こんにちは。データサイエンスチームの宇野です。
ChatGPT がリリースされてから1年以上が経過しました。現在、弊社も含めて様々なシーンでの LLM の利用事例が増えてきています。代表的な活用事例として、Webサイトの自動作成、 Q&A の自動生成、電話商談の自動要約など様々な利用用途が挙げられます。
さて、様々なシーンで普及してきている LLM ですが、実は単体では、 Excel 形式や CSV 形式のようなデータに対する数値分析タスクの回答精度があまり高くない傾向が見受けられることはご存じでしょうか。数値分析タスクはデータの並べ替えや集計といった一意に回答が決まるタスクですが、実際にOpenAIが提供するモデルである GPT-4-oでも数値分析タスクを行った際は、何回か同じプロンプトを入力したときに毎回違う回答をしてしまう傾向があるようです。
この問題を改善し、数値分析タスクの回答精度向上にアプローチする代表的な手法としてLangChain ライブラリの Agent 機能の1つであるCSV Agent やOpenAI が提供する ChatGPT の公式プラグインの1つである Code Interpreter などが挙げられます。これらは Python コードをLLMに生成させて数値分析タスクを行う手法です。今回は、 比較的簡単に実装できるCSV Agentと Code Interpreter に焦点をあてて説明します。まず、これらの手法についての概要を説明します。次に、これらの技術の仕組みを理解するために Pythonコードを LLM に生成させて数値分析を行うということについての説明をします。そして、 CSV Agent 、 Code Interpreterを実装するための事前準備をして、CSV Agent と Code Interpreter それぞれの実装方法を紹介します。
まずは、 CSV Agent と Code Interpreter の概要を説明します。
CSV Agent は分析対象の CSV ファイルを Python の Pandas ライブラリのデータフレーム形式で取り込み、 LLM に Python コードを生成させ、 python_repl ツールを呼び出して生成したコードを実行する LangChain のAgent機能です。 LangChainはLLMを使ったアプリケーションソフトウェアの作成を簡素化するように設計されたライブラリです。プロンプトの管理・最適化・シリアル化が出来たり機能や複数のプロンプト入力を実行する機能であったりと様々な機能があります。Agent 機能 はLangChainの機能の一つであり、 LLM の判断で必要に応じて事前に設定した機能(ツール)を呼び出して実行、観測し回答が完了できるまで LLM とのやりとりを繰り返す機能です。 LangChain 、 Agent それぞれについての詳細は、以下のリンクを参照してください。
CSV Agentはコード生成の際の実行環境が閉じられていないため、ライブラリの追加やファイルの読み込みの柔軟性が必要なシーンでの利用が有効です。しかし、ユーザーが意図しない Python コードの実行やファイル操作が行われる可能性ありますので、実行の際はサンドボックス環境を用意するまたは重要なファイルなどがない環境での実行を推奨します。
Code Interpreter は OpenAI が提供する ChatGPT の公式プラグインの1つです。Pythonのコードを生成して実行したり、ファイルをアップロード・ダウンロードしたりすることができるプラグインとなっています。
Code Interpreter は ChatGPT の GUI で使用することもできますし、 Assistants API を用いることで使用することもできます。 Assistants API は、様々なツールを事前登録しておいて利用できる AI Agent の API です。今回は、 Assistants API を用いて実装してみます。 Assistants API について、より詳しく知りたい方は、以下の OpenAI 公式リファレンスについても参照いただければと思います。
Code Interpreterで生成された Python コードは OpenAI のサーバー上の仮想的な Python 実行環境で実行されます。そのため、Code Interpreter は、セキュリティの担保が必要なシーンでの利用が有効です。しかし、Assistants API のCode Interpreter の使用にあたりAzure OpenAI Service では1セッション当たり ¥ 4.6217 (2024年8月時点)かかってしまうといったコスト面に注意する必要があります。
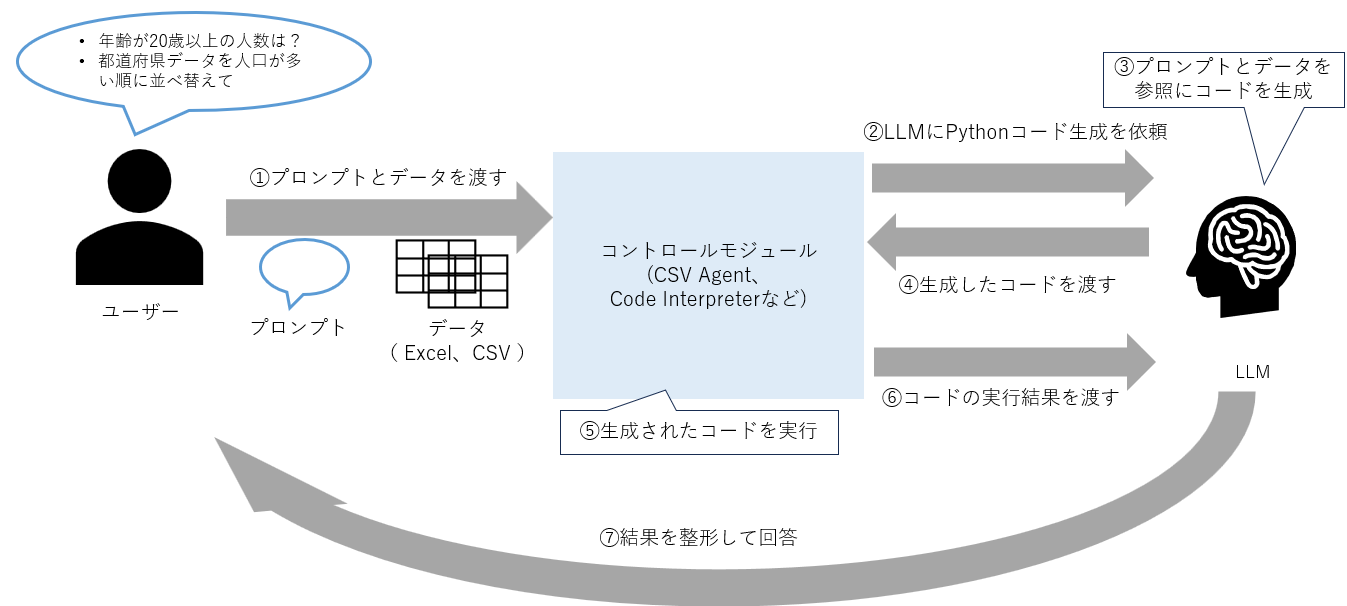
次にCSV Agent 、 Code Interpreter の仕組みの概要を理解するためにPython コードを LLM に生成させて数値分析を行う際の大まかな処理フローについて説明します。 Python コード生成するにあたり、まずは以下の図に示すように、 LLM に数値分析タスクを行わせるためのコントロール機能を持ったモジュール( CSV Agent や Code Interpreter など)にユーザーからのプロンプトと分析対象データを渡します。次にモジュールがプロンプトとデータを受け取ったら それらを参照にLLM に Python コードを生成させます。 次に LLM が生成したコードをコントロールモジュールが実行し、実行結果を LLM に渡します。最後に、 LLM が実行結果を整形してユーザーへ回答します。ここまでが Python コードを LLM に生成させて数値分析を行う際の処理フローになります。
