こんにちは。データサイエンスチームの藤 (トウ) です。
皆さんは社内にあるデータが貯まっている現状や、プロジェクトで大量のデータを扱う予定はありますか。データはたくさん貯めているけれど活用できていないという声はよく聞く話で、特に
IoT 関連のデータや社内に集まるテキストデータなどは貯まりやすいデータです。大量にあるデータを効率よく処理して、 AI も活用してみたいということであれば
Azure Databricks がオススメです。 Azure Databricks では、大規模データを分散処理して、 AI
の予測結果を可視化するといった使い方が可能です。本記事では、 Part 1 として Blob Storage にあるデータを Data Factory で
Data Lake にコピーするまで実施します。続編の Part 2 では、実際に Databricks
でデータを読み込み、英語ニュース記事のカテゴリを分類する機械学習を実施します。
下記の URL でも Azure Databricks
について触れています。 Azure Databricks
とは何か知りたい方は先に読んでみてください。
※本記事では Data Lake を連携先にしていますが、下記記事では Blob Storage
を連携先として設定しています。
https://www.softbanktech.co.jp/special/blog/dx_station/2022/0020
アーキテクチャの説明の前にシチュエーションとして以下を想定します。
社内にテキストデータ (例えば大規模アンケートデータや数年分の帳票など) が膨大にあり、活用できていないとします。デジタル化は済んでいたとしても、価値を見出せていない状況のため、データ分析をして価値があるか検討したい段階です。
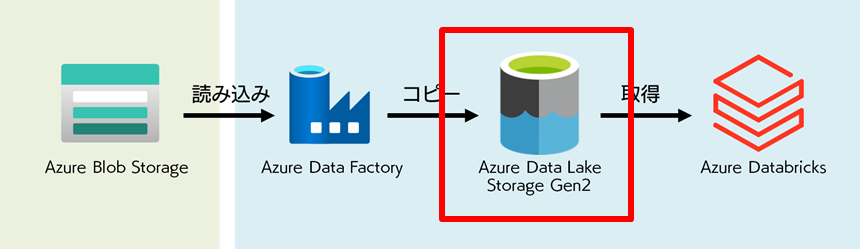
上記のシチュエーションを解決する案として、今回想定するアーキテクチャは下図のようにします。緑の部分はすでに用意されているものとして、青の部分はこれから用意するものとして捉えてください。
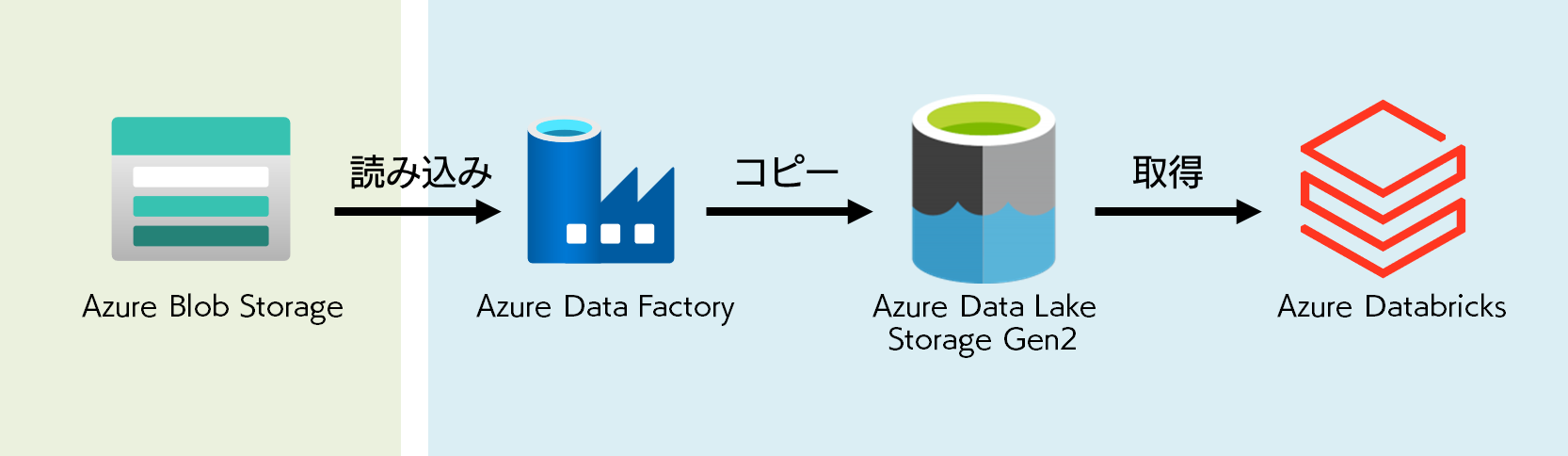
既存ストレージに保管しているデータを Azure Data Lake に移します。今回はシンプルに 1
