こんにちは。データサイエンティストチームの八木です。
コロナによって私たちの生活様式はずいぶんと様変わりしましたね。働き方も同様に、テレワーク推進の波が押し寄せ、自動化や効率化の動きが来ています。業務の生産性もさらに重要視される中、本日は、紙や PDF の情報を読み取ってデータ化する、Azure Form Recognizer をご紹介します。このサービスを使用することで、画像からテキストを抽出する光学式文字認識 (OCR) を使用し、請求書やレシートなどのフォーマットを読み取りテキスト化することができます。また、事前にモデルを学習させることで複雑な形式にも対応することができるところが特徴です。
今回はモデルのカスタマイズを試してみようと思います。
Form Recognizer とは、Microsoft が提供する、AI によるドキュメント抽出サービスのことで、ドキュメントやレシート、名刺などから、テキストを抽出することができます。
Form Recognizer は、次のサービスで構成されています。
私が思う良い点と気を付ける点は以下です。
以降の章では、請求書の読み取りを行う際の Form Recognizer の簡単な使い方を、「事前準備」、「事前学習済みのモデルを試す」、「ツールの設定」、「タグ付け」、「学習とテスト」の 5ステップでご紹介します。
さっそく、Azure ポータルからご自身のサブスクリプションにアクセスし、Form Recognizer と Azure BLOB Storage を作成しましょう。
1.Form Recognizer
価格レベルは検証用に使う程度であれば、Free で問題ないかと思います。価格については、以下の URL をご参照ください。
https://azure.microsoft.com/ja-jp/pricing/details/cognitive-services/form-recognizer/
