こんにちは。データサイエンスチームの大山です。
本ブログでは、Microsoft 社が提供する機械学習プラットフォームサービスである Azure Machine Learning (Azure ML) に関して、その機能を紹介する記事を過去にもいくつか投稿しています。今回は Azure ML の機能の中でも、AutoML Computer Vision 機能について解説していきたいと思います。本記事は前編として、当該機能の概要と全体的な機能の説明を中心に解説し、実操作や手順の解説は後編で行う予定です。
なお、Azure ML や AutoML機能全体についての解説は、以下の記事でも簡単に紹介していますので、そちらも合わせて参照いただければ幸いです。
Azure ML の AutoML Computer Vision は、自動機械学習によるモデルの探索技術を用いて、画像認識に関する機械学習モデルの構築が出来る機能です。後ほどより詳細に解説しますが、本機能が対応しているタスクは、分類 (マルチラベルも対応)、物体検知、インスタンスセグメンテーションとなっており、自動機械学習系の機能としては比較的多くのタスクに対応していると言えます。
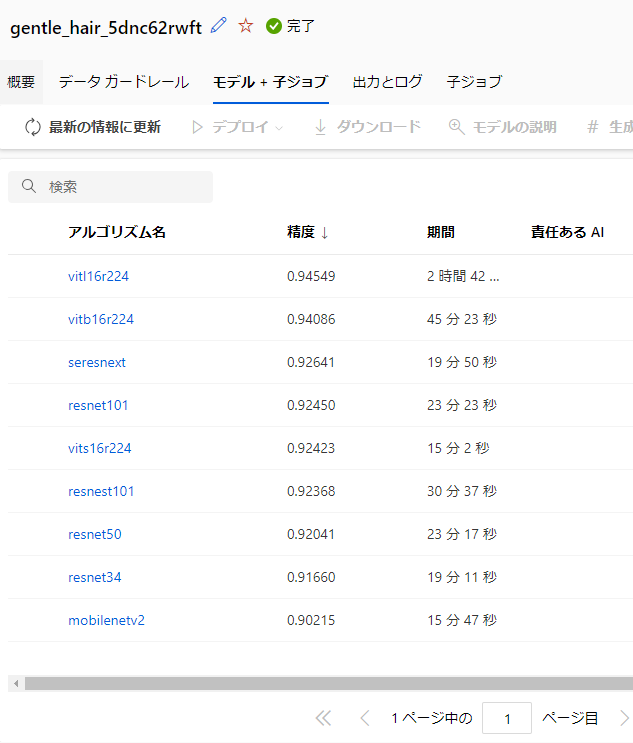
本機能を利用すれば、複数のモデルやハイパーパラメータの組み合わせについて、コンピューティングクラスターによる並列での学習処理による探索を行うことができ、ノードの起動と終了も自動で行うことが可能です (以下は、本機能によって複数のモデルを学習し、精度を比較した例となります。)
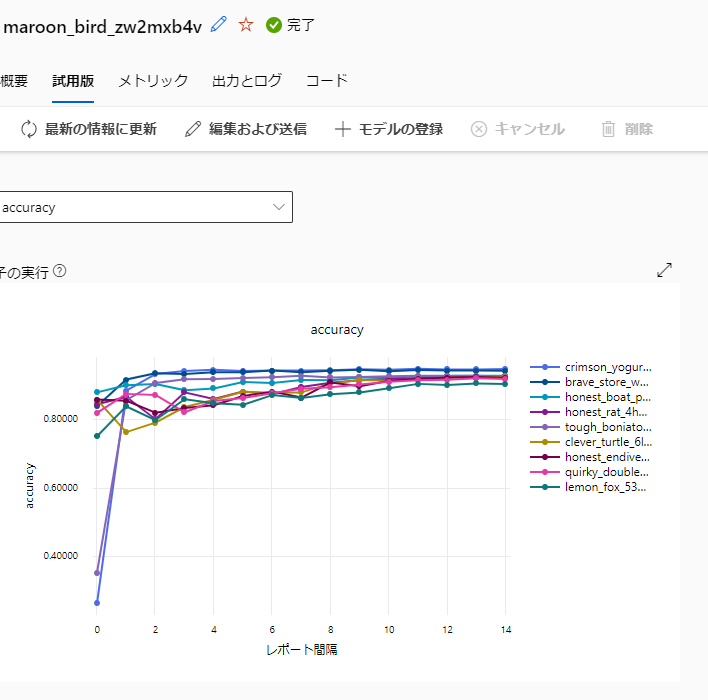
学習したそれぞれのモデルの比較のための UI も搭載しており、例えば各モデルの学習曲線について学習処理中にリアルタイムで確認することができます (以下の画像は、探索した複数のモデルについて学習曲線を確認した例です。)
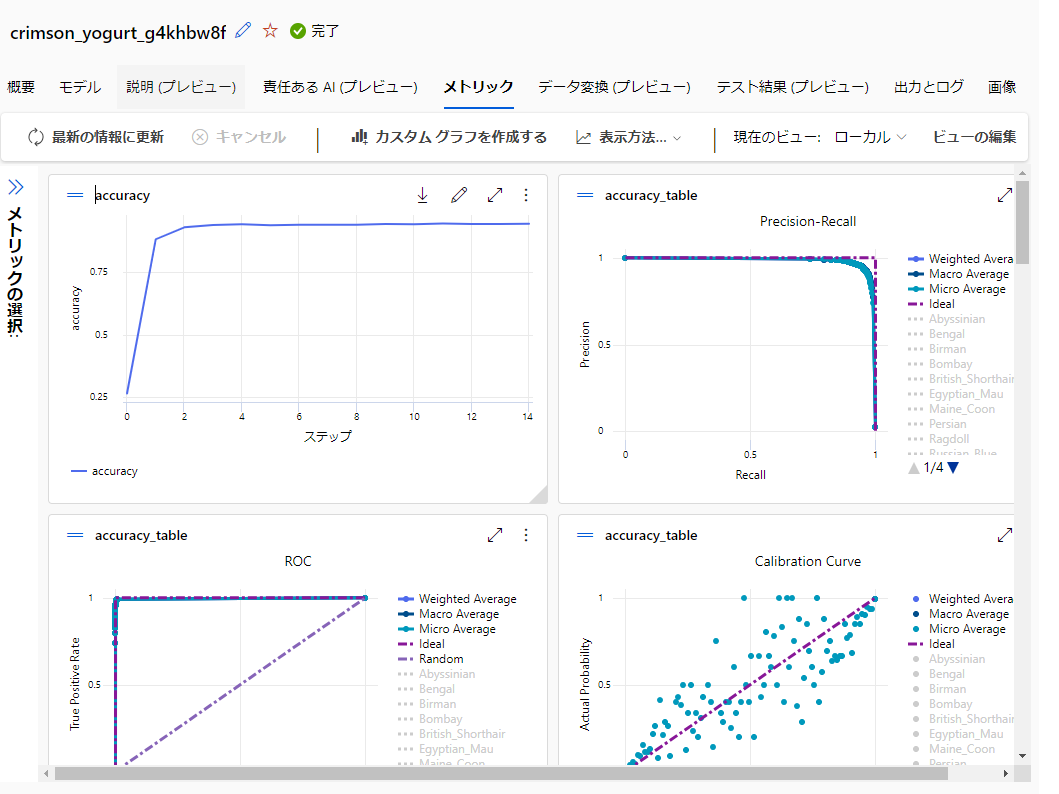
また、各モデルの詳細な評価結果についても、以下の様なグラフがジョブの履歴として作成されるため、様々な角度からモデルの詳細を確認することが可能です。
なお、AutoML 全体の仕組みや、Computer Vision 以外のタスクについての詳細を知りたい方は、以下の公式リファレンスについても参照いただければと思います。
AutoML Computer Vision は、以下の画像認識に関する機械学習タスクに対応しています。
**********【補足】**********
画像認識におけるセグメンテーションのタスクには、他にセマンティックセグメンテーション (セマンティック:「意味の、意味論の」 を指す英語) と呼ばれるタスクがあります。これは、画像内の各ピクセルについて、そのピクセルがどのラベルなのかを識別するタスクです。インスタンスセグメンテーションとの違いは、画像内の個々の物体の識別を行わないという点です。例えば、複数の犬が写っている画像の場合、別々の犬であっても、犬が映っている領域のピクセルは単に犬とだけ分類されます。
一般に、セマンティックセグメンテーションとインスタンスセグメンテーションを比較すれば、後者の方が難しいタスクとなります。ただし、個々の物体を識別する必要がない対象、例えば、海とか空とかの領域を検出したい場合であれば、セマンティックセグメンテーションが有効な手法となります。
なお、Azure ML の AutoML は、このセマンティックセグメンテーションのタスクに対応していません。
************************
以下の画像は、公式リファレンスにて引用されている、Azure ML の AutoML Computer Vison が対応している各タスクの出力イメージ画像です。

画像引用元: http://cs231n.stanford.edu/slides/2021/lecture_15.pdf
このインスタンスセグメンテーションにも対応している点は、AutoML Computer Vision と、他 Azure の Computer Vision 系サービス (Custom Vision や Azure AI Computer Vision) の違いとして挙げられます。
