インフラやアプリのシステム運用を主の業務としております 前川敦史です。
膨大なメールを深層学習して運用効率化ツールを作る方法紹介の続きとなります。
今回の小話なのですが、私が一人で映ったプリクラがどうしても必要で、仕方なく一人でプリクラを撮影しに行ったのですが、その店舗では男性のみでのプリクラエリア入室が禁止となっていました。
この件について家族と真剣に話し合い、家族立ち合いの元で撮影を行いました。全て以下のような棒立ちの状態で撮影したのですが、立ち会った家族も同じように私を見ながら棒立ちでした。おかげで良いプリクラが撮影できたと思います。


家族を残し、落書きコーナーに一人で入る私を学生達はどう見ていたのか、私には想像もつきません。
では "可視化編:インスタ映えするような深層学習" をご紹介したいと思います。
前回の記事で作成した学習モデルのファイルを使用して可視化を行います。
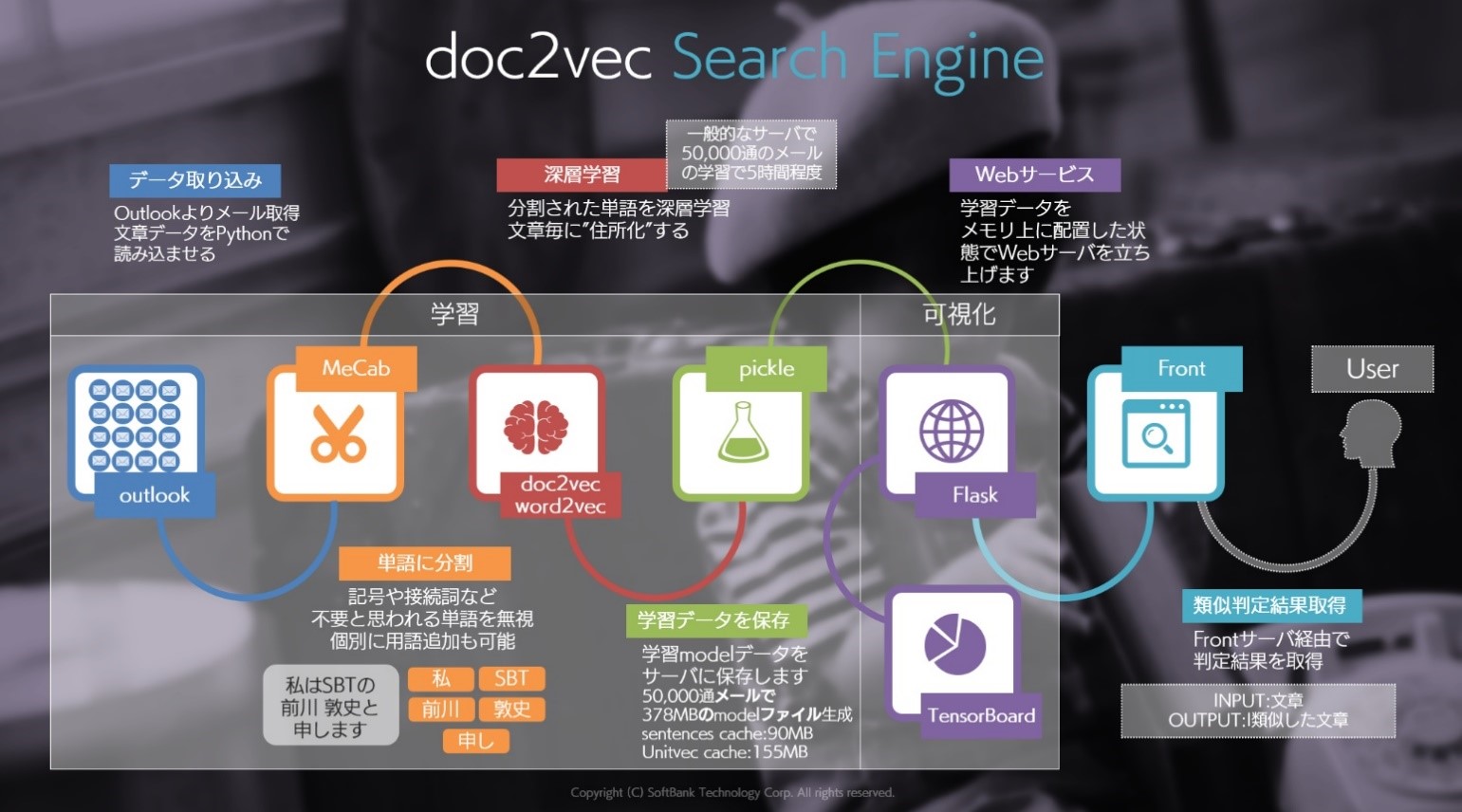
今回の記事では "可視化" と記載された部分をご紹介します。Flask,TensorBoard,Front の部分になります。
当社のご提供する「機械学習導入支援サービス」資料請求・お問い合わせはこちら
こちらのファイルよりソースコードのダウンロードを行います。