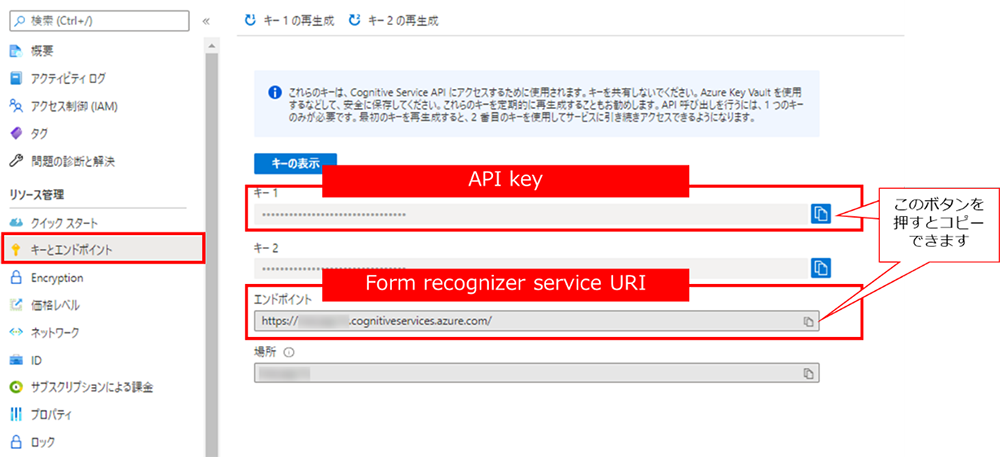
Form recognizer service URI (エンドポイント) と API key を確認し、別途メモ帳などに保存しておきます。
2.Azure BLOB Storage
BLOB Storage を作成します。
※Azure の Storage については、弊社のブログエントリをあわせてご参照ください。
Azure Storage 再入門
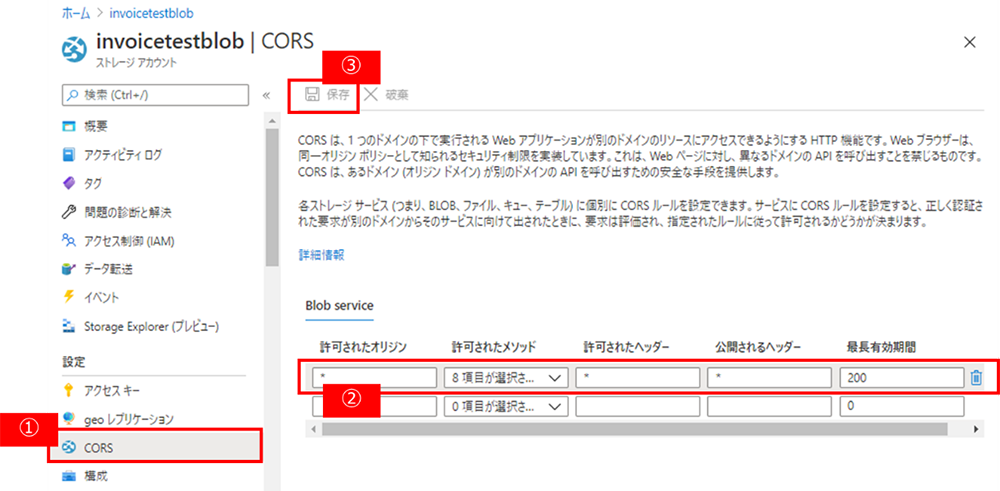
作成が完了しましたら、クロスドメイン リソース共有 (CORS) を構成します。
Azure ポータルで作成した BLOB Storage を選択し、左側のペインで [CORS] タブをクリックします。[BLOB Service] の行に、次の値を入力します。
その後、上部にある [保存] をクリックします。
3.画像の準備
今回は手元にデータがなかったので、架空の請求書 (PDF) を生成するコードを Pythonで書きました。試したいデータセットがない方は、以下 URL より、サンプルデータ (sample_data.zip) をダウンロード、展開して使ってみてください。
https://github.com/Azure-Samples/cognitive-services-REST-api-samples/tree/master/curl/form-recognizer
その後、BLOB に使用したい画像を格納するために、BLOB コンテナーを作成します。
④ コンテナーの名前を入力後、作成をクリックします。
⑤ 作成したコンテナーを選択し、[アップロード]をクリックし、用意した画像をアップロードします。
