
植林 将樹
こんにちは。データサイエンスチームの植林です。
本記事ではAzure AI Search のベクトル検索機能を用いて、SharePoint Online に格納されたデータを検索するシステムの構築を解説します。
社会のデジタル化が進み、企業の所有する情報量はどんどん増えています。そのため膨大な量の情報から必要なものを迅速かつ高精度に検索することは、日々の業務の効率性を大きく左右します。皆さんも膨大な量のマニュアルや社内ドキュメントから欲しい情報をすぐに手に入れられなかった経験があるのではないでしょうか。そのための強力なサービスして、Azure AI Search (旧称 Azure Cognitive Search)というサービスがあります。Azure AI Search とは、Microsoft Azureが提供している大量のデータから必要な情報を効率的に検索できるサービスです。
Introduction to Azure AI Search - Azure AI Search | Microsoft Learn
2023年11月、Azure AI Search にベクトル検索機能が実装されました。これまでのキーワード検索では、検索単語が文章内の単語と一致している必要がありました。そのため、曖昧な表現による検索が難しい、たまたま同じ単語が使われているまったく別のドキュメントが検索されてしまう等の課題がありました。そこでベクトル検索が実装されたことにより、曖昧な表現による検索や、同じ単語が存在するというだけで引っかからない検索ができるようになりました。
さらに情報やドキュメント検索の次のステップとして、それをもとに新しい情報を生成することが求められる場面も増えてきています。例えば、ユーザーからの質問に社内ドキュメントをもとに回答を作成するケースや、ドキュメントの翻訳、情報抽出、要約などが考えられます。これらのニーズに対して現在注目されているのが、RAG(Retrieval Augmented Generation)システムです。RAGシステムとは、ユーザーの入力に基づいて関連情報を取得し、それをもとにLLMが新しい文章を作成するシステムです。RAGシステムを用いることにより、会話形式で必要な情報を必要な形式で得ることができるようになります。
このようなRAGシステムの基盤として高精度な検索システムがこれまで以上に必要となってきています。これまで、高精度な検索システムを実装することは難易度の高いものとなっていました。Azure AI Searchにベクトル検索が実装された今、この課題は簡単に解決することが可能です。また、ドキュメント内容やそれを元にLLMに回答させた情報だけでなく、参照したファイルの情報を取得したいケースも考えられます。例えば、参照したファイルを直接開くためにファイル名、パス、リンクなどが必要になるケースです。Azure AI Search を利用すればこういったファイル情報も同時に取得できます。本記事では、RAGシステムの構築には欠かせないAzure AI Search のベクトル検索機能を用いて、ファイル共有サービスとしてよく利用されているSharePoint Online に格納されたデータから検索するシステムの構築を解説いたします。