また、こういった自動機械学習系のサービスでは、モデルや設定が非公開である場合や、変更できる設定が制限されていて自由度が少ない場合も多いですが、本サービスは、利用するモデルやハイパーパラメータの設定値がほぼ全て開示されており、それら設定のほとんどが変更可能であるという点も特色となっています。これらの特色は、機械学習による Computer Vision に関してある程度知見を持っているユーザーにとっては、細かい設定や比較が可能となるため好ましい点ではないかと思います。
本機能と類似した Azure のサービスに、Azure AI (旧 Azure Cognitive Services) として提供されている、Azure AI Custom Vision および Azure AI Computer Vision (Image Analysis 4.0) が挙げられます。両サービスともに、ユーザーのデータから画像認識モデルを構築できるサービスです。
Azure AI Computer Vision (Image Analysis 4.0) は、Custom Vision の後継サービスのため、機能的には重複している点が多いです。違いとしては、バックエンドで利用されているモデルが異なることによる、精度や学習に必要な最小画像数の違いが挙げられます (公式リファレンスには、Custom Vision は、CNN ベースのモデル、Computer Vision (Image Analysis 4.0) は、Transformer ベースのモデルと記載されています)。また、Computer Vision (Image Analysis 4.0) の方は、2024年4月24日時点ではまだプレビュー提供中であることや、エッジ上での推論など、Custom Vision が提供している一部機能に未対応といった制約が存在しています。
もし、Azure AI Custom Vision と Azure AI Computer Vision (Image Analysis 4.0) の違いについて詳細を知りたい方は、以下の公式リファレンスについても参照いただければと思います。
ユーザーが用意した画像を用いて、分類および物体検知のカスタムモデルが作成できるという機能だけを見ると、これら Azure AI のサービスは、AutoML の Computer Vision とかなり似たサービスに思えます。しかしながら、実際に利用してみると両サービスの間にはかなり違いがあり、以下にまとめたように、特に対象としているユーザー層や利用に適したシーンが異なっていることが分かります。
| 対象 | 機械学習やComputer Vision にそこまで詳しくないユーザー |
| 変更可能な設定 | ほとんどない (例:Custom Vision では画像のドメイン領域の指定程度) |
| 適した用途 | 手元の画像データを使って、機械学習による Computer Vision モデルの作成を手軽に始めて見たい場合に適している |
| 対象 | 機械学習やComputer Vision にある程度詳しいユーザー |
| 変更可能な設定 | コーディングする場合と大差ないほどの自由度 |
| 適した用途 | 様々なモデルやハイパーパラメータを比較検討したい場合など、本格的な Computer Vision モデルの構築プロジェクトに適している |
特に AutoML Computer Vision の大きな特徴として、様々な設定を自由に変えられる点が挙げられます。学習に関するハイパーパラメータや、計算に使うコンピューティングクラスターのサイズなど、学習処理に関係する各種設定の多くについて、ユーザー自身で細かく指定することができます。また、自動機械学習で探索する条件についても、様々な条件を指定することが可能です。