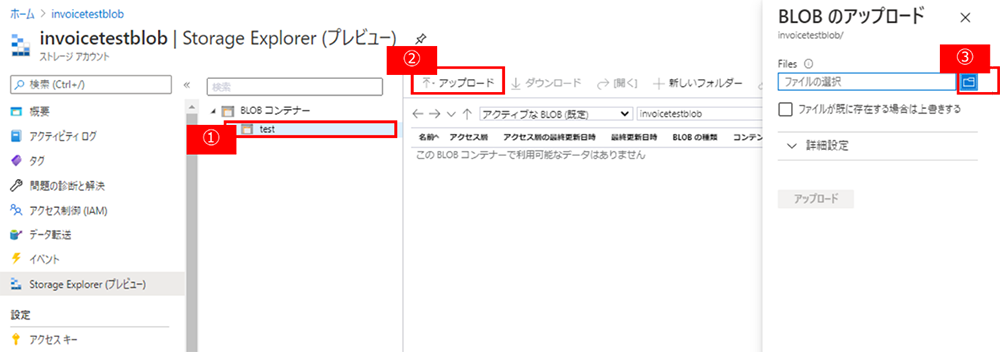
アップロードが完了しましたら、今度は SAS の URI を取得します。
⑥ Azure ポータルを開き、作成した BLOB にアクセスする。
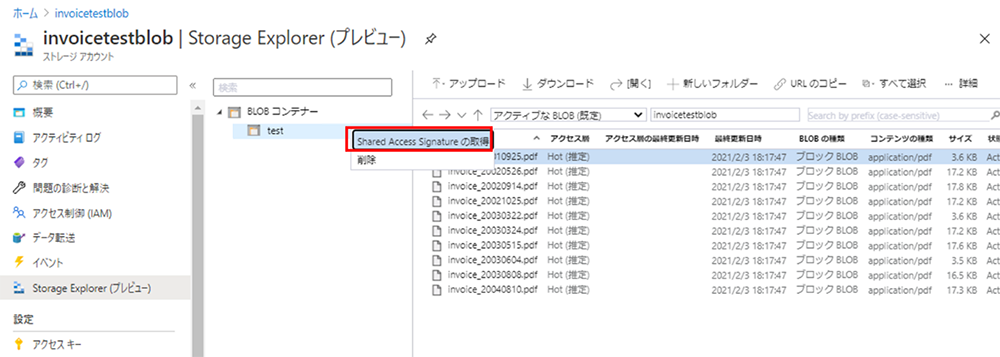
⑦ 作成したコンテナーを右クリックし [Shared Access Signature の取得] をクリックします。
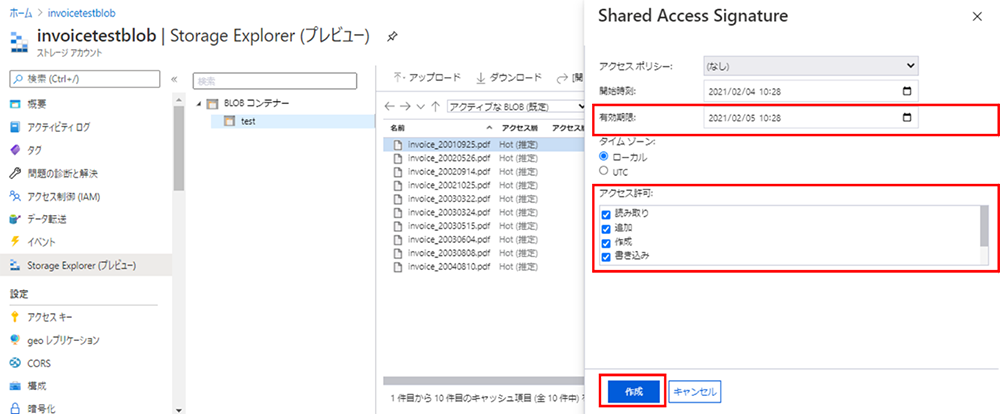
⑧ 有効期限やアクセス許可などを変更し、[作成] をクリックします。
⑨ Shared Access Signature のウィンドウが開きましたら、URI の [コピー] をクリックし、別途メモ帳などに保存します。
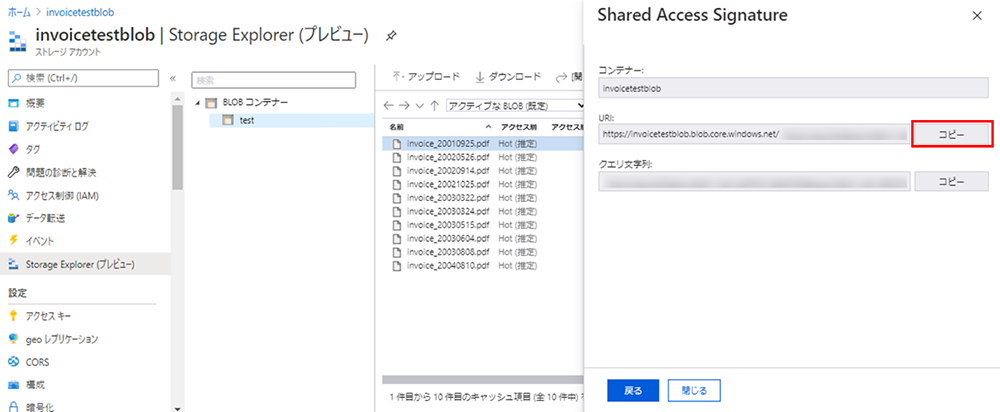
※左ウィンドウの [Shared Access Signature] からも SAS URI を発行できますが、BLOB コンテナーを指定するために、URI に BLOB コンテナー名を追記する必要があります。次の手順で出てくるラベルツール内でそのままで使うと、Invalid Resource Error となりますので注意してください。
これですべての準備が完了しました。次は FOTT の設定に進みましょう。
ここから、Form Recognizer のラベル付けツールである、Form OCR Test Toolset (FOTT) を使用して、ラベル付けを行っていきます。FOTT とは、GitHub のオープンソース プロジェクトとして公開されているラベル付けツールのことで、オンライン上でも使用することができるようになっています。
