こんにちは。データサイエンスチームの藤 (トウ) です。
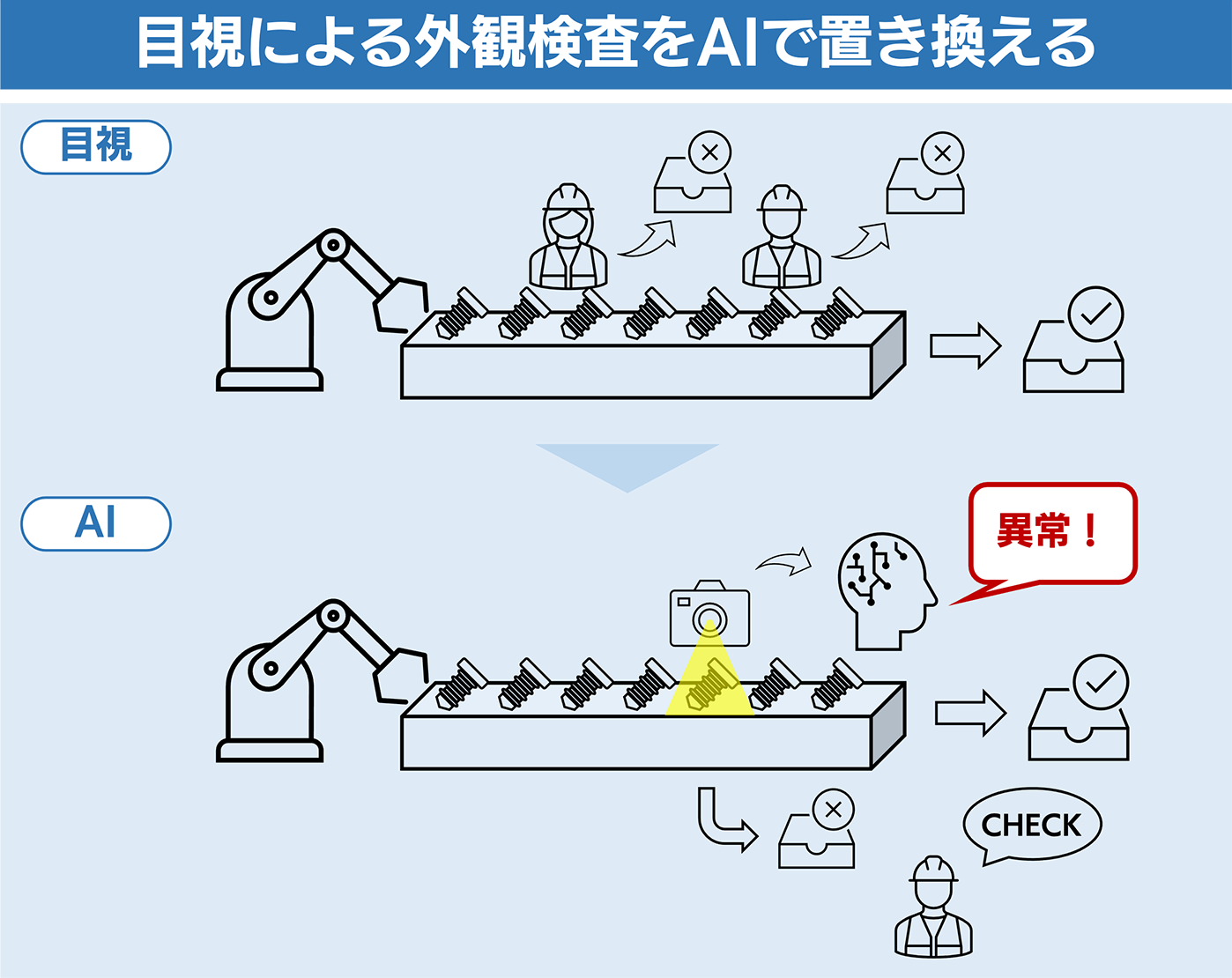
工場の生産ライン上で発生する不良品のチェックを自動化できていますか?目視によるチェックは人件費が増え、作業員の経験に左右されるでしょう。一定の基準で選別して AI による効率化を目指し、作業員の時間を作っていきたいものです。また AI による制御に取り組んだものの精度が満たせず、 AI 活用プロジェクトが頓挫した経験はありませんか? PoC (ビジネスとして利用できるか検証する) からシステム化まで検討する上で何が必要になるのか洗い出すのも簡単ではないです。
この記事では不良品のチェックの自動化を目的とし、ディープラーニングを活用して、撮影した画像に含まれる異常箇所を検知してみます。また AI 活用プロジェクトを通して、工場などの DX推進を進めていく上で必要になる考えも掲載しています。 AI 活用、 DX 推進に興味がある方は最後までお付き合いください。
画像の異常検知では、一般的に以下の 2 つの判定を行います。
具体例で示しましょう。


上記のように画像に異常が含まれているかどうか判定する場合は、画像に対して “正常” または “異常” の判定を行うことを目標に学習を行います。一方、画像内の異常箇所がどこかを判定する場合は、実際にどこが異常なのか出力することを目標に学習を行います。