一方、こうした細かい設定は、Azure Machine Learning や Computer Vision 関連のモデル構築について、そこまで詳しくないユーザーにとっては、取り扱いが難しい印象を与えてしまうかもしれません。そういった観点から見ても、AutoML Computer Vision は、ある程度知見を持っているユーザーが、Computer Vision モデルの検証を様々な条件について探索するような場面で、有効に利用することができるサービスであると言えるかと思います。
それでは、AutoML Computer Vision に関する概要の説明は以上にして、次の節ではもう少し詳細なサービスの仕様について解説していきます。
本節では、AutoML Computer Vision の機能を使うときに準備するデータの仕様や、モデルに関する設定の内容について解説します。具体的な操作手順の解説(モデル構築手順の解説など)については、【後編】の記事にて紹介予定です。
本節では、以下の順番で AutoML Computer Vision の仕様について解説していきます。
なお、本節の執筆の際は、以下の公式リファレンスの記述を主に参考にしつつ、トピックごとに個別のリファレンスの内容を適宜参照しています (日本語版のリファレンスの注意点として、一部操作の手順が記載されていないなど、少し分かりづらい部分があるため、英語のリファレンスも参照することをお勧めします)。
また、Azure ML 自体の概要や基本的な操作方法については、必要に応じて以下の公式リファレンスや、過去ブログを参照ください。
Azure ML と AutoML に関する公式リファレンス
AutoML Computer Vision を用いて画像認識モデルを構築する際は、以下の2種類のデータを用意する必要があります。
まず、前者の画像データについては、JPEG 形式や PNG 形式の通常のファイルで問題ありません (公式リファレンスでは、「Pillow ライブラリで使用可能なすべての画像形式がサポートされています」と記載されています)。一方、画像のアノテーションデータは、以下に記載するいずれかの手順で用意することになります。
もし、対象のデータ数が多くなく、手動でのラベル付けやアノテーションが可能なのであれば、Azure ML のラベル付け機能を用いるのが最も容易な方法です。本機能を用いれば、対象画像のクラウド上へのアップロードとラベル付けしたアノテーションデータのデータアセットへの登録まで、Azure ML の UI (Azure ML Studio) 上の操作で行うことができます。
Azure ML のラベル付け機能を利用する方法については、当社ブログの過去の記事にて解説していますので、興味ある方は以下の内容も参照いただければと思います。
また、Azure ML ラベル付け機能の公式リファレンスは、以下のページとなります。
一方で、既存のアノテーション済みデータを利用する場合や既にアノテーションデータが別途存在している場合は、当該アノテーションデータについて、AutoML Computer Vision が対応している JSONL 形式のデータに変換する必要があります。
まず、JSONL (JSON Lines) とは何かというと、改行区切りで1レコードごとに JSON が格納されているデータ形式のことです。例えば、以下の様なテキストデータは、JSONL 形式のデータであると言えます。
{“id”:”00001”,“name”:”Ritchard”,”attribute”:{”age”:25,”favorite”:”bongo”}}
{“id”:”00002”,“name”:”Werner”,”attribute”:{”age”:42,”favorite”:”piano”}}
{“id”:”00003”,“name”:”Paul”,”attribute”:{”age”:41,”favorite”:”science fiction”}}
AutoML Computer Vision の場合、各レコードの JSON の内容が 1 枚の画像のアノテーション情報に対応する様に、データを整形する必要があります。JSON レコードのデータスキーマは、公式リファレンスに記載されており、例えば画像分類の場合、以下の様な JSON 形式になります。
{