https://github.com/microsoft/OCR-Form-Tools/BLOB/master/README.md#run-as-web-application
Docker でも使用できますが、今回は Web ブラウザで簡単に試せるものを使ってみたいと思います。このツールでは、現在 3つのバージョンが用意されています。
※今回は、事前学習済みのモデルを試すのは 2.1-preview.* services 版、モデルのカスタマイズは2.0 GA services 版にてそれぞれ試してみました。
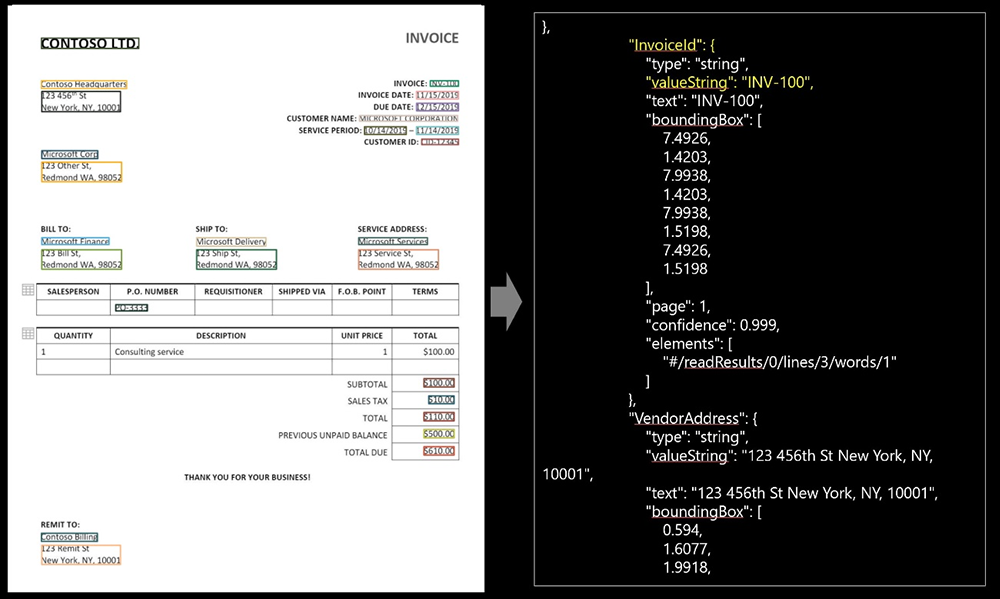
Form Recognizer の事前構築済みモデルには、請求書、レシート、名刺用のモデルがそれぞれ用意されており、今回は請求書モデルを使用します。このモデルでは、モデル顧客、仕入先、請求書 ID、請求書の期限、合計、請求金額、課税額、出荷先、請求先などのテキスト、テーブル、情報が抽出されるとのことですので、さっそく事前学習済みのモデルを使用した結果を確認してみましょう。
1. 以下、FOTT の事前学習済みモデルでの分析のページにアクセスします。
https://fott-preview.azurewebsites.net/prebuilts-analyze
開くとこのような画面が表示されます。
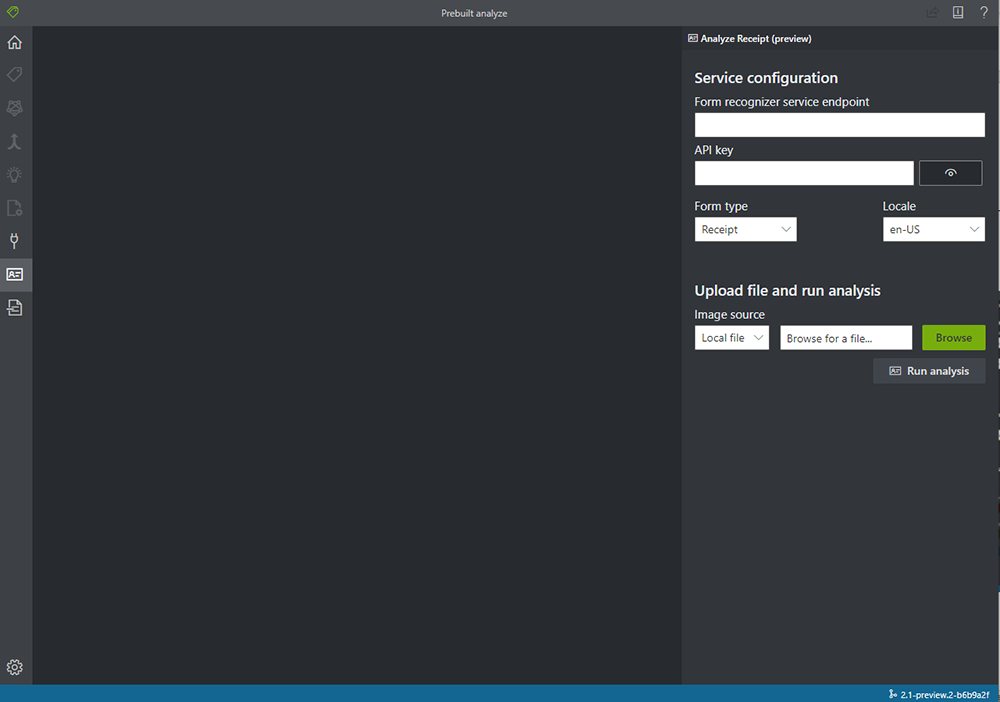
2. 情報を入力していきます。
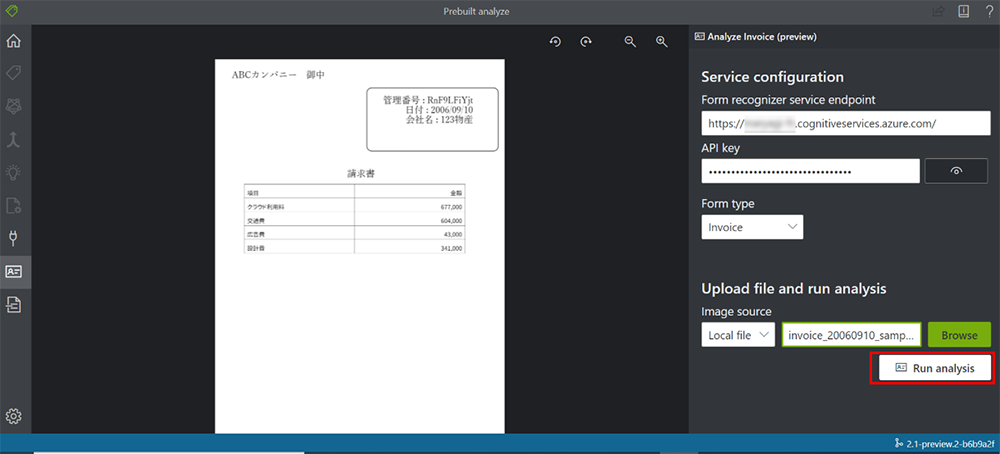
3. [Run Analysis] をクリックし、数秒待ちます。
4. 結果を確認します。
今回の結果では、日にちや管理番号などは取得できましたが、請求項目や金額の部分の取得は難しい結果となりました。
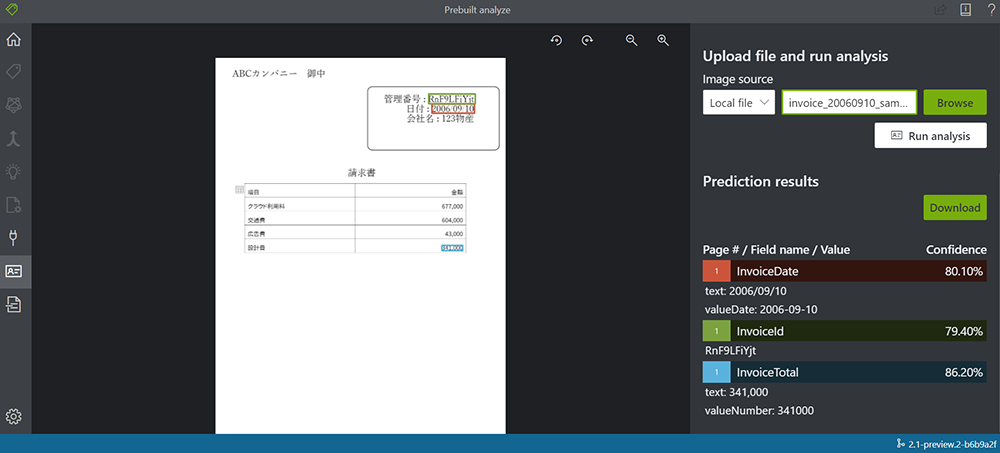