次に、CSV Agent 、 Code Interpreterを実装するための事前準備を行います。前節にもあった通り今回紹介するCSV Agentと Code InterpreterはそれぞれLLMの数値分析タスクの回答精度向上のために用いる機能、プラグインであるため、実装にあたりLLMのデプロイが必要です。今回は Azure OpenAI Service が提供するモデルをデプロイし、そのモデルを使ってCSV Agent と Code Interpreter を実装します。
Azure OpenAI Service は、 Microsoft 社の法人向け OpenAI サービス であり、 ChatGPT や DALL-E といった多様な生成 AI モデルを Azure のプラットフォームで利用できるサービスです。Azure OpenAI Serviceについて、より詳しく知りたい方は、以下の Azure 公式リファレンスを参照してください。
今回は以下の手順に従って、 GPT-4 (2024-05-13) を デプロイします。
※ Azure Portal にサインインするためには、 Microsoft アカウントと Azure アカウントが必要です。無料で試すことができますので、まだ持っていない方は以下を参考に作成してください。
※デプロイできるモデルがリージョンごとに異なります。今回はリソース作成時のリージョンの選択で多様なモデルがデプロイ可能な「 Sweden Central 」リージョンを選択しています。各リージョンでデプロイできるモデルについて、より詳しく知りたい方は、以下の Azure 公式リファレンスを参照してください。
Azure OpenAI Studio で以下のような画面まで遷移したら作成ボタン押してデプロイ完了です。モデルのデプロイ名については、本来は任意ですが、今回は「 test-model 」にします。デプロイ名については、この後使用するので手元で控えておきます。

キーとエンドポイントはAzure OpenAI Serviceリソースの「キーとエンドポイント」メニューから確認できます。今回、キーはキー1を使います。キーとエンドポイントは手元にメモしておきます。
※キーは、データや通信の暗号化に必要なものであり、エンドポイントは API に接続するための URLです。これらの情報が外部に漏れると、悪意ある攻撃者によって機密データが盗まれたり、不正にアクセスされたりする可能性があるため、外部に流出しないように厳重に管理してください。
ここでは、CSV Agent を動作させる環境を構築し、 その環境でCSV Agent を実装してCSV形式のデータに対して数値分析をします。
今回は、分析したい CSV ファイルとして、下記の弊社で用意した架空の個人情報データ1000件が記載されている CSV ファイルを利用し、男女の人数を集計します。
▼架空の個人情報データの一部(1000件)
以下の手順に従って、数値分析をします。
1.ライブラリのインストール
CSV Agentを利用するにあたって、必要なライブラリをインストールします。
pip install langchain==0.2.12
pip install langchain_community==0.2.11
pip install langchain-experimental==0.0.64
pip install pandas==2.1.0
pip install tabulate==0.9.0
2.キーとエンドポイントの設定
前章でメモした Azure OpenAI Service リソースのキーとエンドポイントを環境変数に設定します。
下記のコードの YOUR_RESOURCE_KEY と YOUR_ENDPOINT にそれぞれキーとエンドポイントを指定して実行します。このスクリプトを実行することにより、定義した環境変数に Azure OpenAI Service リソースのキーとエンドポイントを設定します。
os.environ["AZURE_OPENAI_API_KEY"] = "YOUR_RESOURCE_KEY"
os.environ["AZURE_OPENAI_ENDPOINT"] = "YOUR_ENDPOINT"
3.LLMの設定
次に下記のコードを実行して LLM を設定します。 LLM は LangChain ライブラリの Azure Chat OpenAI クラスを用いて作成します。この関数の引数に、 API のバージョンとデプロイしたモデル名を指定します。
from langchain_community.chat_models import AzureChatOpenAI
llm = AzureChatOpenAI(
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
openai_api_version="2024-02-15-preview",
azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"),