"image_url":"azureml://subscriptions//resourcegroups//workspaces//datastores//paths/",
"image_details":{
"format":"image_format",
"width": "image_width",
"height":"image_height"
},
"label":"class_name"
}
この内、重要なのはimage_url と label で、それ以外は optional の Key です。
image_url は、当該画像が保存されているネットワーク上の URL です。上記の JSON の URL の形式 (azureml://XXX) は、Azure ML に登録済みのデータストア上に格納されているデータの URL フォーマットです。公式リファレンスでは image_url について、Azure ML に登録済みのデータストア上のデータに関する説明のみなされており、その他のネットワーク上のデータに関する説明については確認できませんでした。
一方、labelは、当該画像のラベル (例:dog、catなど) の情報で、ここが付与したアノテーションの情報となります。label の形式は、タスクごとに異なっており、複数クラスでは上記した例の様に単一のテキスト、複数ラベルの場合はラベルのリスト (例 [“dog”, “cat”, …] など)、物体検出では Bounding box のラベルと座標の辞書となります。
タスクごとの JSON スキーマについては、以下の公式リファレンスに記載がありますので、詳細を確認したい場合は、こちらも参照いただければと思います。
独自のアノテーションデータを用いる場合は、そのデータについて上記した JSON 形式に合う様にアノテーションデータを変換し、その JSON を 1 レコードとして保存した JSONL 形式のデータを作成することになります。pascal VOC や COCO など、有名なデータセットのアノテーションデータの形式については、Microsoft が Python で作成されたヘルパースクリプトを用意しているため、それを利用して変換することも可能です。
とはいえ、必要な JSON スキーマ自体は特に複雑なものではないため、変換する処理を自身が得意なプログラム言語で作成してしまい、それで変換してしまうのが早いかと思います。
アノテーションデータを JSONL で用意できたら、画像データと合わせて両データを Azure 上にアップロードしていきます。この際、画像データは Azure ML に登録済みのデータストア上に保存することが推奨されているようです。画像データは単にアップロードのみ行えば問題なく、Azure ML のデータアセットへの登録操作は特に必要ありません。
一方で、JSONL のアノテーションデータについては、Azure ML のデータアセットに MLTable として登録する必要があります。この仕様が若干ややこしいのですが、Azure ML 上で MLTable データアセットを登録するには、データ本体 (今回の場合は JSONL ファイル) に加えて、そのデータのスキーマを定義するメタデータ (YAML 形式のファイル。ただし拡張子は無し) を作成して、その両データを共にアップロードする必要があります。
例えば、ローカルPC上で分類モデル用に JSONL を作成した場合は、以下の内容の YAML 形式のファイルを作成した上で、名称を MLTable に設定し、JSONL ファイルと同じディレクトリに保存しておきます。その上で、当該ディレクトリを Azure ML のデータアセット登録の操作でアップロードすることにより、アノテーションデータが Azure Computer Vision から利用できる MLtable データとして登録されます。
paths:
- file: ./{JSONL ファイル名}.jsonl
transformations:
- read_json_lines:
encoding: utf8
invalid_lines: error
include_path_column: false