業務によっては異常箇所を求めるより、画像に異常が含まれているかどうか判定さえできればよい場合もあるかと思います。一般的に異常箇所を判定する際の処理時間は、画像に対して異常検知をする場合よりも時間がかかる傾向があります。業務のプロセスに求められる速度を吟味しながら選択したいところです。
前章では判定方法について見てきましたが、ここでは実際にどのような手法を使っているのか見ていきます。大きく分けて以下の 3 種類の方法があります。
上記の手法のメリット、デメリットをまとめると以下になります。
左右にスクロールしてご覧ください。
| 手法 | 学習に必要なデータ | メリット | デメリット |
|---|---|---|---|
| 教師なし 異常検知 |
正常画像 (ラベルなし) |
正常画像さえあれば学習ができる |
|
| 教師あり 異常検知 |
正常画像 (ラベルあり) 異常画像 (ラベルあり) |
条件が整えば精度を出しやすい |
|
| 半教師あり 異常検知 |
正常画像 (ラベルの有無は問わない) 異常画像 (ラベルあり) |
異常画像を用意するコストが少ない |
|
実務上、上記 3 つの手法の中では教師なし異常検知をオススメします。データを確保する障壁の低さや、運用面の容易さが理由になります。そもそも工程の中で異常が発生しにくく、異常データを集めることが難しい点はよくヒアリング時に伺う現場の声です。
教師あり異常検知に必要なデータ量を確保できない、または複数の機器や現場に転用を考えているのであれば、教師なし異常検知を利用した方がよいでしょう。
異常検知によって以下のシーンとニーズを想定します。
想定するシーン
満たしたいニーズ
今回扱うデータは製造業の製品に着目し、 BSData を使用します。 BS というのは Ball Screw の略で、ボールねじと呼ばれる製品です。金属の表面に発生する局部腐食 (通常、孔食や Pitting と呼ばれる) を異常と定義します。前章の 「異常検知を適用するシーンとニーズ」 にて製品を個別に撮影しているという設定に合わせたデータセットです。一般に、撮影する画像の角度が一定であると検知する精度が向上します。どのようなアルゴリズムであれ、画像によってぶれが生じることは避けたいです。

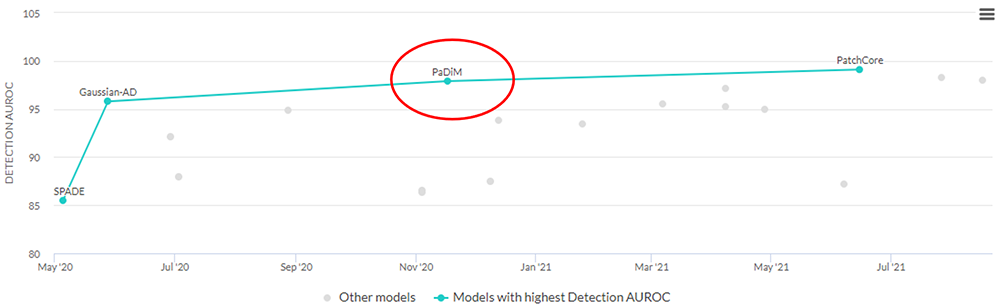
PaDiM は正常画像のみで学習可能な教師なし異常検知の手法です。 2021 年 5 月末段階で、異常検知タスクでよく使用される工業製品データセットの MVTec AD Dataset で 1 位を記録したアルゴリズムになります。 (現在の 1 位は PatchCore というアルゴリズムです)