sbt_outlook_doc2vec_runserver.zip
ダウンロードしたファイルを解凍して頂き、中身を前回作成した sbt_outlook_doc2vec に移動します。
コマンドプロンプトで解凍後のディレクトリ sbt_outlook_doc2vec に移動してください。
ディレクトリ:sbt_outlook_doc2vec から以下のコマンドを叩いてください。
python runserver.py

* Running on http://127.0.0.1:8000/ (Press CTRL+C to quit)
とまで出れば起動完了となります。
Python の Web フレームワークである Flask が呼び出され Web サービスが立ち上がります。
前回の記事で作成した Doc2Vec 学習モデルを読み込ませた状態で起動しています。
Ctrl+C で終了させる事ができます。
Web サーバへアクセスができるかを確認します。
ブラウザより以下にアクセスをしてください。
http://127.0.0.1:8000/
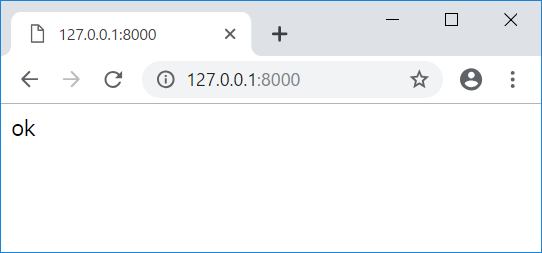
ok と出たら問題ありません
Doc2Vec 学習モデルを読み込ませて起動した Web サーバが正しくレスポンスを返すか確認します。