ベクトル検索とは、ベクトル化されたデータの距離や類似性を計算することで検索する手法です。テキストをベクトル化することで、検索文と単語や表現が一致していなくても意味の近いテキストを検索できるようになります。テキストデータを検索する際は、主に3つのステップで処理がおこなわれます。1つ目は、テキストのベクトル化です。テキストデータをベクトル化する手法はいくつかありますが、本記事ではAzure OpenAIの埋め込みモデルである「text-embedding-ada-002」を利用してベクトル化をおこなっています。2つ目は、類似性の計算です。ベクトル化されたデータと検索クエリの距離や類似性を計算します。本記事で紹介するAzure AI Search のベクトル検索機能では、コサイン距離をもとに計算されたパラメーターが使用されています(※1)。3つ目は、検索結果のランク付けです。検索された類似性のランキングを作成し、上位のデータを検索結果とします(※2)。Azure AI Search のベクトル検索機能では先ほど登場したコサイン距離をもとに計算したパラメーターが上位のデータを検索結果として返します。
※1 ベクトル検索 - Azure AI Search | Microsoft Learn
※2 ベクトルの関連性とランク付け - Azure AI Search | Microsoft Learn
Azure AI Searchにはベクトル検索のほかにハイブリッド検索の機能も追加されています。ハイブリッド検索とは、キーワード検索とベクトル検索それぞれで得られたランクを加味し、双方のメリットを生かせる手法となっています。Azure AI Searchのハイブリッド検索機能では、キーワード検索、ベクトル検索で得られたそれぞれのランクを、RRF(Reciprocal Rank Fusion)という計算式に基づいて合体させています(※3)。ベクトル検索を実装するとハイブリッド検索を利用することもできるため、本記事ではこちらの機能についても紹介いたします。
※3 ハイブリッド検索のスコアリング (RRF) - Azure AI Search | Microsoft Learn
SharePoint インデクサー (プレビュー) - Azure AI Search | Microsoft Learn
また、テキストをベクトル化する際にAzure OpenAIリソースを使用します。公式ドキュメントを参考にリソースを作成し、text-embedding-ada-002をデプロイしてください。