PaDiM の処理内容を以下に簡単にまとめます。
① 学習用の画像をパッチと呼ばれるグリッド状の小さい画像に分割する
② 学習に使用するすべての正常画像の特徴量の平均、共分散をパッチごとに求める
③ テスト用画像の特徴量を抽出する
④ ②と③の結果を用いて、パッチごとに正常画像群とテスト画像の特徴量の差をマハラノビス距離という尺度で計算し、それを異常度と定義する
では実際に BSData の正常画像 485 枚を学習させます。テスト画像 450 枚 (正常画像 225 枚、異常画像 225 枚) で画像に異常が含まれるか、またその異常がどこにあるのかを出力させた実験結果について説明します。
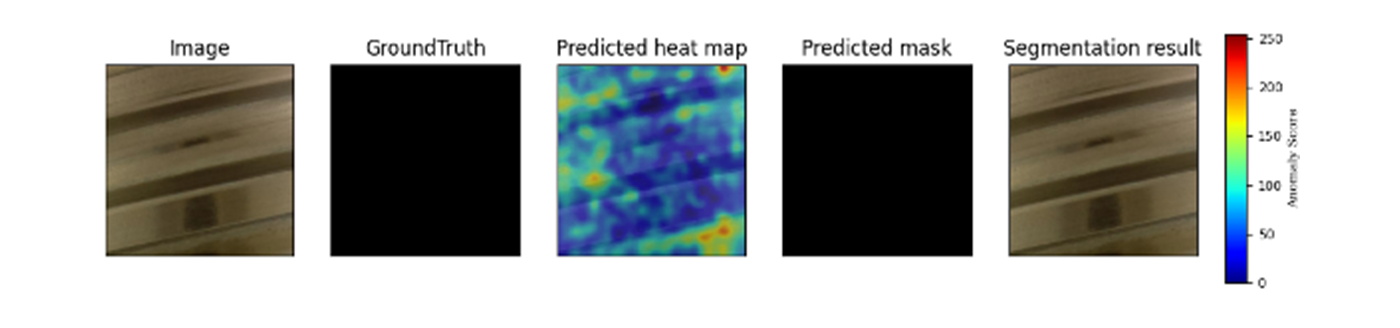
上記は正常画像をテストした際の結果の一例です。
続いて異常画像についても結果を見ていきます。
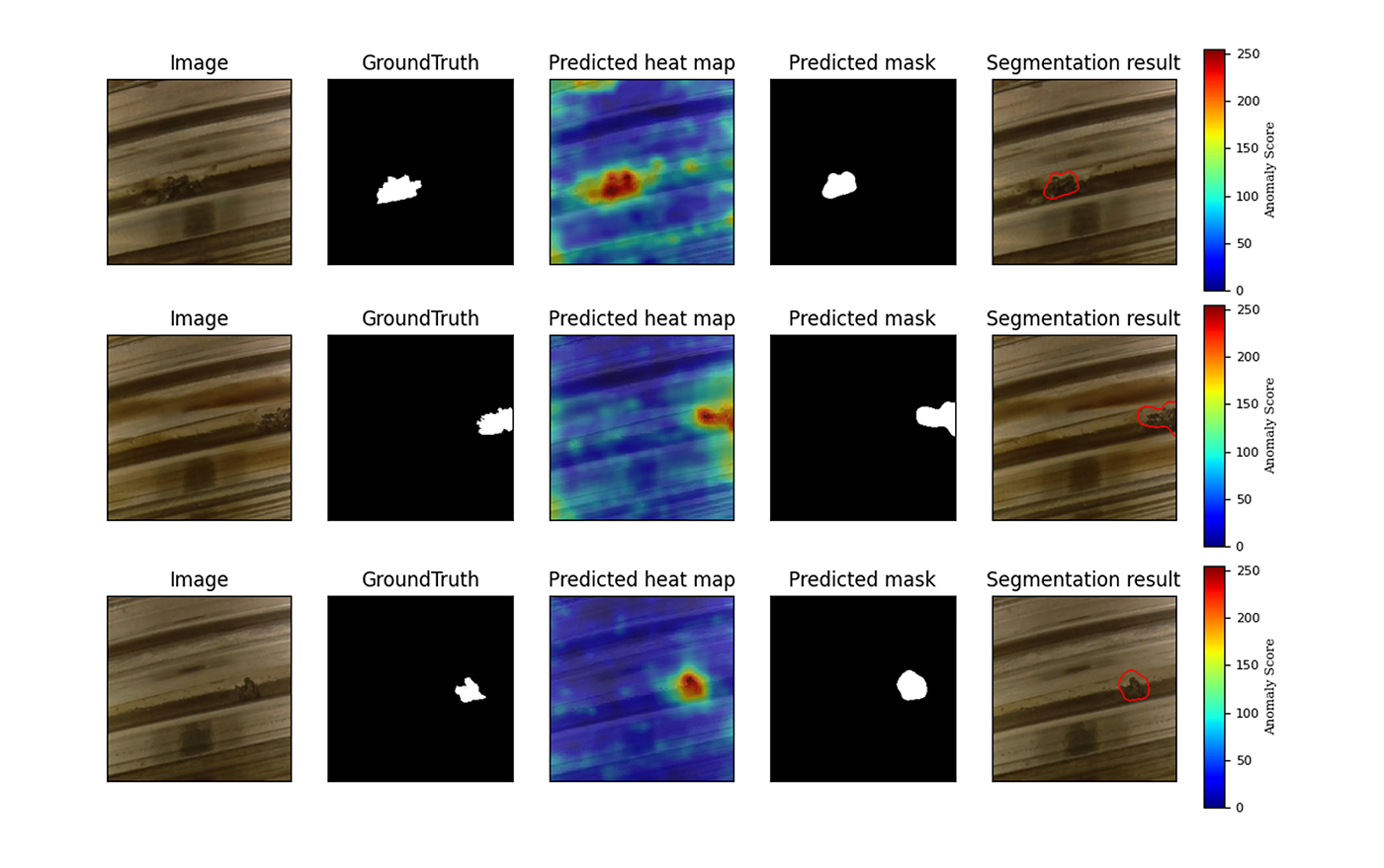
正常画像の結果とは異なり、 Predicted heat map に赤い領域が顕著に現れました。 Ground Truth と Predicted mask を見比べると異常箇所を検出できていることがわかります。