- convert_column_types:
- columns: image_url
column_type: stream_info
ここまで解説した様に、AutoML Computer Vision のデータ周りの仕様は少し複雑な面があります。そのため本節では、Auto ML Computer Vision のデータの仕様について、ある程度詳しく解説してみました。ここまで説明した、データの仕様については、以下の公式リファレンスにも説明がありますので、必要に応じて参照いただければと思います。
AutoML Computer Vision では、自動機械学習で探索対象とするモデルのハイパーパラメータについて、かなり詳細に設定することが可能です。ただし、かなり数が多いことから、Azure ML Studio の UI からの操作する場合でも、ユーザーが当該パラメータの名称を公式リファレンスで調べた上で、テキストでその文字列を入力して値を指定する仕様になっています (プルダウンから変更可能な設定値を選択する、もしくは変更したい設定値をチェックボックスで選ぶといった仕様にはなっていません。)。
変更可能なハイパーパラメータを知りたい場合は、以下の公式リファレンスを参照いただければと思います。
とはいえ、各ハイパーパラメータには、ある程度妥当と思われる Default の値が指定されているため、あまり Computer Vision に詳しくないユーザーが利用する際は、Default 値を特に変更せず、そのまま利用してもそこまで問題は生じないかと思います。自動機械学習によるパラメータ探索についても、どのパラメータを探索させるかまで完全に AutoML に任せてしまうことが可能なので、性能がそれなりに良いモデルをすぐに使いたいといった状況であれば、細かなハイパーパラメータの設定は行わずに、モデルの探索を実行するといった利用の仕方もできます。
しかし、どのようなパラメータが変更可能なのかについては、公式リファレンスを参照して大まかにでもイメージを持っておくと、本機能をより活用できるだろうとも感じます。また、以下に述べる様に、ハイパーパラメータによっては実行時のエラー要因となる場合もあるため、そういったトラブルシューティングを行う際に、ハイパーパラメータに関する知見が必要な場合もあります。
実際、本ブログを書くために検証した際は、特定のモデルで CUDA error: out of memory. のエラーが発生してジョブが失敗してしまうことが起きました。これは、Default で指定されている学習時のミニバッチの値が大きすぎることにより GPU の VRAM 容量を超えたデータが VRAM に載ろうとして、処理が停止したことを示すエラーです。深層学習モデルの学習処理では比較的よく起きるエラーのため、知っている人は簡単に対処でき、例えば、training_batch_size のパラメータを小さくする、もしくはコンピューティングクラスターの VM サイズについて、より大きな VRAM を備えた GPU を持つマシンに変更するなどで対応できます。
とはいえ、これはある程度事前に知っているからわかることであるとも感じます。そういった点で、AutoML Computer Vision は Azure AI の Custom Vision や Computer Vision と比較すると、利用する際のハードルがある程度高めに設定されている印象を受けました。
この様に、設定変更の自由度が大きな点は本サービスの利点でもありますが、逆にエラー発生の要因にもなりえます。このような場合はユーザー自身で原因を把握して対処する必要があり、一長一短がある仕様ではあるなと感じました。
AutoML Computer Vision では、タスクごとに事前学習済みのモデルが用意されており、ユーザーはその中からモデルを選択することも、AutoML に完全に選択を任せてしまうこともできます。学習済みモデルは Pytorch のモデルとしてジョブの履歴に登録されるので、それをダウンロードすれば他のシステムでも利用することが可能です。
各タスクにおいて利用可能なモデルは以下となっています。
【画像分類 (複数クラス、複数ラベル)】