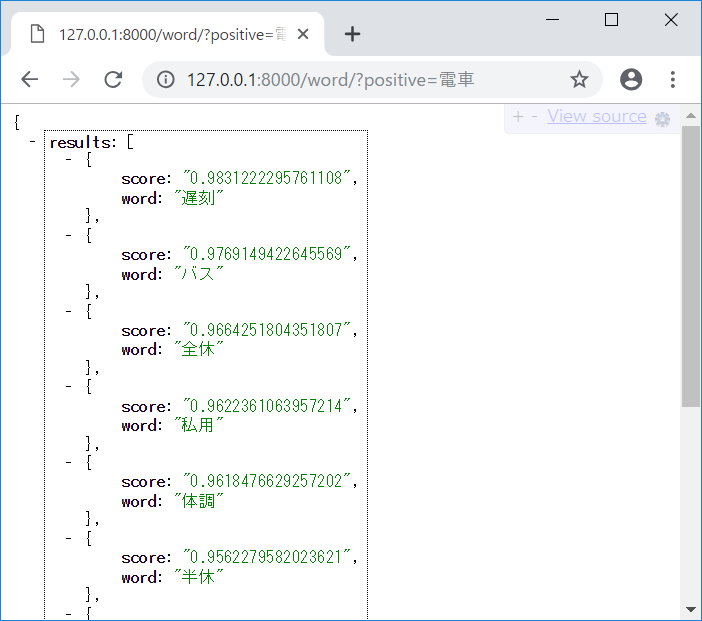
以下 URL の[お好きな単語]の部分を変換していただき URL にアクセスしてください。
http://127.0.0.1:8000/word/?positive=[お好きな単語]
類似度が高い単語順に並んだ単語リストを JSON 形式で返します。
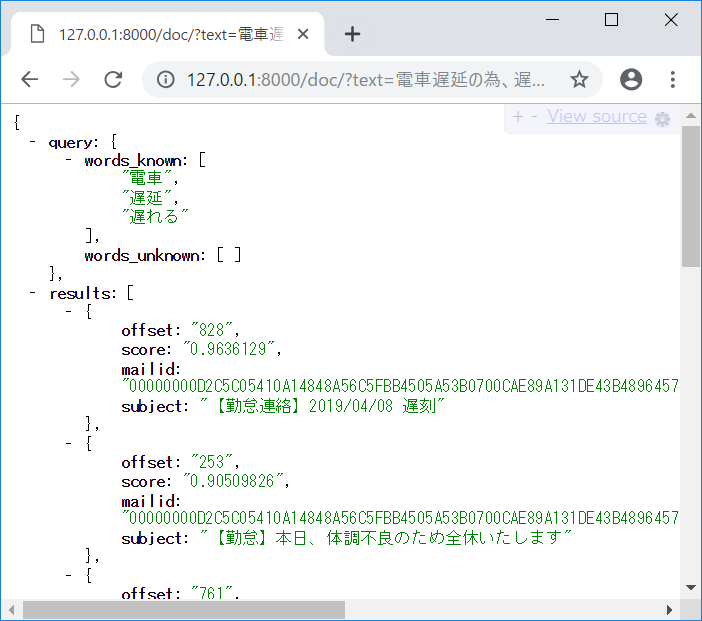
先ほどと同様で以下 URL の[お好きな文章]に変換して頂き URL にアクセスしてください。
http://127.0.0.1:8000/doc/?text=[お好きな文章]
類似度が高い文章(メールの件名)順に並んだ単語リストを JSON 形式で返します。
類似した単語、文章を返す API の動作は確認しました。
この API を利用して WebUI 経由で利用者に提供する事で検索エンジンを作れます。
サンプルとして以下をご用意しておりますのでお試しください。
以下 URL にアクセスしますとこのような画面が表示されます。
http://127.0.0.1:8000/webui/
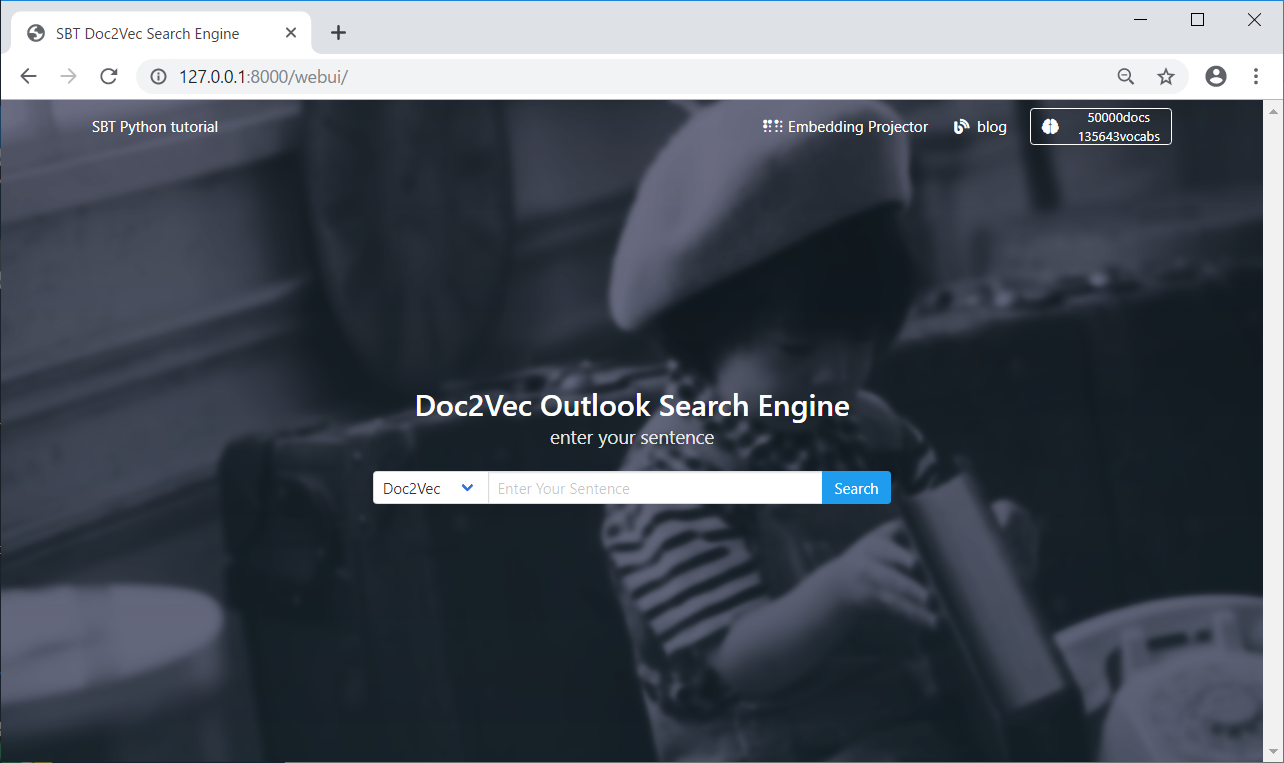