次に精度について見ていきます。
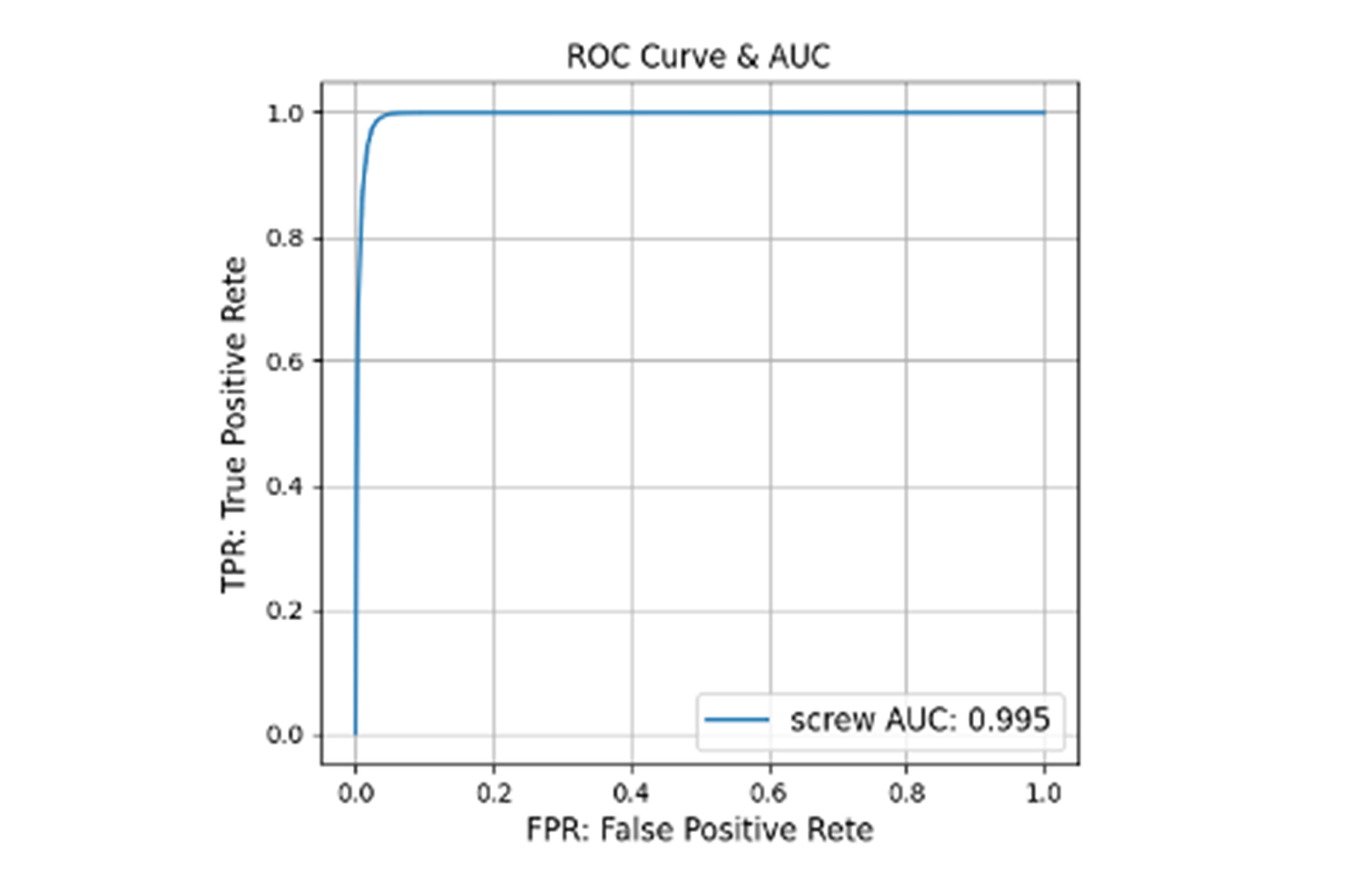
画像に異常が含まれているかどうか分類した際の混同行列は以下です。
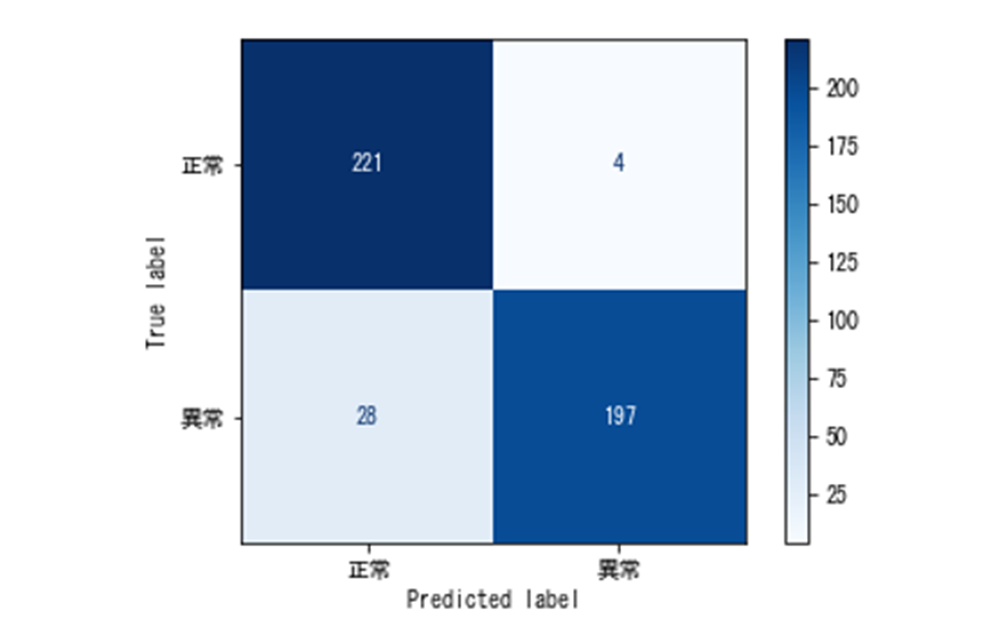
上図の見方としては True label (正解のラベル) が正常で、 Predicted label (予測されたラベル) が正常である数がどのくらいあるのか、という見方をします。
例えば True label が異常であるにもかかわらず、 Predicted label が正常と予測されてしまったラベルは 28 枚あるので、この 28 枚の画像を分析してモデルのパラメーターを調整するなどの検討が必要になります。
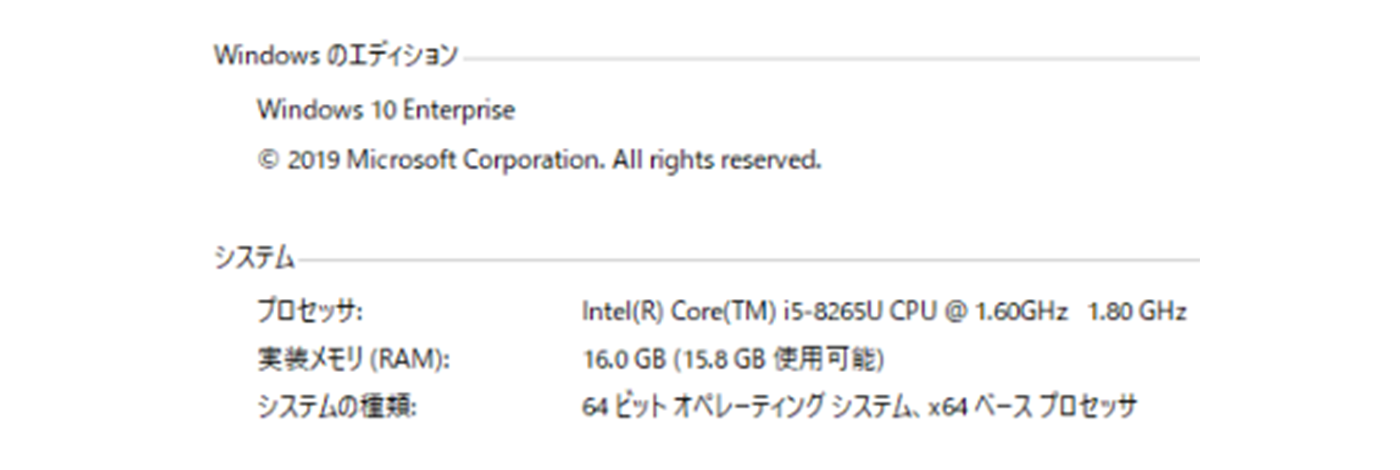
最後に速度を見ていきましょう。実際に導入するにあたり、処理速度は気になるところだと思います。 ローカル PC で 450 枚のテスト画像を処理した結果、 1 枚当たりの平均推論時間は約 0.34 秒となりました。念のため私の動作環境の情報を掲載します。
この処理速度が許容できるのかは業務プロセスに依存します。ただ時間を短縮したいということであれば工夫する術はあります。