azure_deployment="test-model"
)
4.CSV Agentの作成
次に CSV Agent を作成します。 CSV Agent は、下記のコードを実行して作成します。コード中の csv_file 変数には CSV Agent を使って、分析したい CSV ファイルのパスを設定します。
from langchain_experimental.agents.agent_toolkits import create_csv_agent
from langchain.agents.agent_types import AgentType
csv_file = "個人情報データ.csv"
csv_agent = create_csv_agent(
llm,
csv_file,
verbose=True,
agent_type=AgentType.OPENAI_FUNCTIONS,
allow_dangerous_code=True
)
5.CSV Agentの実行
次に CSV Agent で数値分析を行います。下記のスクリプトを実行して、 CSV Agent を実行します。CSV Agent の実行には run メソッドを用います run メソッドの引数として LLM への指示・質問を入力します。 run メソッドの引数を編集することで、 LLM に指示を出すことができます。今回は、男女の人数を集計してみましょう。男性が501人、女性が499人と出力されれば正解となります。
answer = csv_agent.run("男女の人数を集計してください")
上記のスクリプトを実行した結果は次のようになります。男女の人口が正しく集計されていることがわかります。

ここでは、 Code Interpreterを動作させる環境を構築し、Code Interpreter を実装してCSV形式のデータに対して数値分析をします。
今回、分析対象とするファイルは前章「 CSV Agent で数値分析をしてみよう」で用いたファイルと同様の弊社で用意した架空の個人情報データ1000件が記載されている CSV ファイルを利用し、男女の人数を集計します。
▼架空の個人情報データの一部(1000件)

以下の手順に従って数値分析をします。
1. ライブラリのインストール
Code Interpreter を利用するにあたって、必要なOpenAIライブラリをインストールします。
pip install openai==1.10.0
2. キーとエンドポイントの取得
次に Azure OpenAI Service リソースのキーとエンドポイントを環境変数に設定します。
こちらは「 CSV Agent で数値分析をしてみよう」の手順2と同様の手順となりますので、省略します。
3.LLM の設定
次に下記のコードを実行して LLM を作成します。こちらは openai ライブラリの Azure OpenAI クラス用いて作成します。この関数の引数に、 API のバージョンを指定します。 API バージョンは現時点(2024年3月時点)で最新のものを指定します。
from openai import AzureOpenAI
client = AzureOpenAI(
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-15-preview",
azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"),
)
4.ファイルのアップロード
次に下記のコードを実行してファイルのアップロードを行います。
変数 upload_file に分析対象のファイルパスを指定することで、ファイルをアップロードできます。
upload_file = "個人情報データ.csv"
file = client.files.create(
file=open("contents/個人情報データ.csv", "rb"),
purpose="assistants",
)
5.Assistantの作成
次に下記のコードを実行して Assistant を作成します。 client.beta.assistant.create の引数model には、デプロイしたモデル名を指定します。また、引数 tools に Code Interpreter を登録することで、 Code Interpreter を有効にします。
assistant = client.beta.assistants.create(
name="数値分析アシスタント",
description="テーブルデータに対して 統計、数値分析、集計などをするアシスタント",
model="test-model",
instructions="あなたはテーブルデータを分析するアシスタントです。テーブルデータに対して、必要であればpythonコードを生成して実行して統計、数値分析、集計などを行い、結果を回答してください。",
tools=[{"type": "code_interpreter"}],
file_ids=[file.id]
)
6.Thread の作成
次に下記のコードを実行して Thread を作成します。 Assistants API はこの Thread を作成してThread ごとに会話を行います。 Thread はThread ごとに id が割り当てられ、管理されます。