種類のデータを引っ張ってきますが、複数のデータを取り込むことも考えて Data Lake に格納することにします。格納されたデータを Azure
Databricks で読み込み、分析します。今回は Blob Storage からデータを取得していますが、 Azure Data
Factory では Azure だけでなく、 AWS などからもデータを取得できるので、興味ある方は下記 URL
をご確認ください。
https://docs.microsoft.com/ja-jp/azure/data-factory/connector-overview
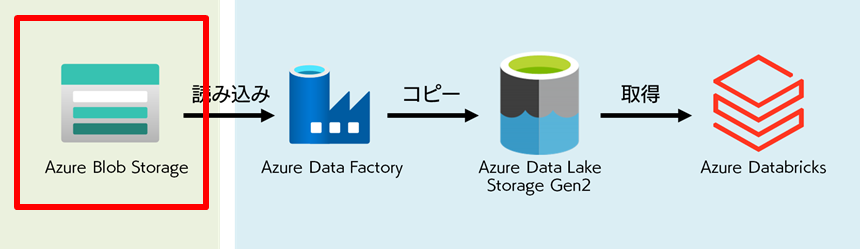
下図赤枠の既存ストレージにあたる Blob Storage に格納されているデータについて軽く触れておきます。
今回使用するデータは News Aggregator Data Set と呼ばれる英語のニュース記事のタイトルや出版社、 URL
などが集まっているデータです。データ総数としては 422,937 件で、 4 つのニュースカテゴリ (ビジネス、科学技術、娯楽、健康)