などが挙げられます。
前章 「今回使用するアルゴリズム PaDiM とは」 において、出力結果、精度、速度を見てきました。少し考察していきます。撮影する位置に関しては画角が固定されており、ボールねじが傾くなどのブレがないことは精度の高さに寄与すると考えられます。実際の現場にカメラを導入する場合はぜひとも考慮したいポイントです。また環境面にも左右されることが多く、汚れなどが異常パターンに似ているのであれば検知されることもあります。発生する異常パターンや導入する環境も考慮に入れて AI の適用を進めていくことがポイントになるでしょう。
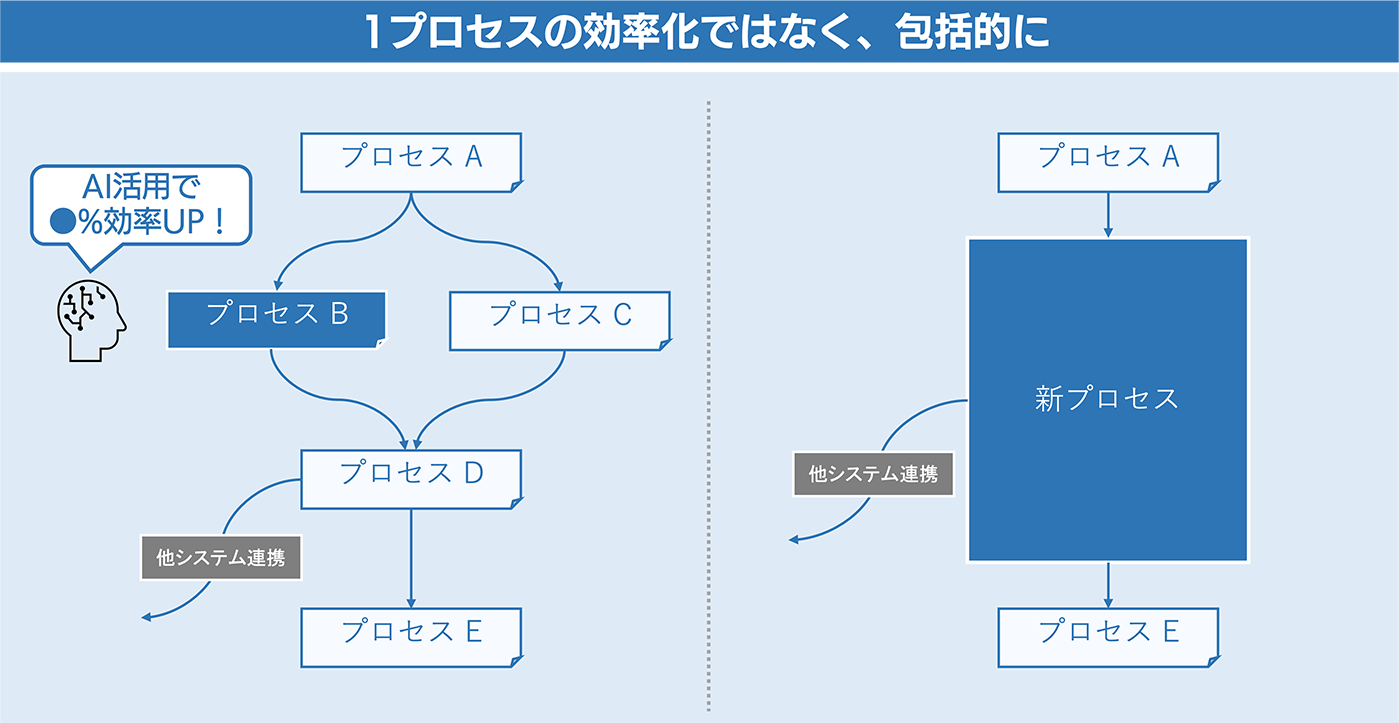
また作業効率化の施策として、そもそも AI を活用することが本当に有用なのかという視点も大事になります。これまでは精度や速度を見てきました。しかし、よい精度、よい速度を実現したとしても、 1 つの作業を単に効率化しただけでは DX が成功するとは限らないです。効率化した前後のプロセスにて手動の作業が発生し、 AI 活用の恩恵が減りかねないからです。
これまでの話をまとめて、 DX を推進する上でまず以下 2 つから考えてみるのはいかがでしょうか。