続いて、モデルをカスタマイズしていきましょう。
※API で試してみたい方は以下からも試すことができます。
https://westcentralus.dev.cognitive.microsoft.com/docs/services/form-recognizer-api-v2-1-preview-2/operations/AnalyzeBusinessCardAsync
まず、モデルのカスタマイズを行うプロジェクトの作成を行っていきましょう。
1. FOTT にアクセスします。
https://fott.azurewebsites.net/
2. アクセスすると以下のような画面が表示されますので、左の [New Project] をクリックします。
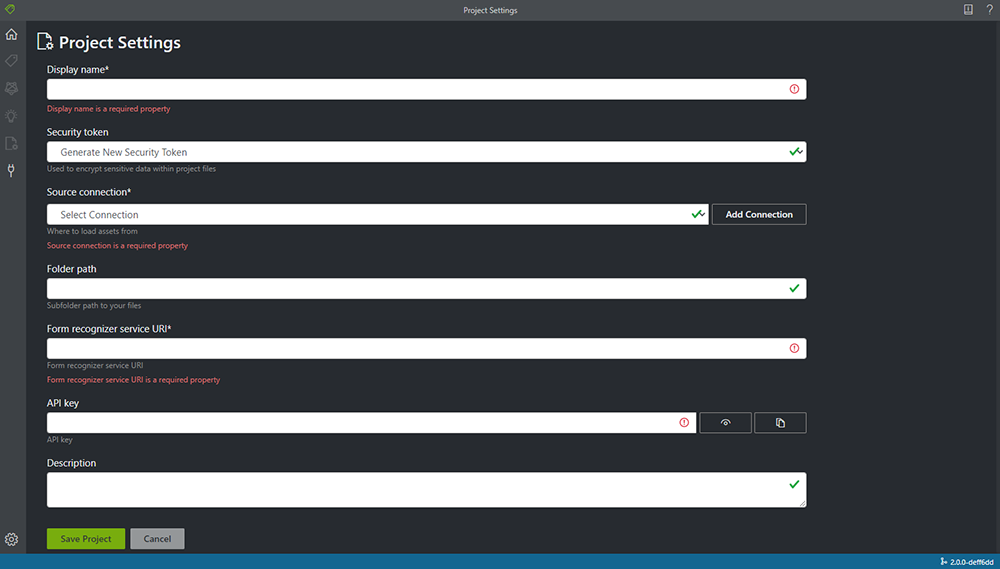
3. [プロジェクト設定] の画面が開きましたら、情報を入力していきます。
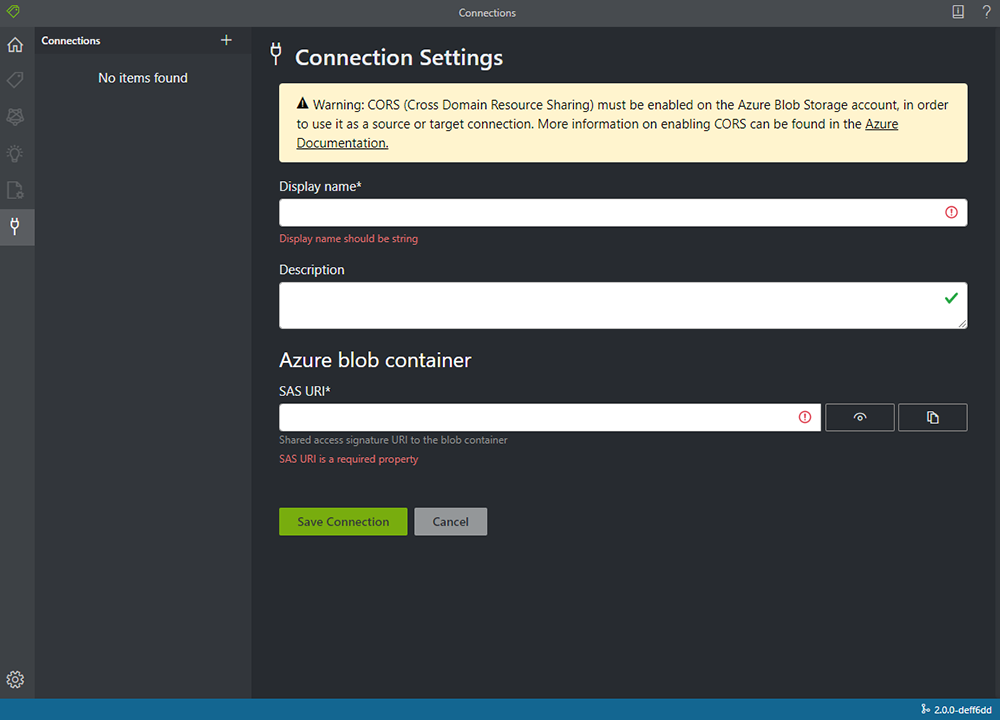
4. BLOB の設定を行います。
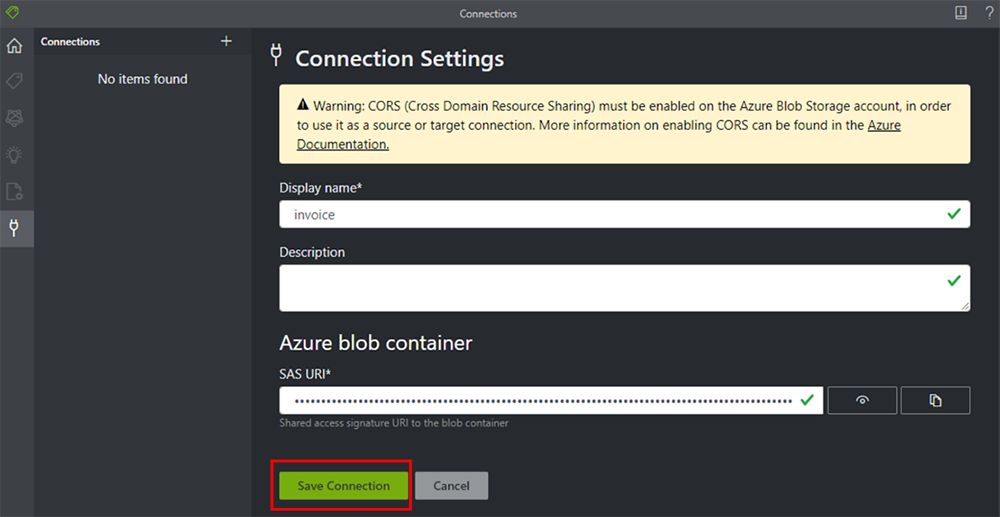
5. 入力が完了しましたら、[Save Connection] をクリックします。
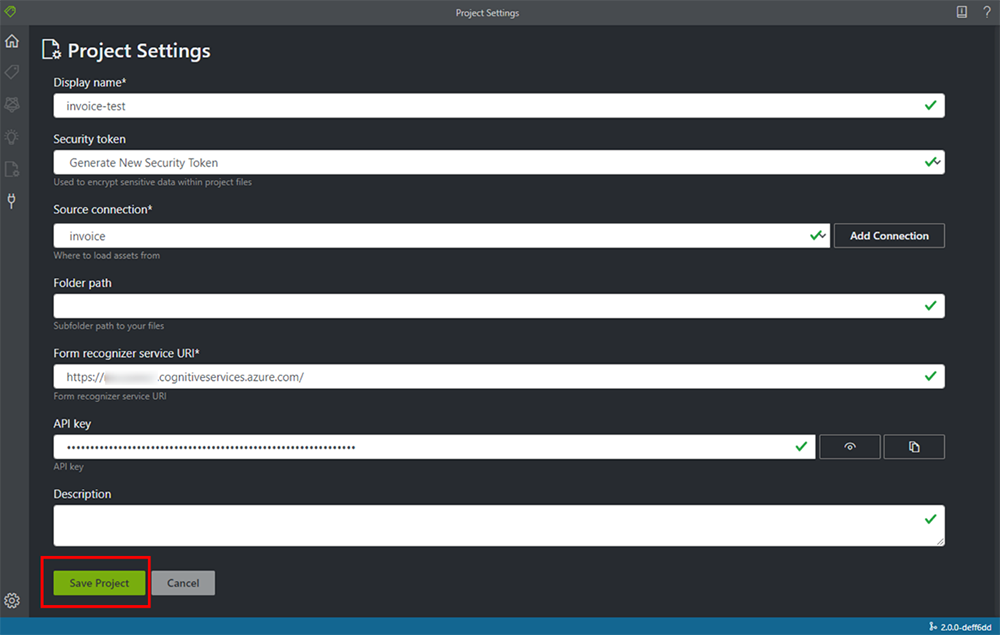
6. 接続に成功すると以下のような画面が表れます。
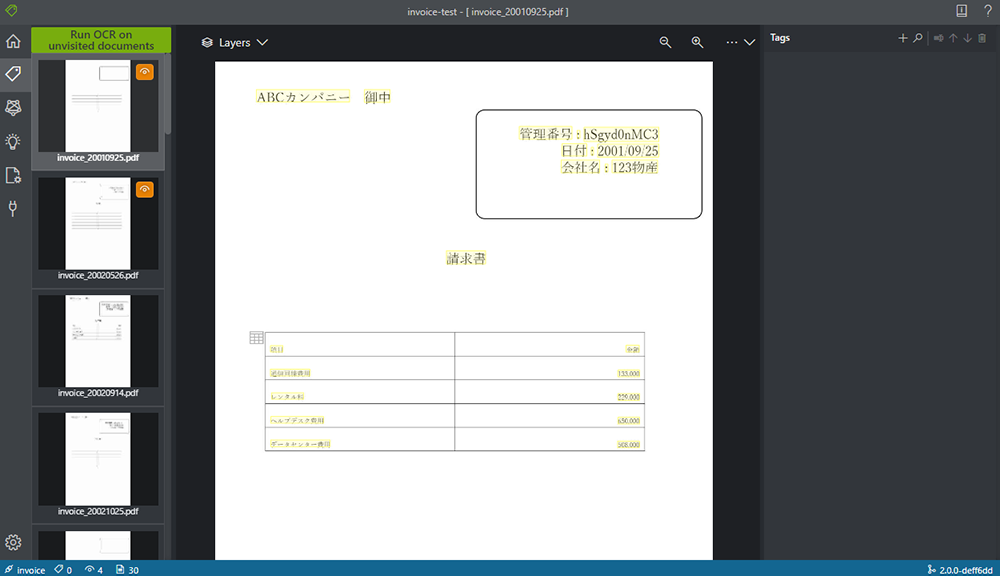
ここからタグ付けを行います。接続がうまくいくと、BLOB に保存した PDF が自動で読み込まれます。
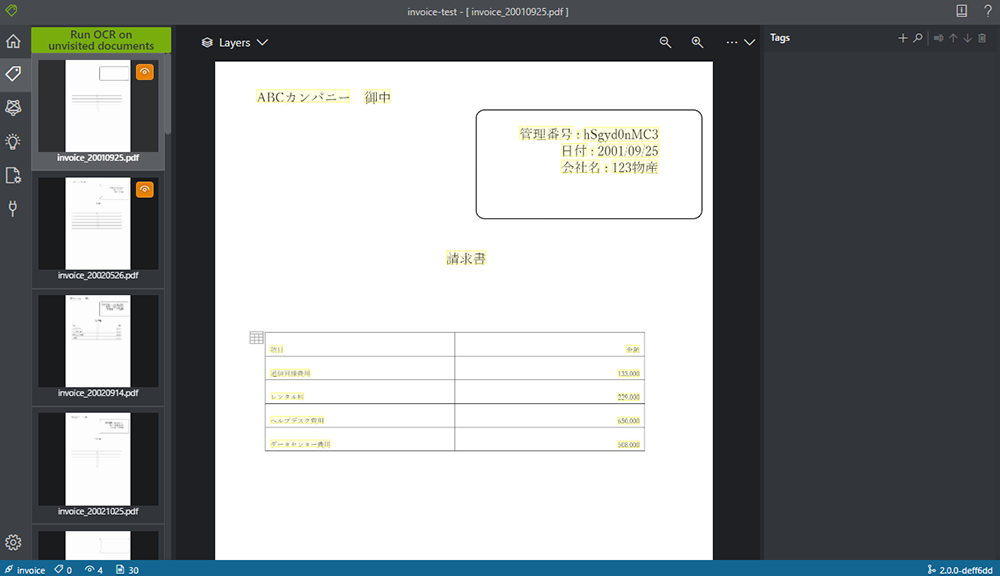
1. タグを作成します。
以下のAdd new tag に、作成したいタグの名前を打ち込み、エンターを押します。