操作方法: Azure OpenAI Service リソースを作成してデプロイする - Azure OpenAI | Microsoft Learn
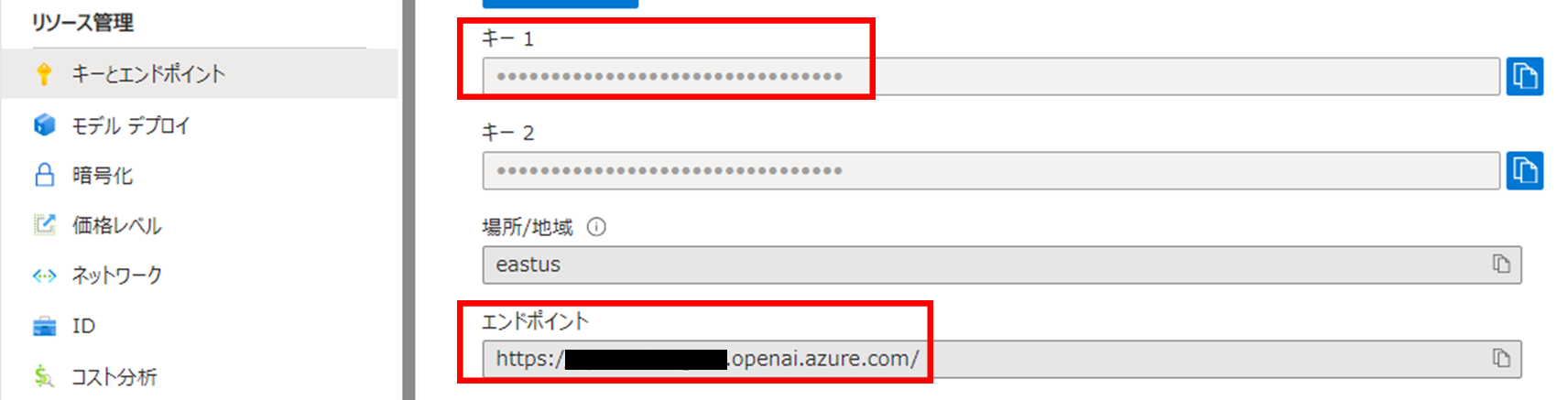
Azure OpenAIリソースを使用するためには、キー、エンドポイント、モデルのデプロイ名が必要になります。Azure OpenAIリソースをポータルから開き、左のメニューから「キーとエンドポイント」に進み、キーとエンドポイントを取得しておいてください。
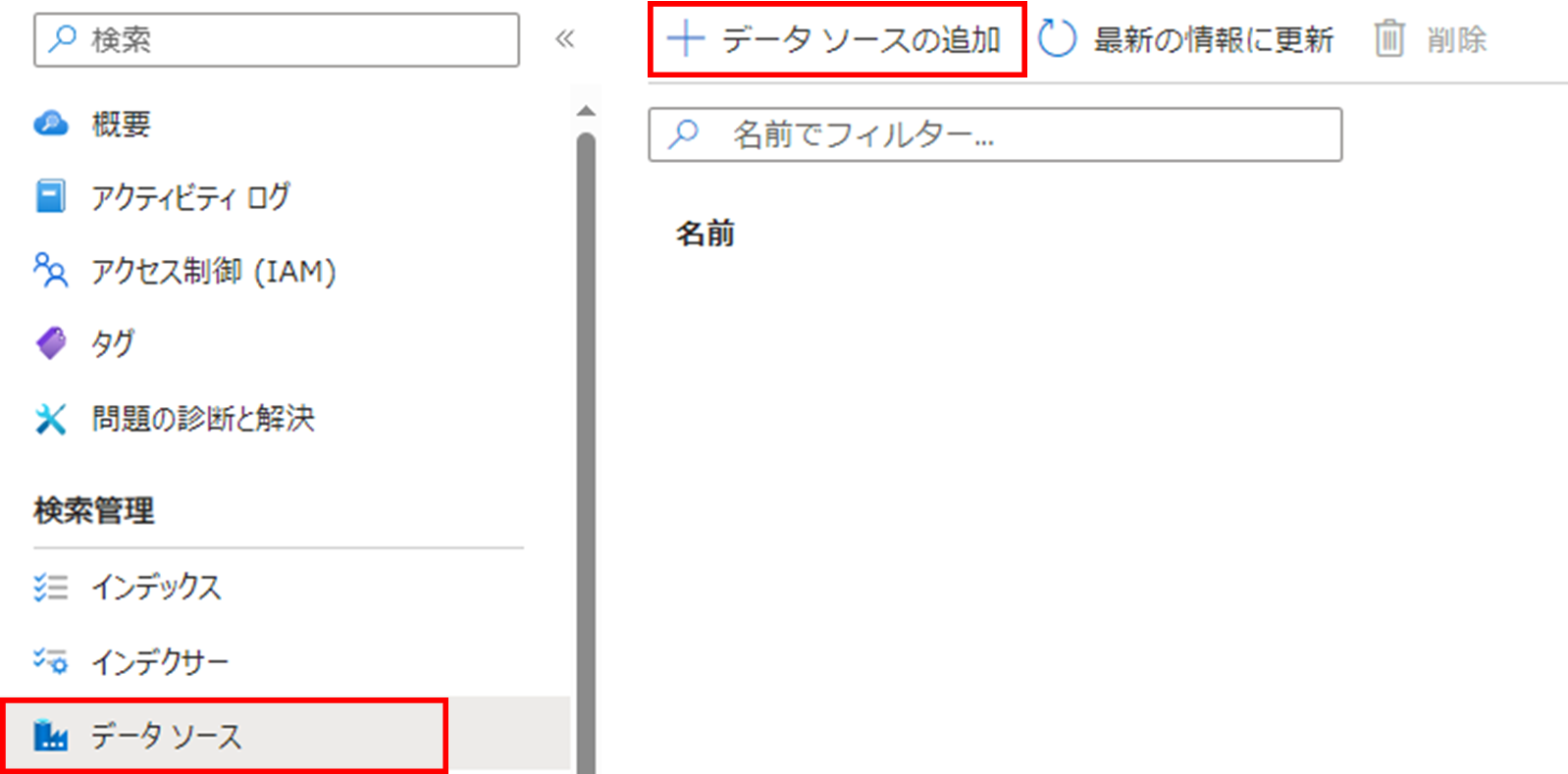
必要な情報を取得できたら、Azure PortalからJSONを入力します。メニューから「データソース」→「データソースの追加」→「データソース定義(JSON)」と進み、下記のJSONを入力し、「保存」を押してください。
nameはデータソース名となるため好きな文字列を設定してください。typeはデータソースの種類を指しているため、今回はsharepointとします。connectionStringには、先ほど取得したアプリケーションID、クライアントシークレット、テナントIDを入力してください。containerにはドキュメント ライブラリを指定します。
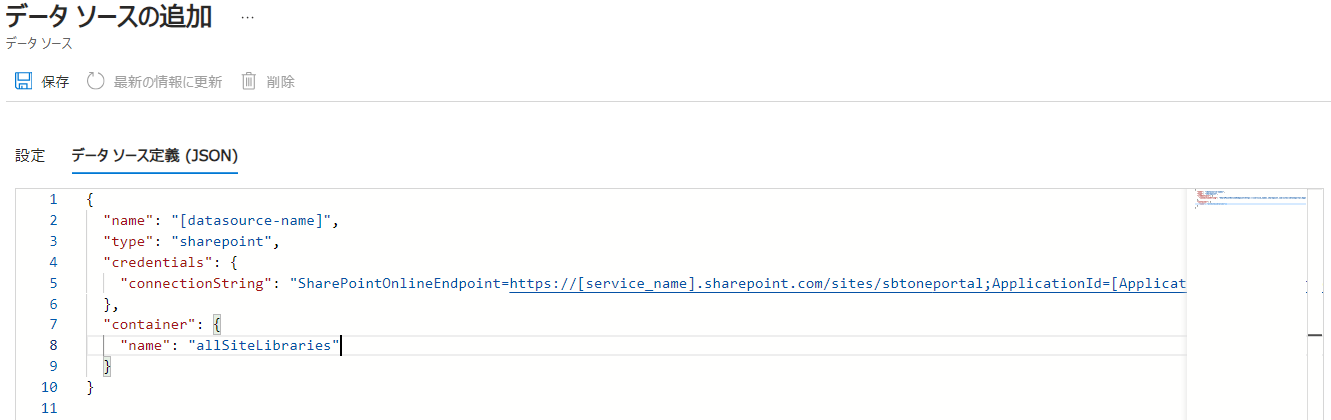
|
|
nameには好きなインデックス名を設定してください。defaultScoringProfileでは下で設定したスコアリングプロファイルを設定しています。fieldsでは、インデックスでどのような情報を持つか定義しています。vectorSearchやprofiles、vectorizersではベクトル検索に必要な情報を設定しています。
|
|
nameには好きなスキルセット名を設定しください。skillsではチャンク分割をおこなうSplitSkillと、ベクトル化をおこなうAzureOpenAIEmbeddingSkillを設定しています。また、このままではチャンク分割されたテキストやベクトルがどのドキュメントのものなのかという情報が失われてしまうため、indexProjectionsで親ドキュメントの情報をインデックスに付与しています。
|
|
|
インデクサーを作成すると実行が始まります。ステータスが成功になれば構築は完了です。

では先ほど作成したインデックスからベクトル検索を実行しましょう。下記のpythonコードで検索結果を取得することができます。
|
|
また、search関数の引数であるsearch_textを空の文字列に設定していますが、ここに入力クエリをそのまま渡すことで、ハイブリッド検索を利用することができます。