以下のようにフォームに文章を入れて Search を押しますと Doc2Vec の情報を返します。
裏の処理としては 先ほど試した http://127.0.0.1:8000/doc/?text=[お好きな文章] を Javascript 経由で投げています。
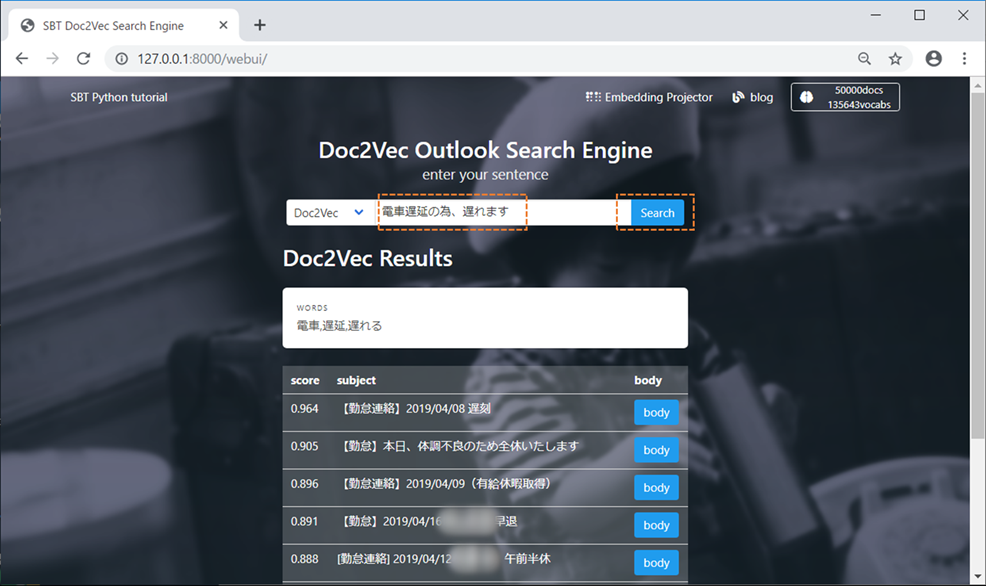
Word2Vec に変更する事で類似単語を返す事も可能です。
Python で動作するライブラリ WordCloud を使用して以下のようにインスタ映えするような画像を出力させたいと思います。その Outlook に入っているメール中から 使用頻度が高いとされている単語を確認する事ができます。
通常は {"softbank":4000 , "技術" : 3000 ....} というようなデータの用意が必要ですが、doc2vec の学習モデルデータを使用する事で簡単に出力する事が可能です。以下のコマンドを入力してください。
python doc2vec_to_wordcloud.py
コマンド入力後、wordcloud.png という以下のような画像ファイルが生成されます。

文章の出現頻度に応じて文字が大きく表示されております。
Doc2Vec の学習モデルから簡単に作成することが可能です。