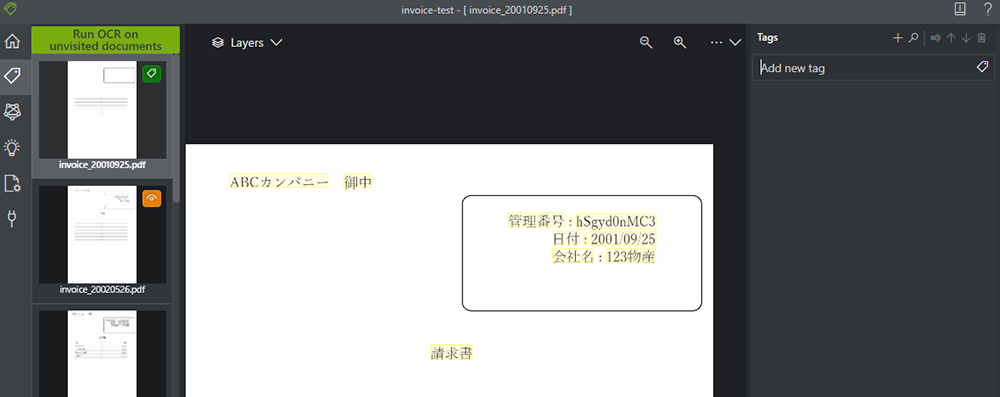
以下のような形で、タグが追加されました。
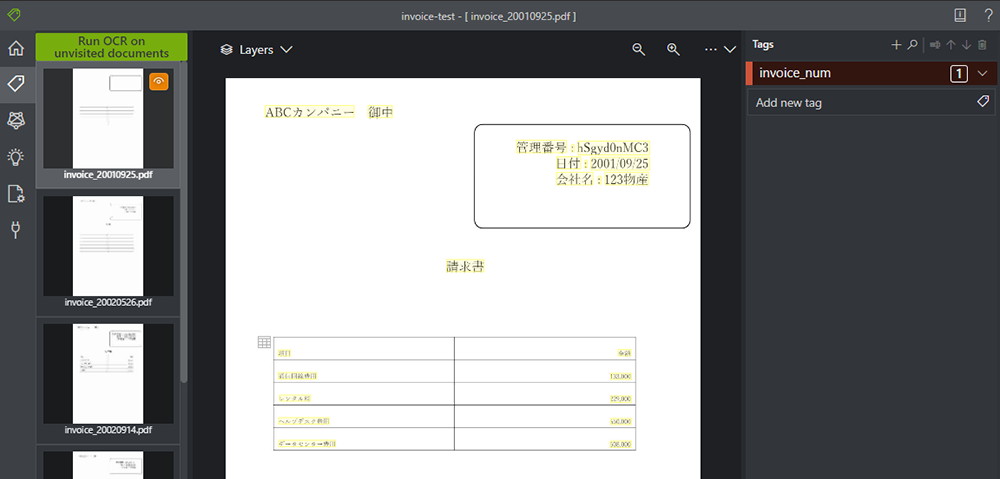
2. タグの型を選択します。
必要に応じて、タグのデータ型を設定できます。
これにより、テキスト検出精度の向上につながったり、JSON での結果出力の際に検出された値がその型で返ってきたりします。ですので、型情報もつけておくとよいでしょう。ここで入力したタグの型に関する情報は、fields.json ファイルに保存されます。
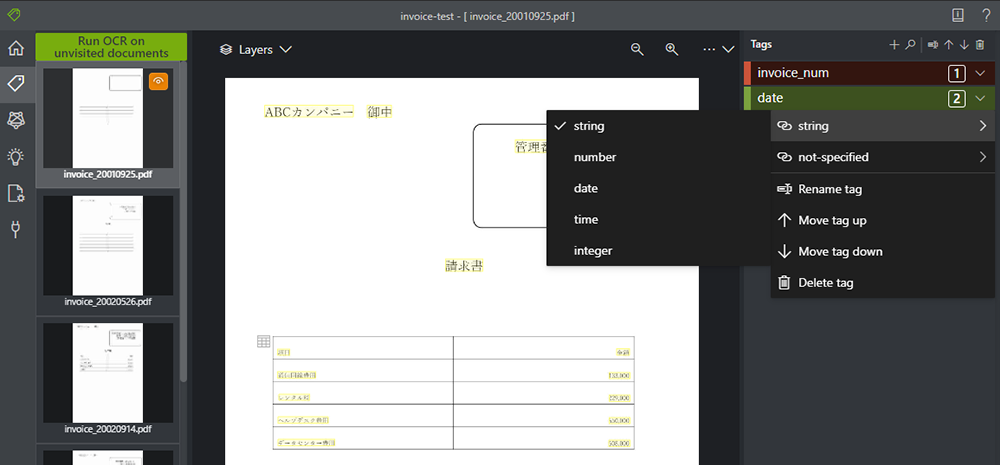
3. 全てのタグについて、追加・型の選択を行います。
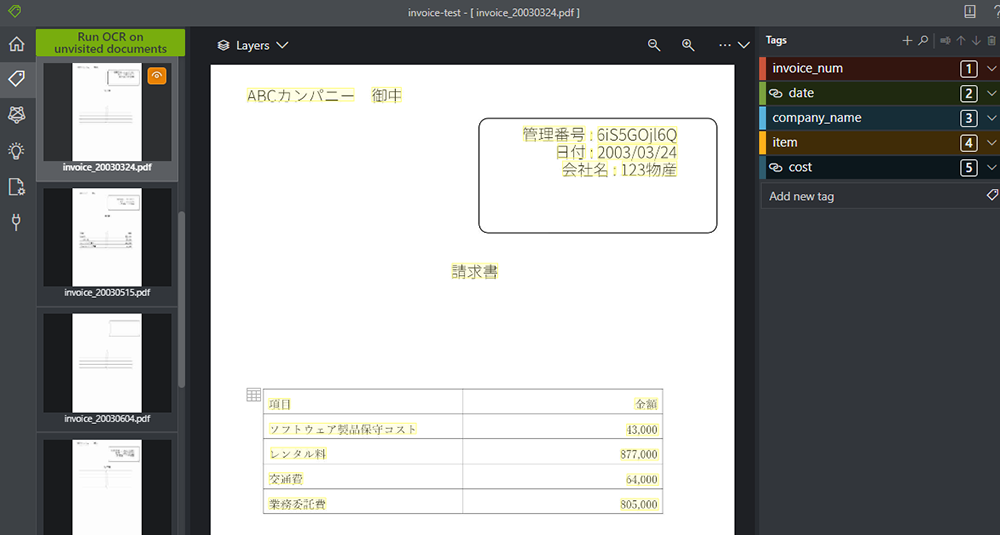
いよいよ各 PDF にタグを付けていきます。
4. タグをつけたい項目を選択します。例として、管理番号にタグをつけるとした場合、黄色い管理番号の値をクリックすると、選択した箇所が黄色から緑色に変わります。その後、右ウィンドウのつけたいタグ (この場合だとinvoice_num) をクリックします。
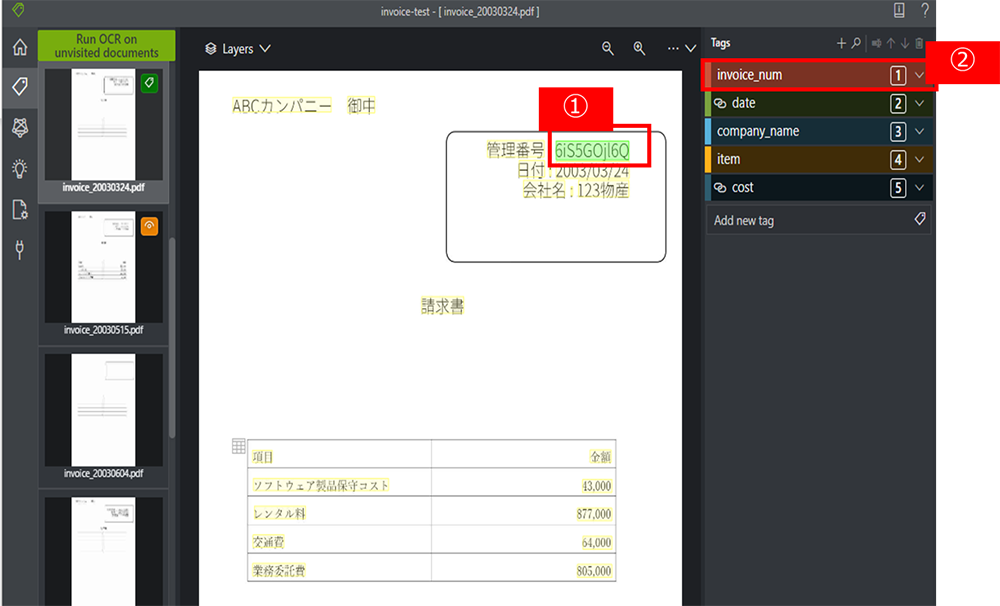
5. タグが付くと、選択したい箇所がタグの色の四角で囲まれます。また、Tags ウィンドウ にも情報が反映され、正しくタグ付けされていることが分かります。
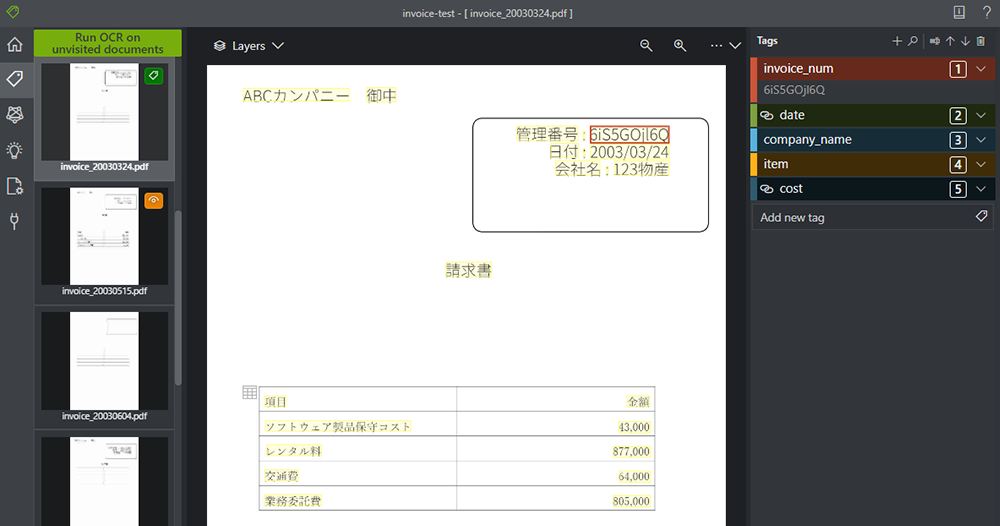
6. 複数一気にタグ付けするときは、以下のように 4つ続けてクリックしてから、該当するタグをクリックします。
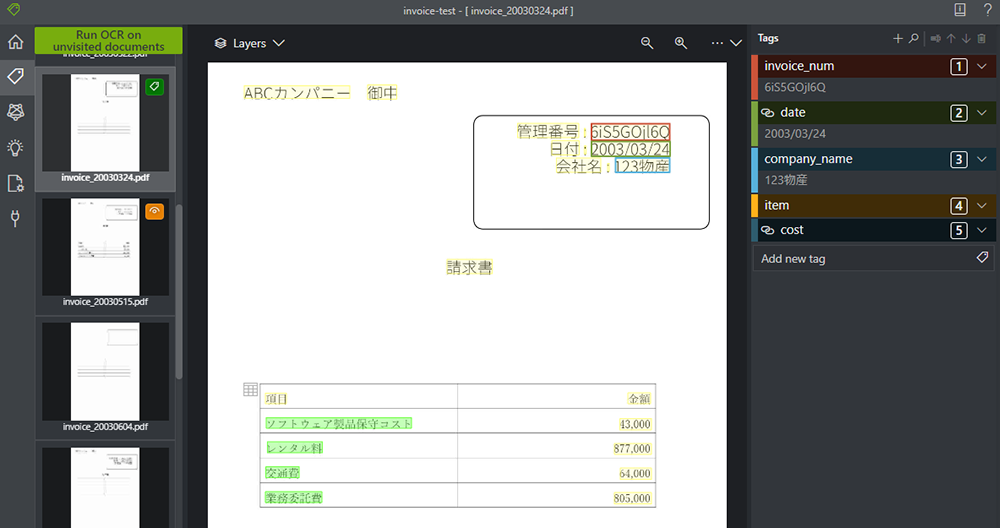
7. 複数まとめてタグをつけることができました。