実際にベクトル検索がどのような精度を出せるのか、2つのケースで試してみます。検索した文章をそのまま載せてしまうと長くなるため、本記事ではファイルと内容の概要のみ掲載いたします。今回使用したデータは、Wikipediaから取得したAIカテゴリ記事のテキスト280ファイルです。(画像は一部抜粋)
まずは「機械学習とは」というクエリで検索してみます。
キーワード検索の場合、AIカテゴリの記事に機械学習という単語が頻出するためか、機械学習を説明する文章を検索できません。
キーワード検索による検索結果
| スコア順位 | ファイル名 | 引用した部分の概要 |
| 1 | 機械学習.txt | 機械学習の実応用例 |
| 2 | Multi-Step Super-Resolution.txt | Multi-Step Super-Resolutionについての説明 |
| 3 | MLOps.txt | MLOpsの歴史 |
ベクトル検索では、機械学習についての説明に関する文章を綺麗にヒットできています。同じファイル名が複数ヒットしているのは、ベクトル検索用にチャンク分割したインデックスを使用しているためです。
ベクトル検索による検索結果
| スコア順位 | ファイル名 | 引用した部分の概要 |
| 1 | 機械学習.txt | 機械学習についての説明 |
| 2 | 機械学習.txt | 機械学習の定義 |
| 3 | 機械学習.txt | データマイニングとの関係や機械学習の理論に関する説明 |
ハイブリッド検索では、入力クエリが短かったためか、ベクトル検索とあまり変わらない検索結果となりました。
ハイブリッド検索による検索結果
| スコア順位 | ファイル名 | 引用した部分の概要 |
| 1 | 機械学習.txt | 機械学習についての説明 |
| 2 | 機械学習.txt | データマイニングとの関係や機械学習の理論に関する説明 |
| 3 | 機械学習.txt | 機械学習の定義 |
次に、「AIが人間を滅ぼす恐れ」というクエリで検索してみます。
キーワード検索では、やはり目当ての文章がヒットしません。「AI」や「恐れ」という単語が引っかかったのか、人工知能やディープラーニングを欺く手口に関する文章がヒットしました。
キーワード検索による検索結果
| スコア順位 | ファイル名 | 引用した部分の概要 |
| 1 | 人工知能.txt | 人工知能という単語についての説明 |
| 2 | 人工知能.txt | 人工知能に関する著書一覧 |
| 3 | 天網.txt | 中国でディープラーニングを欺く手口が挙げられた件に関する説明 |
ベクトル検索では、クエリに該当する文章がヒットしました。単語が一致していなくても検索できるというメリットがよく表れています。
ベクトル検索による検索結果
| スコア順位 | ファイル名 | 引用した部分の概要 |
