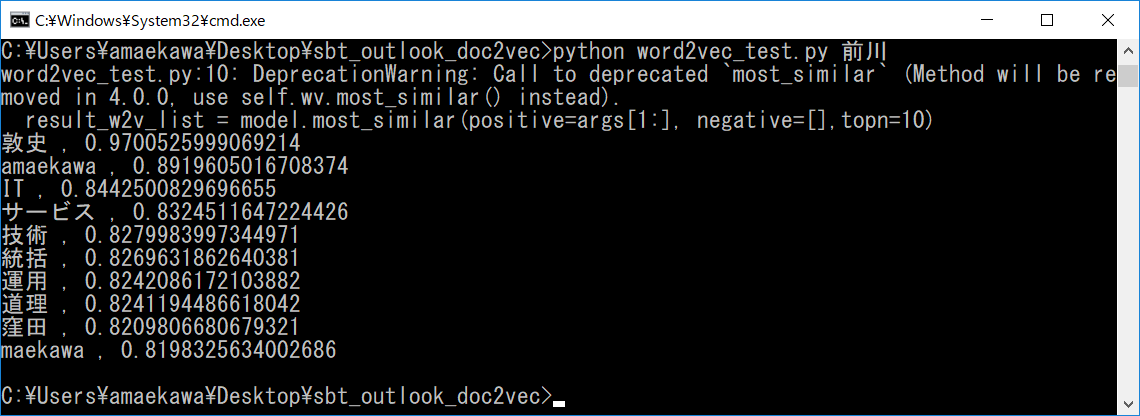
私の苗字である”前川”を入れた場合は、私の名前の他の部分や 私の組織名の一部が出力されています。
一般的な言葉である”障害”と入力した場合は、”対応”や”発生”などそれにまつわる単語が出力されています。
ご自身が仕事で関わっているさまざまなワードを入れてみて精度を確認するのがよいと思います。
続けて以下のコマンドを入力してください。
python doc2vec_test.py "任意の文章"
類似した文章が10件表示されます。
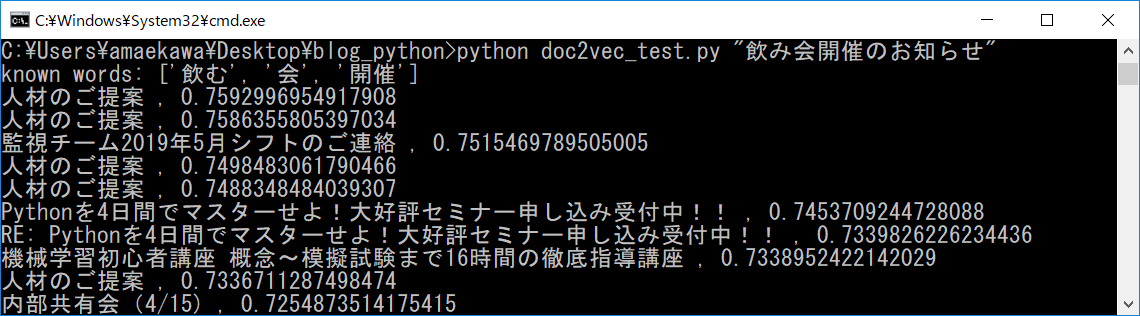
「飲み会」に関する文章を取得したかったのですが、期待とは違う結果が返り、精度は高くありませんでした。
近い文章が出てくることもありますが、1,000件ですと精度は低いようです。
当社のご提供する「機械学習導入支援サービス」資料請求・お問い合わせはこちら
以下の設定を変更することで Outlook から取得するメールの数を増やすことができます。
1000となっているところを増やして実行してみましょう。
# こちらで指定したメールのカウントを取得
MAX_OUTLOOK_ITEM_COUNT = 1000
# こちらで指定したメールのカウントを取得
MAX_OUTLOOK_ITEM_COUNT = 50000
私の方では50000としましたが、ここはお好きな数値を入れてもらえればと思います。
※メールの数より多くの数値を入れてもエラーは発生しません。
こちらの学習はかなり時間がかかると思います。
私の環境ですと50,000通で5時間程度かかりました。
先ほど同様、以下のコマンドを入力します。
python doc2vec_test.py "任意の文章"
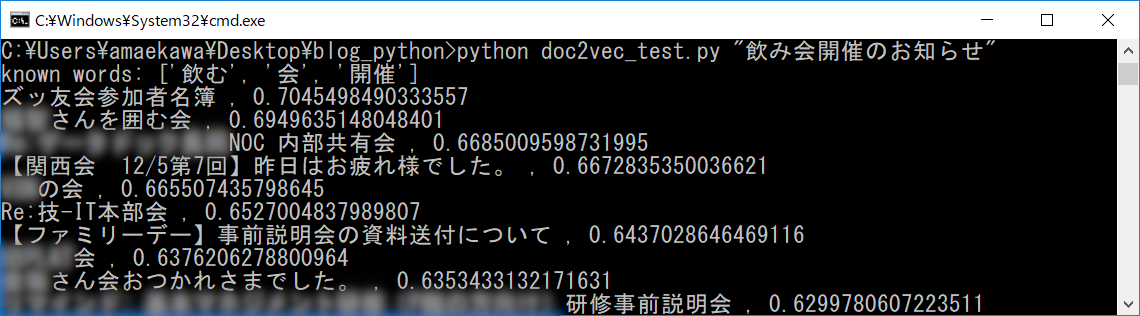
通常の会議も混ざっておりますが、8割は中身が宴会系のメールとなっておりまして、まずまずの結果になったと思います。
皆さんの環境ではいかがでしたでしょうか?
ソースコード内を変更することにより精度が上がる期待もありますので、そちらは次回以降で解説したいと思います。
次回は今日作った学習データを”可視化編:インスタ映えするような深層学習”を紹介したいと思います。
関連ページ
当社のご提供する「機械学習導入支援サービス」資料請求・お問い合わせはこちら |