TensorBoard の Embedding Projector という学習データ可視化ツールを使用して、学習モデルデータの可視化を行います。前回の記事で Doc2Vec の学習データを作る際 data フォルダ配下に Embedding Projector 用の以下データも作成されています。
doc_metadata.tsv.gz , doc_tensor.tsv.gz , word_metadata.tsv.gz , word_tensor.tsv.gz
Embedding Projector の Standalone 版をダウンロードします。以下にアクセス頂きツールをダウンロードしてください。
https://github.com/tensorflow/embedding-projector-standalone
Clone or download → Download ZIP でダウンロード可能です。
embedding-projector-standalone-master フォルダごと sbt_outlook_doc2vec フォルダに解凍し、embedding-projector-standalone-master/oss_data/oss_demo_projector_config.json を以下のように書き換えてください。
{ "embeddings": [ { "tensorName": "Doc2Vec", "tensorShape": [50000, 400], "tensorPath": "../../data/doc_tensor.tsv.gz", "metadataPath": "../../data/doc_metadata.tsv.gz" }, { "tensorName": "Word2Vec", "tensorShape": [200000, 400], "tensorPath": "../../data/word_tensor.tsv.gz", "metadataPath": "../../data/word_metadata.tsv.gz" } ] }
http://127.0.0.1:8000/embedding-projector-standalone-master/
にアクセスしてください。アクセス後以下のようなローディング画面がしばらく表示されます。
ロード完了後です。
成功しますとこのようなインスタ映えするような表示となり住所付けした文章達を可視化できます。学習データのベクトルを3次元に変換して 3D で表示してくれます。