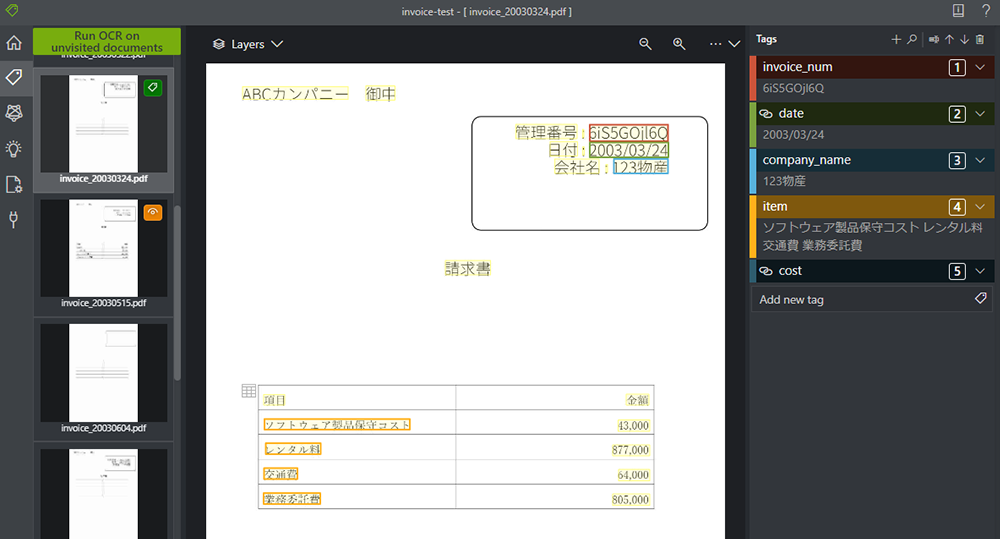
8. これをすべてのタグについて行えば、PDF のタグ付けが 1枚分完了しました。
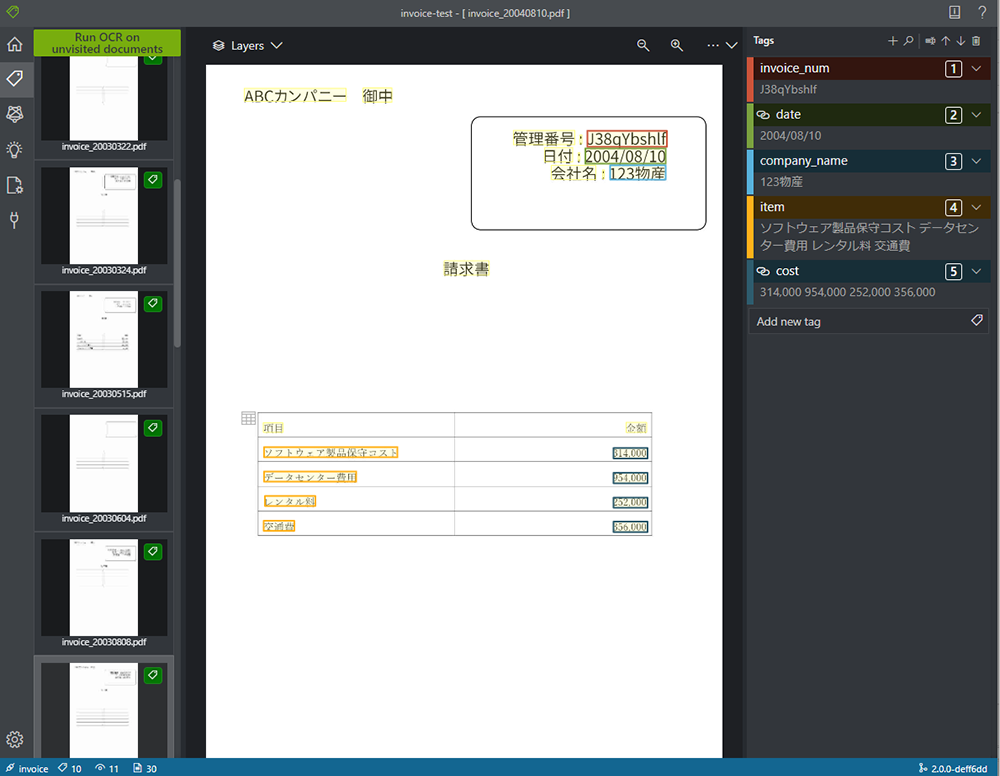
これを学習させたい枚数分やってみましょう。
1. 左側のペインでトレーニングアイコンをクリックして、[トレーニング] ページを開き、[Train] ボタンをクリックします。すると、モデルのトレーニングを開始されますので、数秒待ちます。
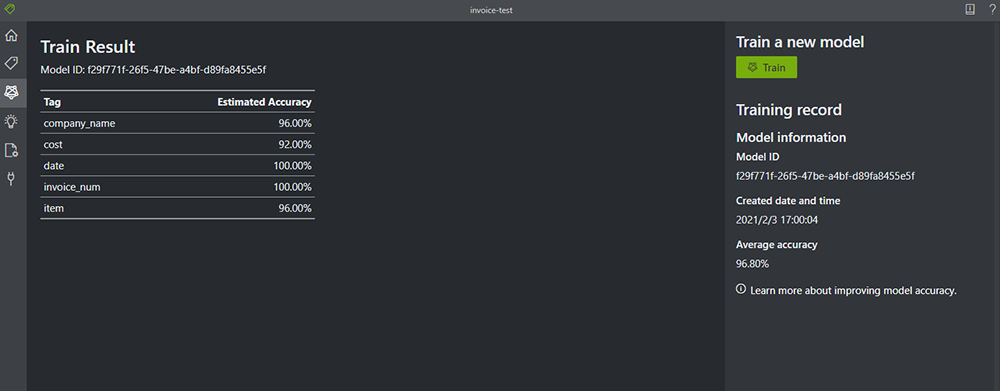
2. トレーニングが完了すると、学習結果が表示されます。
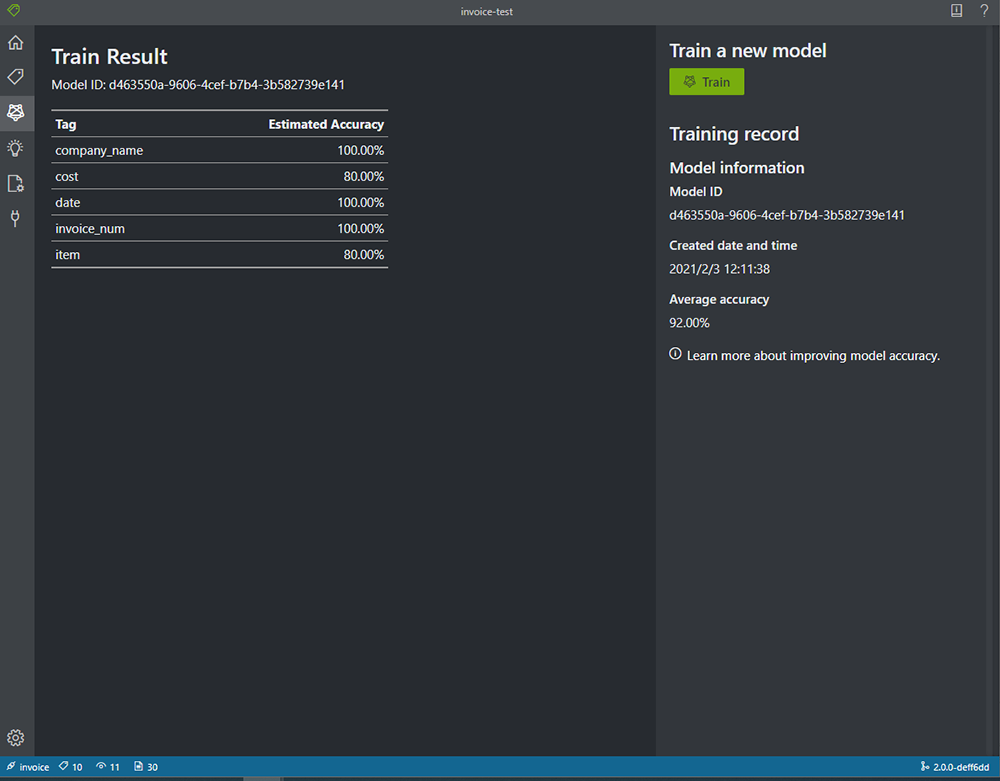
今回の結果では、cost と item の精度が低いことが分かります。学習に使用していないデータを使用して、テストしてみます。
3. 左側のペインで予測アイコン(電球)をクリックして、モデルのテストを行います。[Load file] をクリックして学習で使用しなかった PDF をアップロードし、[Run analysis] をクリックします。
4. 数秒~数十秒待つと、テスト結果が表示されます。
<うまくいっている例>
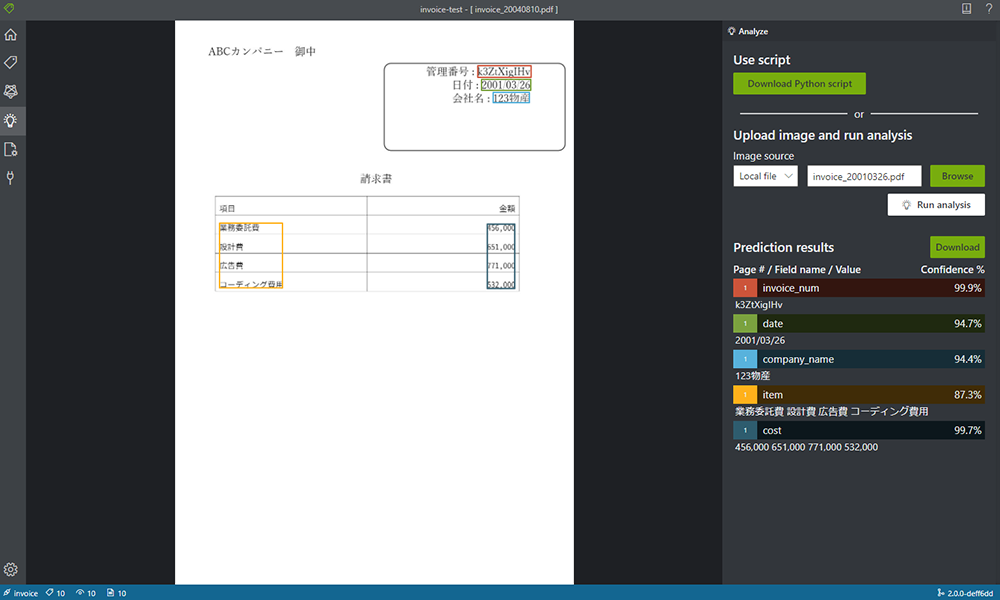
<失敗している例>
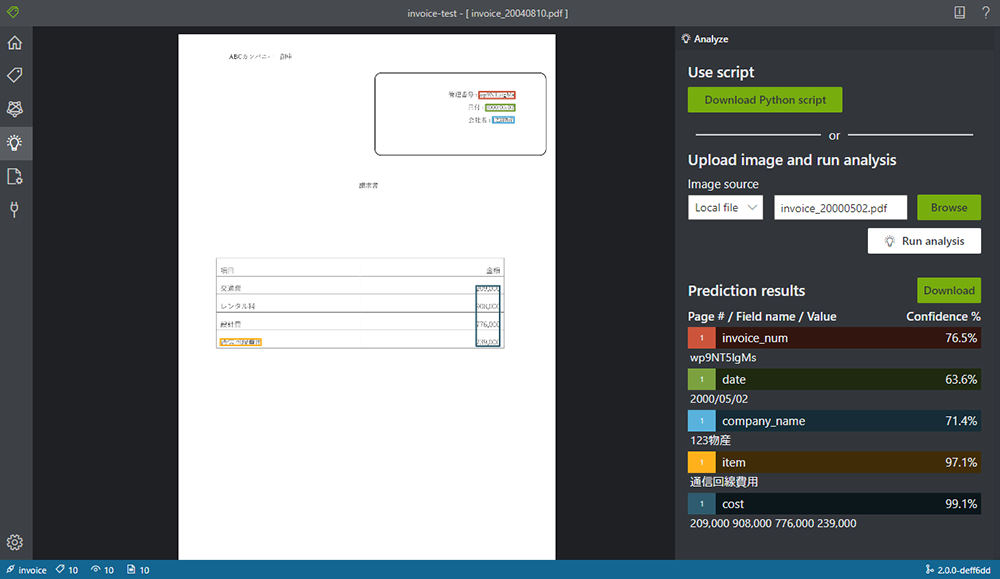
上記例だと、請求書の項目が上手く検出されていません。今回学習に使用しているデータは 10枚しかなかったため、学習に使う画像を追加で 15枚ほど増やしてみます。
5. BLOB にデータを追加すると、FR の方にも自動で画像が反映されますので、またラベル付けを行い、再学習させます。