RPA を軸に考えて業務プロセスを整理すれば、例えば不良品を AI で弾くだけでなく、 AI 側は不良品率を計算しているので品質管理台帳への起票まで自動化できるでしょう。 AI を発端に効率化できるプロセスを徹底して洗い出すことが DX を成功させるカギだと私は考えています。
画像の異常検知について見てきました。 PaDiM の威力を見つつ、速度や活用、 DX についてもスポットを当ててみました。 AI の活用をご検討されている方はぜひご一考ください。
当社では、 AI 活用支援をはじめ、機械学習のモデル構築、クラウドを活用したシステム構築支援までご支援しています。現行の作業を軽減してより重要な作業に時間を充てたい、取得しているデータを活用して課題解決を行いたいなど AI 活用を検討中のご担当者の方、まず何からはじめればよいか悩んでいるといったお客様も、ぜひ一度お問い合わせください。
また、センサーデータを活用してエネルギー効率化を進める ML Connect - Forecast と、センサーデータの異常を検知する ML Connect - Anomaly Detection というサービスもご用意しています。画像に限らずセンサーデータに関してもぜひお問い合わせください。
関連ブログ記事
請求書やレシートの入力を自動化!Microsoft の OCR サービス、Form Recognizer のご紹介 |
関連ページ |