thread = client.beta.threads.create()
7.Thread へメッセージの追加
次に下記のコードを実行して作成した Thread にメッセージを追加します。client.beta.threads.messages.create の引数 content には、 GPT への指示を記述します。前章と同じく、男女の人口の集計を指示します。
client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content="男女の人口を集計してください。"
)
8.Assitant の実行
次に下記のコードを実行して手順5で定義した Assistant を実行して、数値分析を行います。
「 run.status:complete 」と表示されれば、実行完了です。
import time
run = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id,
)
# 実行が完了するまで待つ
while True:
# 実行状態の取得
run = client.beta.threads.runs.retrieve(thread_id=thread.id, run_id=run.id)
print("run.status:", run.status)
# completedになればループを抜ける
if run.status == 'completed':
break
time.sleep(5)
9.Response の取得
最後に Assistants API からの Response を取得します。次のコードを実行することで、 Responseを取得することができます。
messages = client.beta.threads.messages.list(
thread_id=thread.id
)
#メッセージが逆から格納されているため逆から表示する
reversed_messages = []
for msg in messages:
reversed_messages.insert(0, msg.role + ":" + msg.content[0].text.value)
for msg in reversed_messages:
print(msg)
上記のスクリプトを実行した結果は以下のようになります。 CSV Agent と同じく、男女の人口が正しく集計されていることがわかります。
また、今回の分析では生成されませんでしたが、 Code Interpreter は、回答の際にファイルを生成することもあります。生成したファイルのダウンロード方法については、以下の Azure 公式リファレンスを参照してください。
本記事では CSV Agent と Code Interpreter を用いて CSV形式のデータに対して数値分析する手順について解説しました。 CSV Agent や Code Interpreter を用いることで、 LLM 単体では実現が難しいより高度な数値分析が可能となり、 今まで正確に分析できていなかったデータをより手軽かつ高度に分析できるようになるかと思います。また、会社の売り上げやアンケート結果といった様々な統計データの集計や分析を行うといったシステムやサービス開発への応用方法も見えてくると思われます。一方で、 CSV Agent と Code Interpreter どちらも応用するにあたり、コスト面やセキュリティ面で注意すべき点があります。 「 CSV Agent で数値分析をしてみよう」でも解説しましたが、 CSV Agent は、使用コストはかかりませんが、生成した Python コードが CSV Agent の実行環境で実行されるため、意図しないコードの実行やファイル操作が行われる可能性あります。そのため実行の際は隔離された環境が必要になります。また、 Code Interpreter は 生成した Python コードを OpenAI のサーバー上の仮想的な Python 実行環境で実行するためCSV Agent と比べてセキュリティ面が比較的安全ですが、 使用にあたりAzure OpenAI Service では1セッション当たり ¥ 4.6217 ( GPT4 の1000トークン当たりの入力と同等の価格)かかってしまうといった点に注意する必要があります。これらに注意し、 CSV Agent や Code Interpreter を活用していくことで、より良い数値分析システムまたはサービス開発ができると思います。
当社では Web ブラウザからファイルをアップロードするだけで、アンケート結果などの統計情報の分析や、議事録や専門文書の要約や誤字脱字チェック、アイデア出し、文章下書き、翻訳などの日々の煩雑な業務を効率化する Azure OpenAI Service を活用した生成 AI サービス dailyAI をリリースしております。もし興味をお持ちいただけましたら、1か月間の無料トライアルを実施しておりますので、お気軽にお問い合わせください。また、当社ではdailyAI以外にも、自然言語解析を用いたAI活用支援や、手軽にアンケート分析が実施できるCogEraを用意しております。ご興味がございましたら、お気軽にお問い合わせください。最後までお読みいただきありがとうございました。
関連ページ
日常的に簡単・手軽に使用できる生成 AI サービス「dailyAI」サービス詳細はこちら |