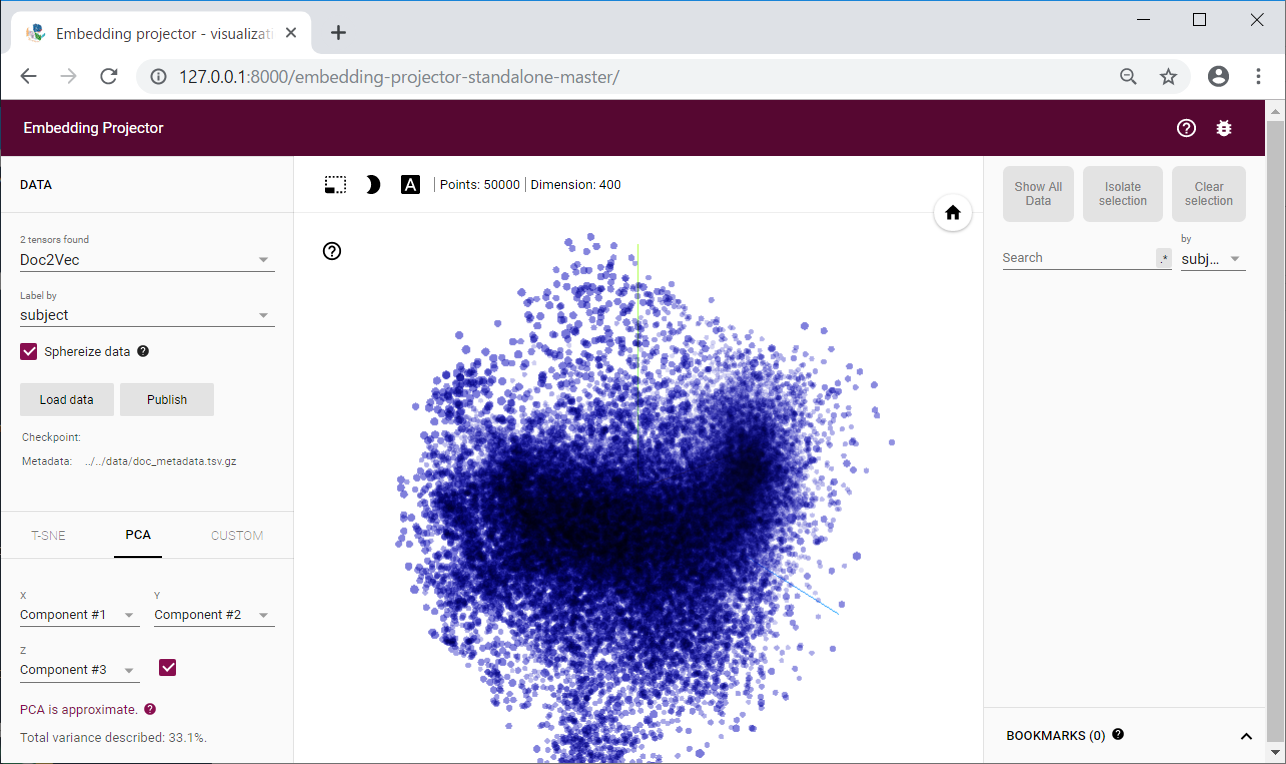
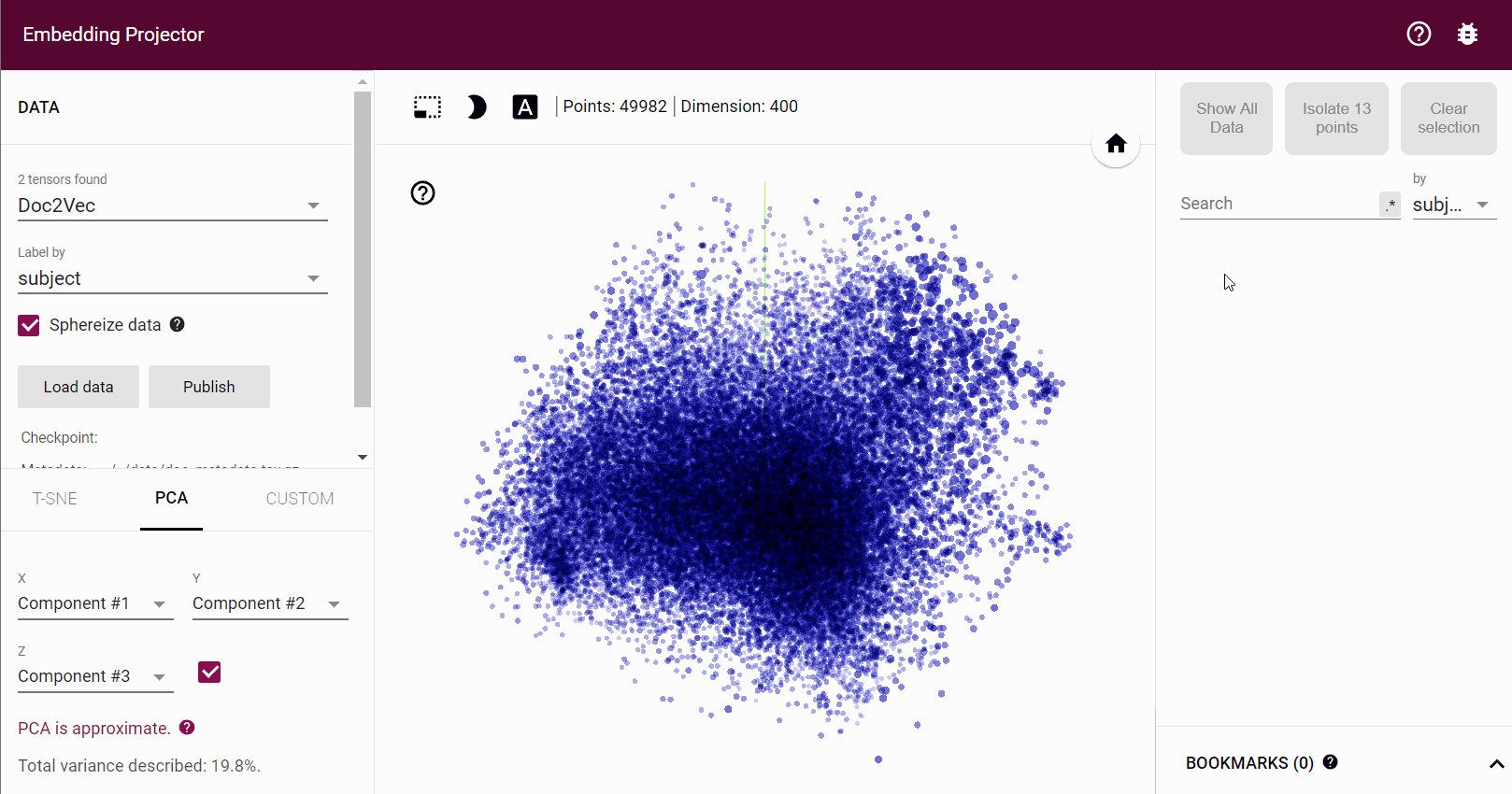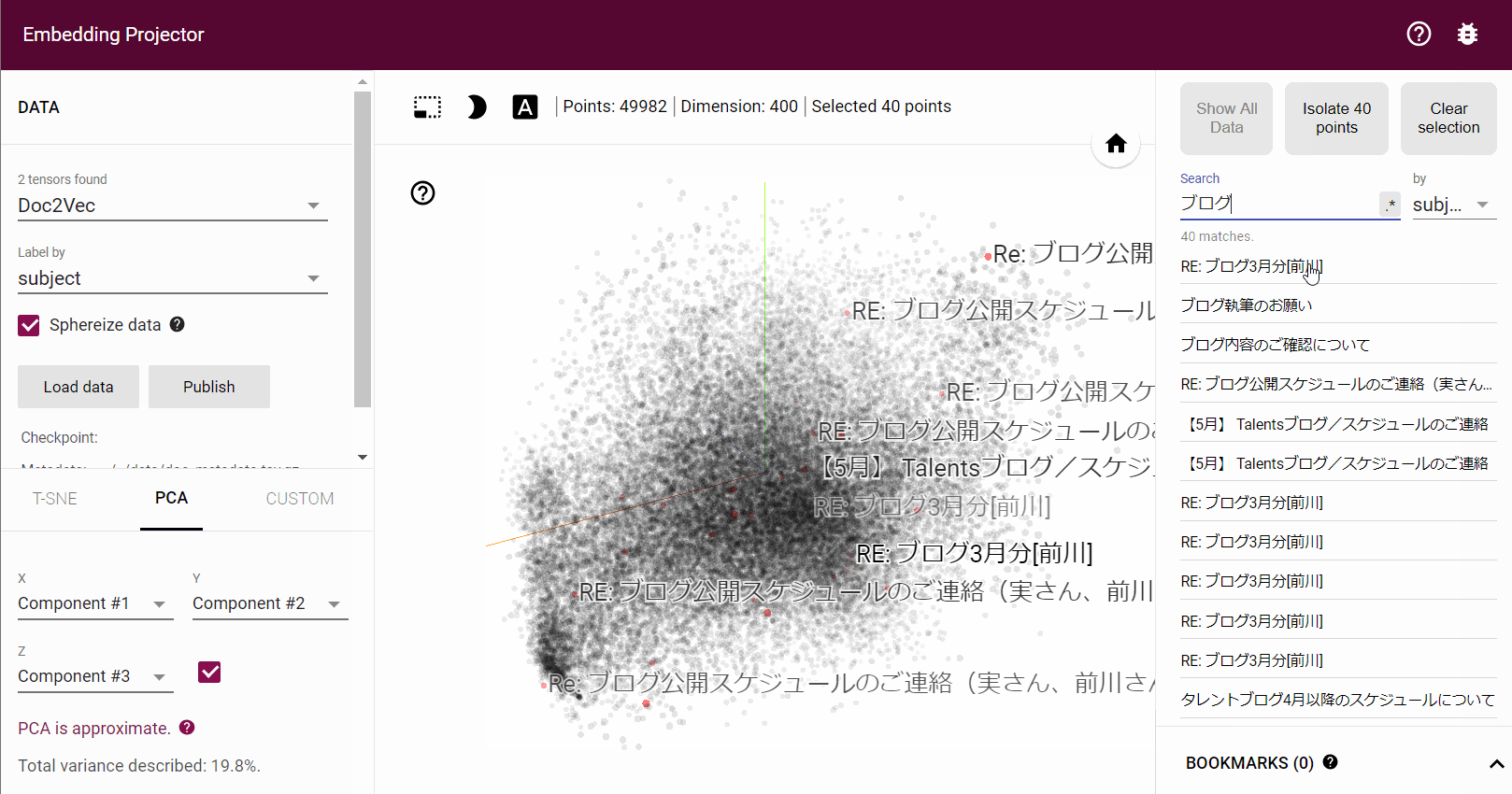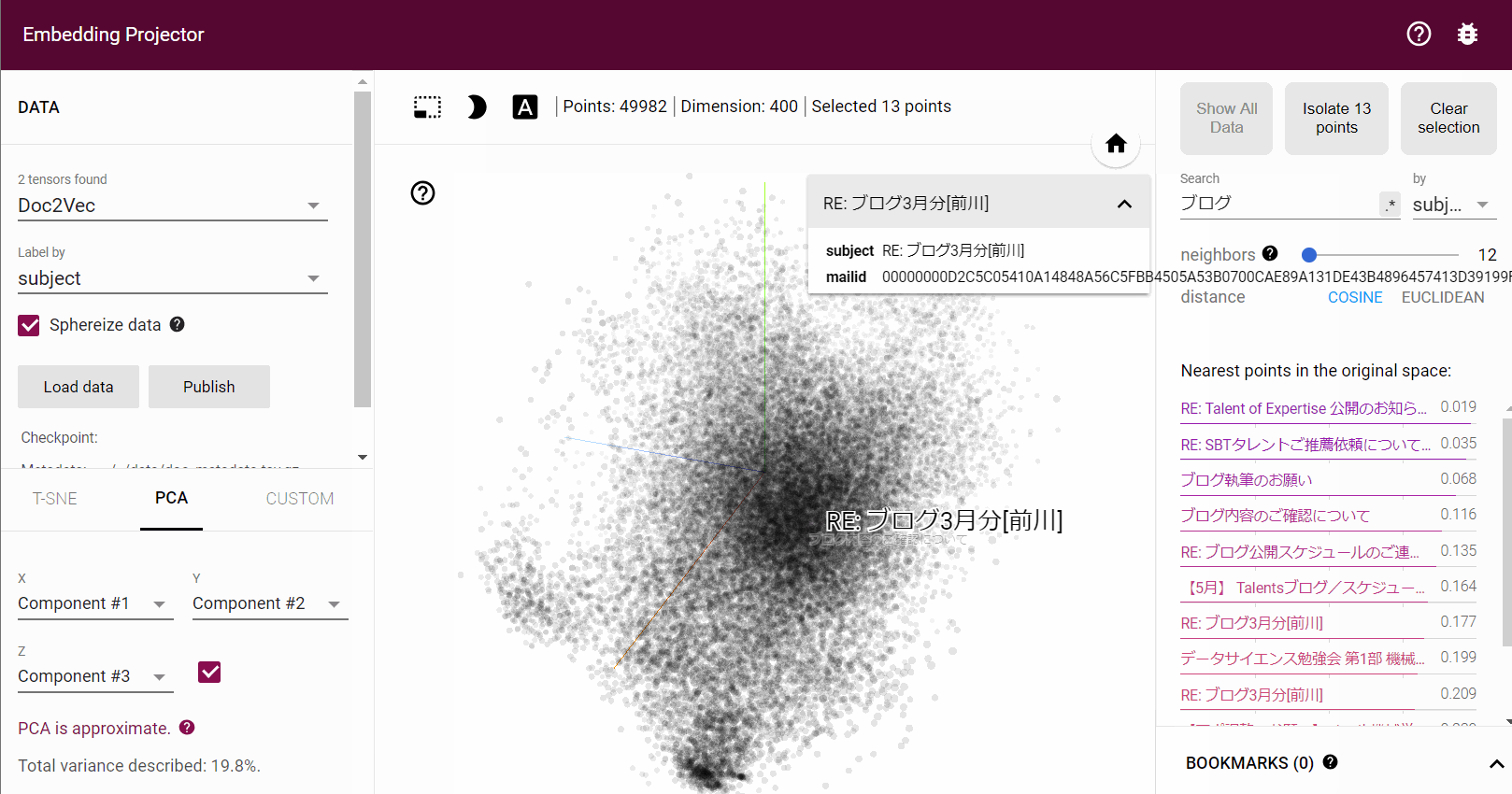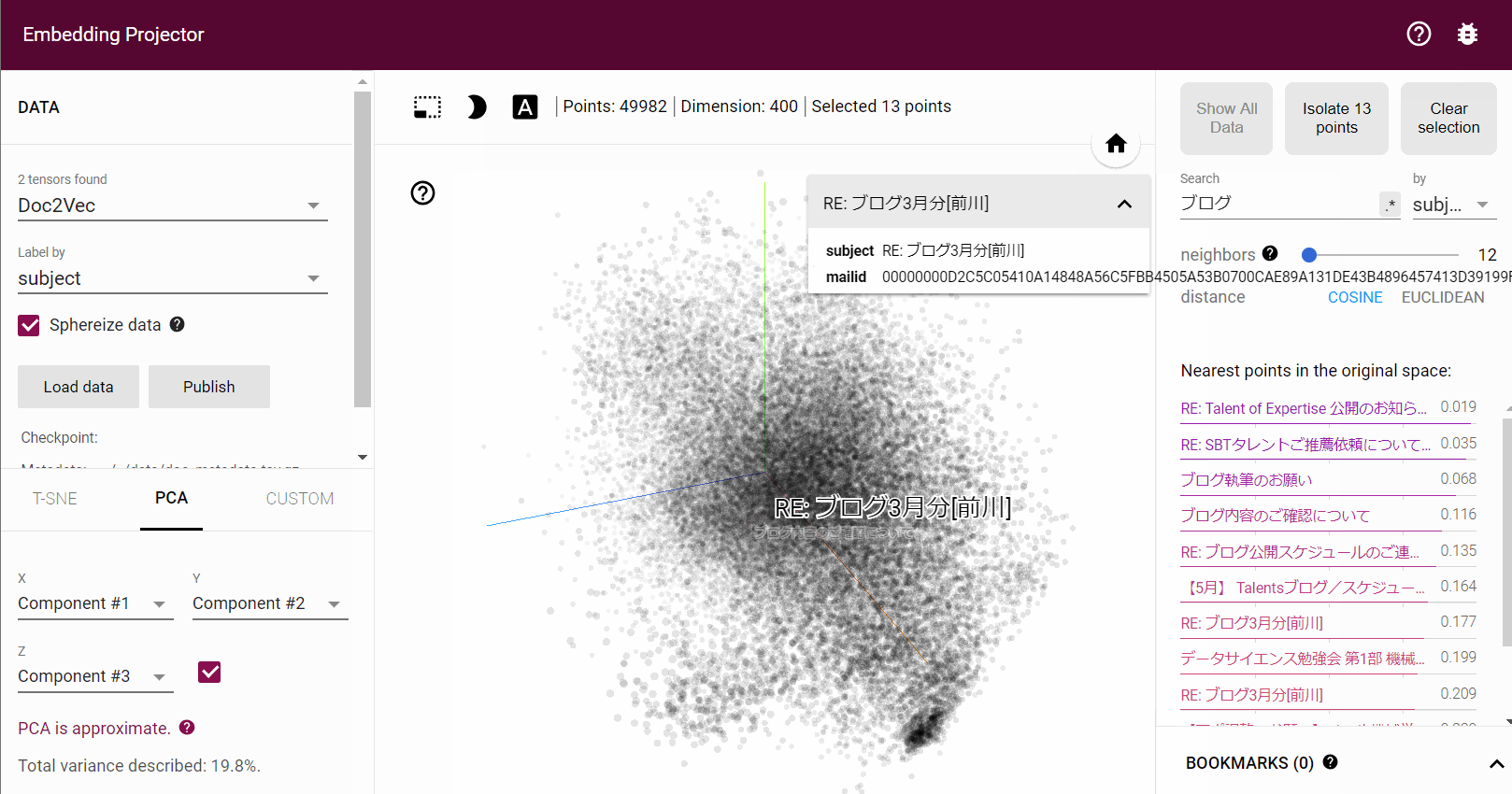
青い点がメール1つになっており、5万件のメールを学習させているので5万個の点が表示されています。右側 Search より検索を行い検索結果からメールを選択するとその文章の情報が表示され、類似した文章の一覧も右に出力されます。
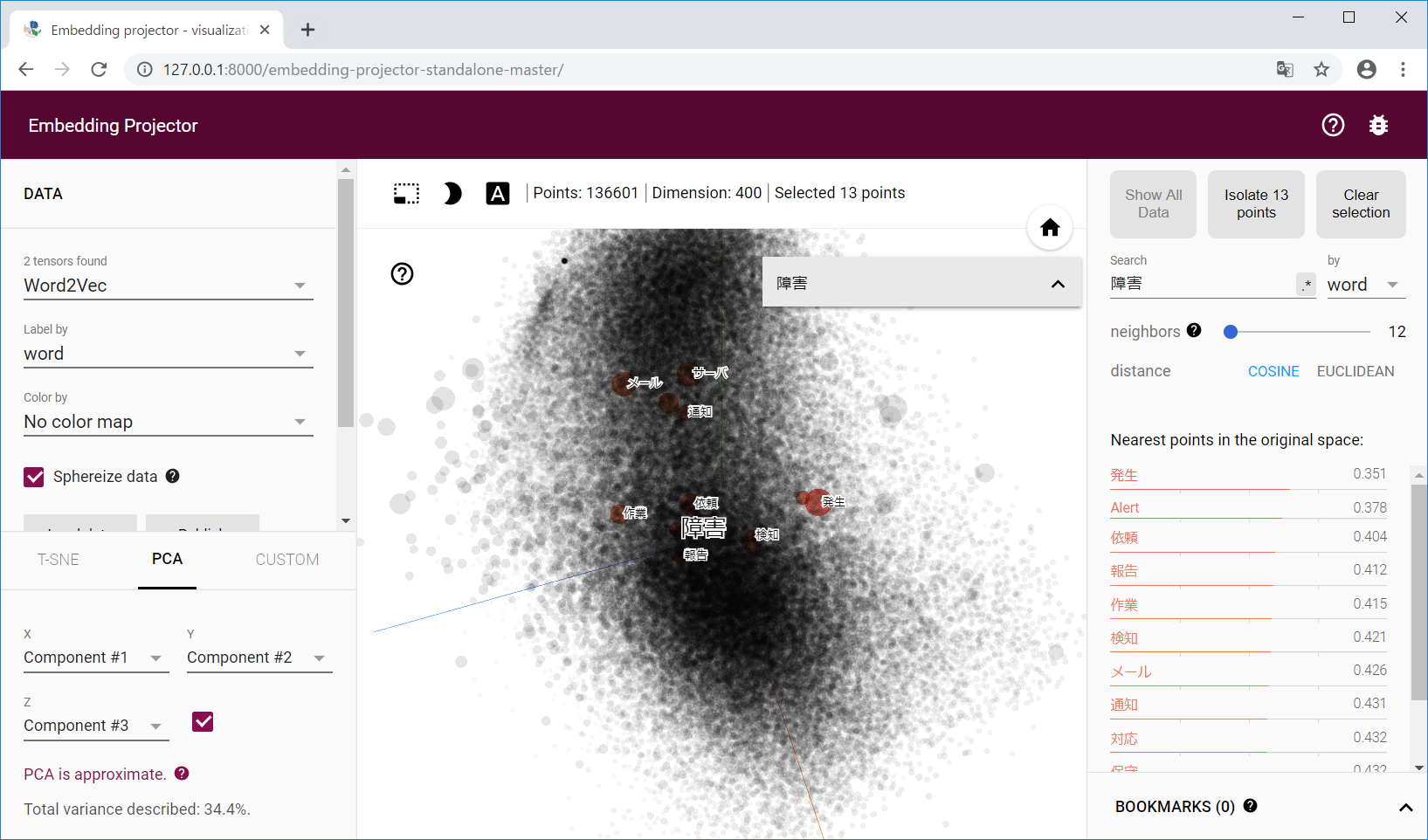
Doc2Vec となっているところを Word2Vec に変更すると単語の関係を可視化する事ができます。
以上で可視化について終了になります。
今回は機械学習を使った運用効率化ツールとして "検索エンジンを作る" をテーマにしました。「で?」という反応とならないよう実データを可視化して見せる事で、それを見た上司や同僚も機械学習を使った運用効率化のイメージが沸きやすくなると思います。
今回のツールで大事なのは「文章に住所を付けて似たような文章を探せるようになった」というところです。検索エンジン以外にもチャットボット、文書分類器、文章入力補助などにも利用できると思いますので、上司や同僚と一緒にいろんな活用方法を探ってみてはいかがでしょうか。
私の記事で実際にプログラムを試して頂けたら嬉しいです。
ご自身のデータで試す事で感覚的に類似している or していないが判断できたのではないかと思います。
数式の理解があるとより精度の高い学習モデルに改良する事ができますが、数式理解があるないに関わらず、学習モデルの精度を繰り返し検証していく事が大事だと考えています。
最初に作った方式はその時使用した学習用データとの相性がよかっただけで、数か月たったら精度が下がっていた というケースはよくありますので、"作ったツールは我が子のように面倒を見る" その気持ちを忘れずに今後も効率化を目指して頂きたいと思います。(私も開発したツールに、自分の子供の名前 = AoI と付けています。WebUI の背景の子です)
次回の記事で "膨大なメールを深層学習して運用効率化ツールを作る" は最終回となります。このプログラムソースの中身を解説しカスタマイズ方法などを記載します。

関連ページ
当社のご提供する「機械学習導入支援サービス」資料請求・お問い合わせはこちら |