に分類されています。データの拡張子は csv です。
https://archive.ics.uci.edu/ml/datasets/News+Aggregator

※見やすいように元データを加工して掲載をしております。
ストレージの名前は stcopysource として コンテナーの名称は source にしています。
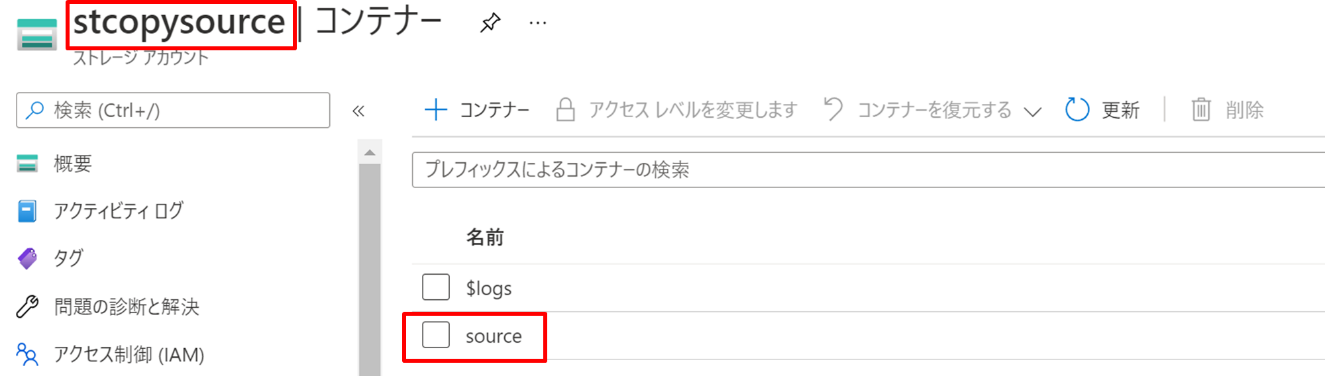
source コンテナーにデータが格納してあります。
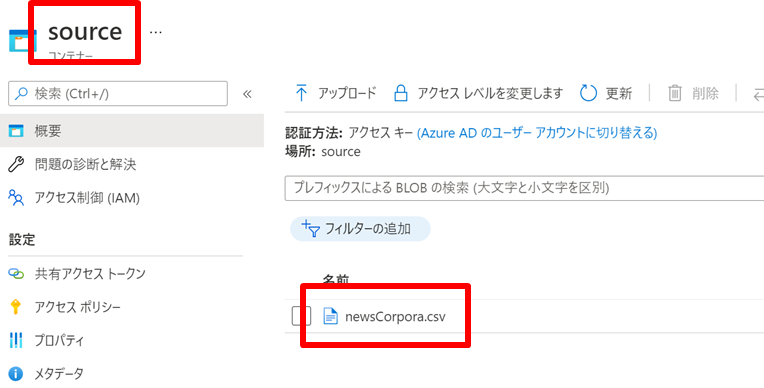
Blob Storage の作成の仕方については冒頭でご紹介したブログをご参照ください。
https://www.softbanktech.co.jp/special/blog/dx_station/2022/0020
それでは早速 Data Lake から作成していきます。下図赤枠の部分です。
Azure ポータルにアクセスし「リソースの作成」を選択します。

次に、「ストレージアカウント」を選択します。
「作成」を押下します。