| 1 | 人工知能の倫理.txt | 著名人のAI兵器に関する警告の紹介 |
| 2 | 汎用人工知能.txt | 汎用人工知能による失業の影響に関する説明 |
| 3 | 汎用人工知能による人類滅亡のリスク.txt | AIが人類に及ぼすリスクに関する説明 |
ハイブリッド検索では、ベクトル検索よりもさらにクエリに該当する文章が上位にヒットしています。「人間」や「滅ぼす」という単語が引っかかったのか、単語一致で検索できるキーワード検索と、意味の近い文章を検索できるベクトル検索両方の良い側面が出た結果となりました。
ハイブリッド検索による検索結果
| スコア順位 | ファイル名 | 引用した部分の概要 |
| 1 | 汎用人工知能による人類滅亡のリスク.txt | AIが人類に及ぼすリスクに関する説明 |
| 2 | 汎用人工知能による人類滅亡のリスク.txt | 知能爆発のシナリオに関する説明 |
| 3 | 人工知能の倫理.txt | 著名人のAI兵器に関する警告の紹介 |
当社では現在、dailyAIというサービスを提供しています。dailyAIは手元のデータをアップロードするだけで簡単に要約や修正、分析が実施できるRAGサービスです。すぐに使い始めることができ、トークン利用料や従業員の利用ログを管理できる仕組みもございます。また、セキュアな環境で構築し、安心して利用いただけます。
さらにdailyAIでは、本記事で紹介したベクトル検索やハイブリッド検索を用いて、SharePoint Online 上の社内ファイルから回答を生成するプランもご提供しています。
ご興味がございましたら、お気軽にお問い合わせください。
本記事ではSharePoint Online のデータからAzure AI Searchのベクトル検索機能の構築を解説しました。ベクトル検索を簡単に実装できることが本記事の紹介で少しでも伝われば幸いです。膨大な量のデータを扱わなければならない時代に、速く正確に情報を見つけられるかは、業務効率を改善するにあたって重要な要素となっています。また、企業や組織が持つ情報の価値を最大限に引き出すためには、適切な検索とアクセスが必要不可欠です。本記事で紹介したベクトル検索機能はこれらの問題の解決に大きく貢献することができます。RAGシステム導入をご検討されている方は、Azure AI Search のベクトル検索機能の利用をご一考されてはいかがでしょうか。構築が難しいとお考えの方はぜひ、当社のdailyAIをご検討ください。また、当社ではdailyAI以外にも、自然言語解析を用いたAI活用支援や、手軽にアンケート分析が実施できるCogEraを用意しております。ご興味がございましたら、お気軽にお問い合わせください。最後までお読みいただきありがとうございました。
関連ページ
日常的に簡単・手軽に使用できる生成 AI サービス「dailyAI」サービス詳細はこちら |