その結果が以下です。cost と item の精度が向上していることが分かります。
6. 先ほどうまくいかなかった画像をテストしてみます。
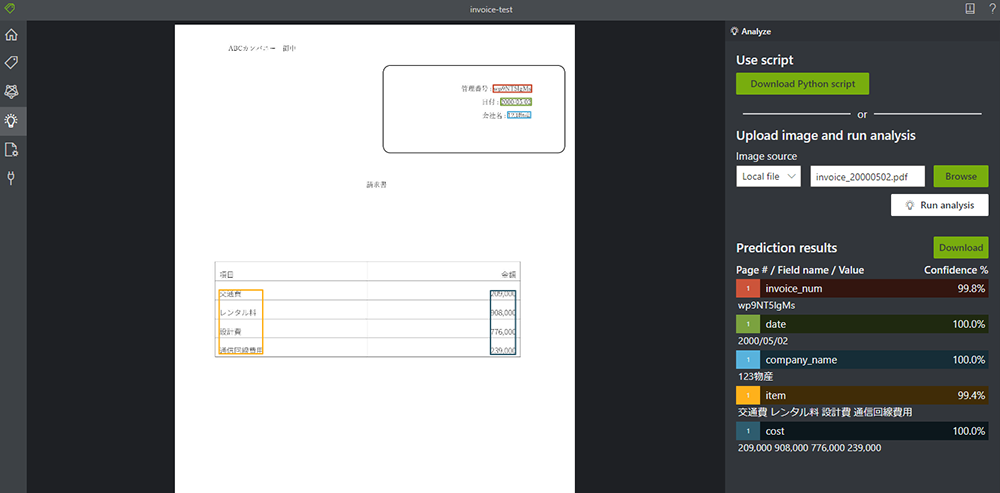
無事、請求書の読み取りに成功しました。今回、学習に使用したダミーの請求書は 25枚ほどでしたが思ったより精度が高く、また、タグ付けのツールも用意されているので、これから AI を始める方やお手元のデータで少し試してみたい方にもお勧めのツールだと感じました。
今回は、様々なフォームの情報を読み取ってデジタル化する、Microsoft の Azure Form Recognizer をご紹介しました。Form Recognizer を使えば簡単に紙や PDF からデータを起こすことができます。このサービスを使えば請求書やレシートなどの確認や入力作業などを効率化することが可能です。また、カスタマイズすることができるため、独自のフォーマットなどでも対応できるところが便利ですね。現在どんどん機能追加が行われているため、ますます簡単で使いやすくなっていくと思われます。
コロナ禍で変革を迫られている今、一からスクラッチで機械学習を作らなくてもこういったサービスを使うことで、ビジネスの AI 導入の敷居を下げることができます。ぜひこういったツールを活用して、新しい取り組みを始めてみるのはいかがでしょうか。
弊社では、このような Azure のサービスを使用した AI 活用支援をはじめ、様々な分野での機械学習モデル構築を承っております。現行の作業を軽減してより重要な作業に時間を当てたい、取得しているデータを活用して課題解決を行いたいなど AI 活用を検討中のご担当者の方がいましたら、ぜひお問い合わせください。まず何から始めればよいか悩んでいるといったお客様も、お気軽にご相談いただければと思います。