Default model は ViT base (画像サイズ 224×224, パッチサイズ 16)。なお、本記事執筆時点のハイパーパラメータに関するリファレンスには、default model が SE-ResNeXT と記載されていますが、これは古い情報です。「Computer Vision モデルをトレーニングするために AutoML を設定する」 のリファレンスの記述が正しく、実際に AutoML を実行してみても、ViT Base モデルの探索が優先されています。
【物体検出】
Default model は YOLO v5。
【インスタンスセグメンテーション】
Default model は Mask R-CNN ResNet FPN (深さ50)。
上記のように、画像分類タスクでは、CNN ベースのモデルだけでなく Vision Transformer も利用可能です。また、軽量モデルとして、MobileNet の選択肢も用意されているので、それなりにバリエーションがあると言えます。一方、それ以外のタスクでは、ある程度定評のある一般的なモデルが用意されてはいるものの、分類タスクと比較するとそこまで選択肢が広くはない印象を受けました。特に、YOLO v5 以外は全て2010年台に発表されたモデルであり、若干古めな印象はあります。
とはいえ、AutoML Computer Vision は、UI とモデルの詳細が分離された設計になっているため、今後利用できるモデルは拡充されていくのではないかとも思います。ハイパーパラメータの項目で述べた様に、モデルの設定値を指定する際、ユーザーはリファレンスを参考に手入力する必要があります。このような仕様になっているのは、モデルの詳細と UI が密結合にならない仕様にすることで、モデル追加を容易にしているという理由もあるのかもしれません。
モデルの追加に関しては、2024年4月24日時点でプレビュー提供中となりますが、HuggingFace の分類モデルや、MMDetection (バージョン 3.1.0) の Benchmark and Model Zoo の物体検知モデル、およびインスタンスセグメンテーションモデルを使用できる機能が提供されているようです。
サポートされているモデル アーキテクチャ - HuggingFace と MMDetection (プレビュー)
公式リファレンスによると、物体検知とインスタンスセグメンテーションにおいても Transformer ベースのバックボーンモデル (SwinTransformer) が利用できると記載されています。このように、標準のモデルでは十分な性能が達成できないような場合の選択肢として、追加で提供されているモデルが利用できる点は、本機能のかなり良いポイントなのではないかと感じました。
本記事では、Azure Machine Learning の AutoML Computer Vision について、その概要と、提供されている機能の全体的な仕様について解説しました。今回は、AutoML を用いたモデル構築の操作手順までは触れませんでしたが、今後【後編】の記事にて、具体的な操作手順に関する解説もできればと考えています。
当社では、画像系データを活用した業務改善について、画像認識モデルの構築から実運用おけるコンサルティング、さらには画像認識システムの開発に至る一連のプロセスをトータルでサポートしています。
また、画像分野に限らず、自然言語処理や LLM (大規模言語モデル) の活用、時系列データ、マーケティング、Web サイト、 IoT機器のセンサーデータなど、他の様々な領域のデータについても、 AI や機械学習技術を通した支援を行っています。また、これら技術に関する、新規技術の検証や開発に関するサポートについても承っておりますので、より高度なデータ活用を進めたい、技術的支援を希望したいなどのご要望がありましたら、ぜひ当社までご相談いただければと思います。
関連ブログ記事
【AI】GUI で操作するだけ!Vision Studio を使って画像認識を始めよう
|
関連ページ
日常的に簡単・手軽に使用できる生成 AI サービス - dailyAI |