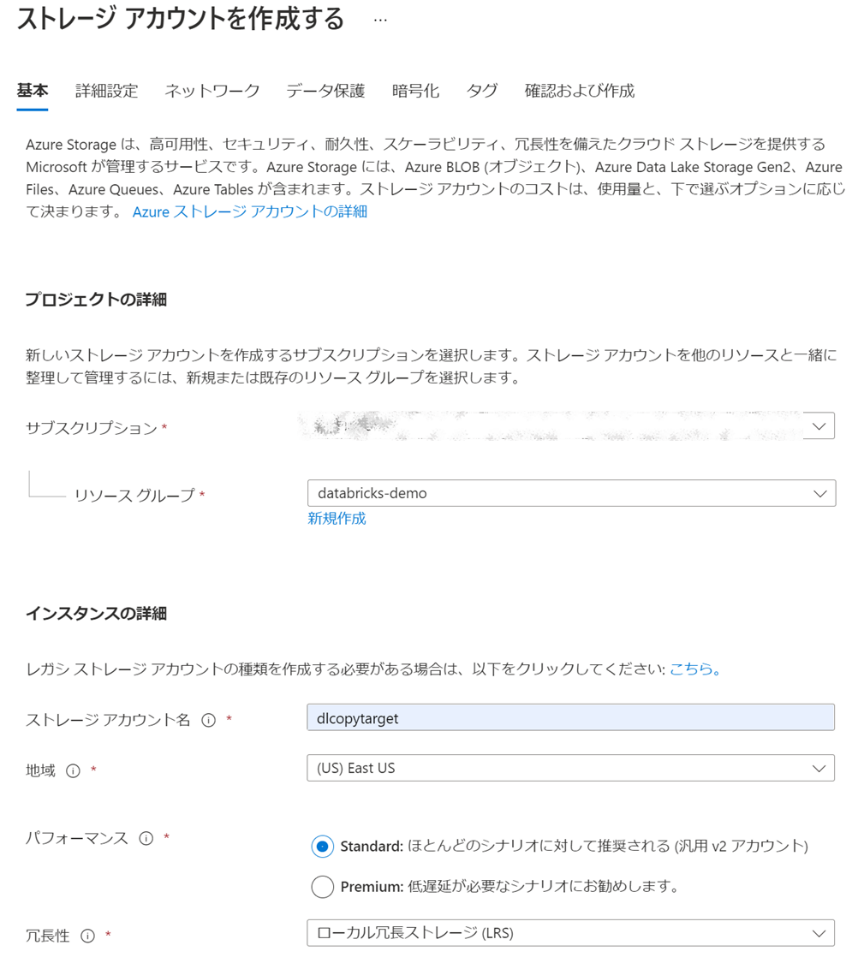
基本設定をします。今回は以下の設定にしました。
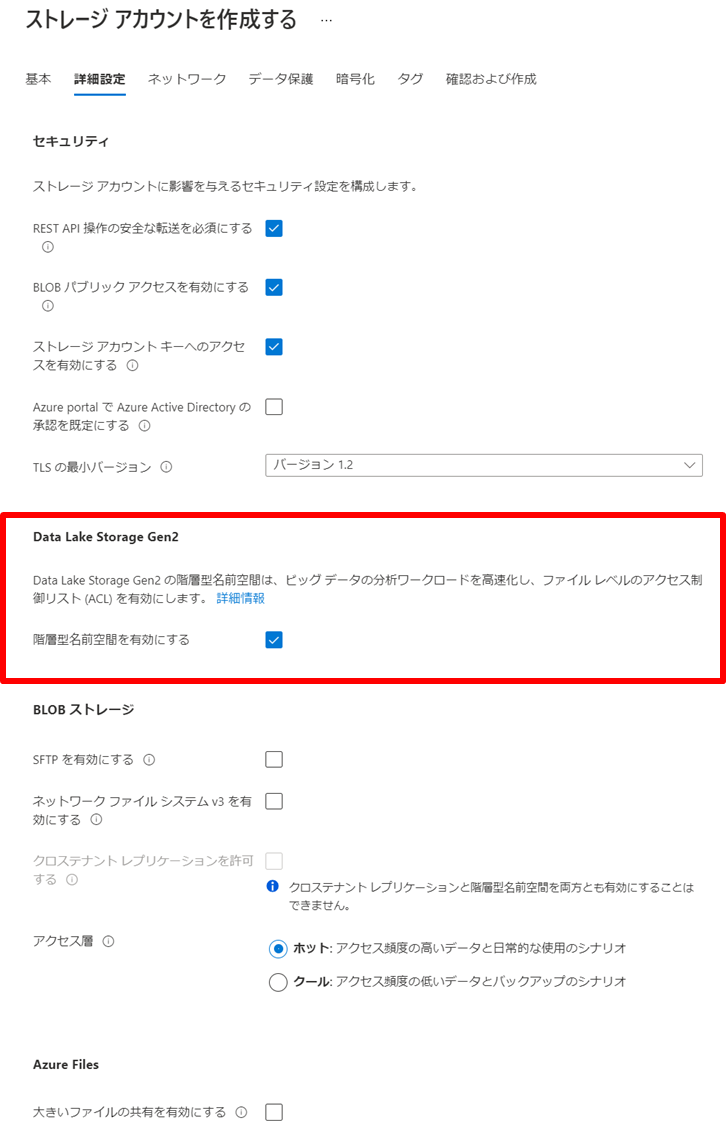
詳細設計を以下のようにします。
これ以降の設定もデフォルト設定にします。
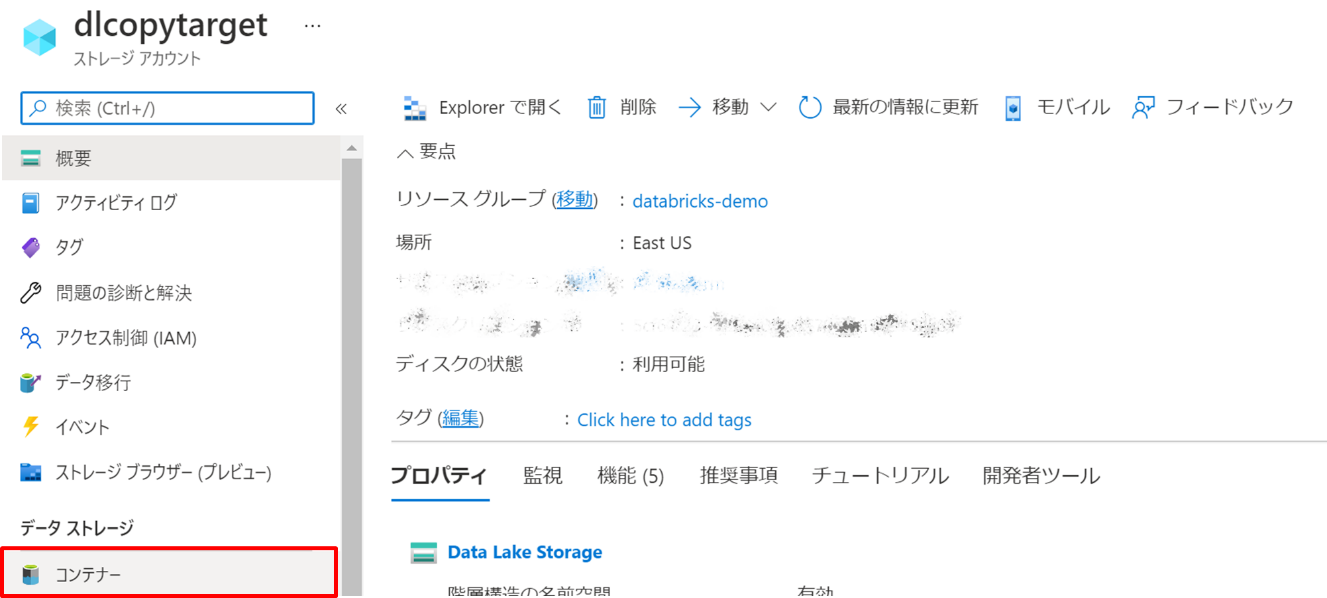
リソースを作成したら、当該リソースへ移動し、データストレージの「コンテナー」を押下します。
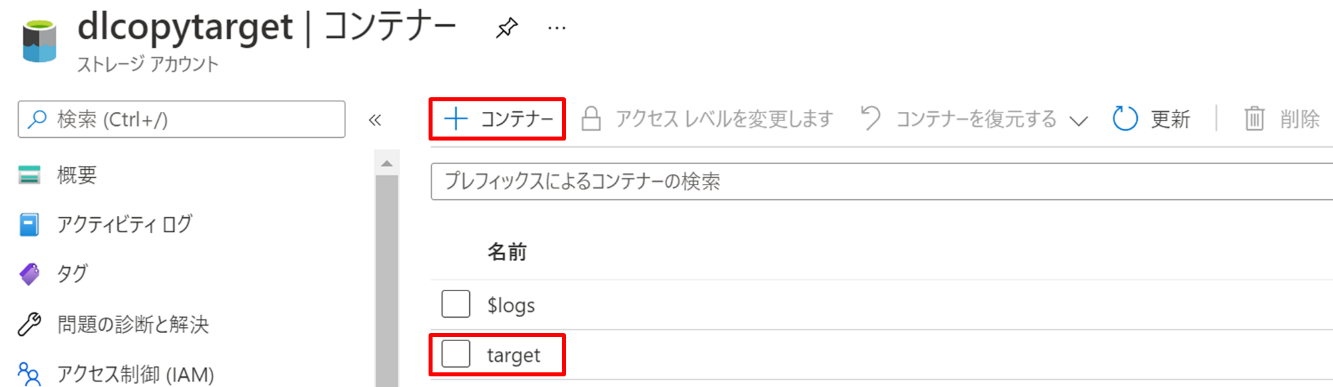
「+ コンテナー」を押下して target というコンテナーを作成します。
Data Lake の作成は以上です。
データのコピー元とコピー先が用意できたので、 Data Factory で実際にデータを読み込み、コピーさせます。下図の赤枠の部分です。
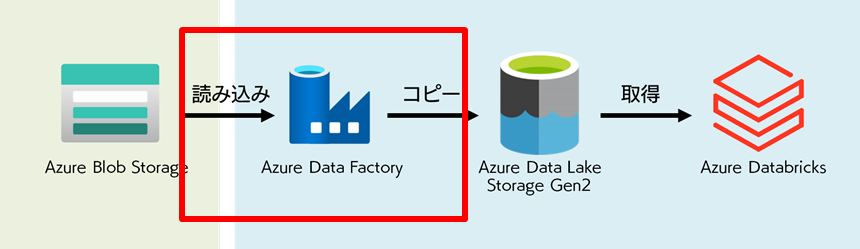
同じく Azure ポータルから「リソースの作成」を押下し、「Data Factory」と入力します。その後「作成」を押下します。
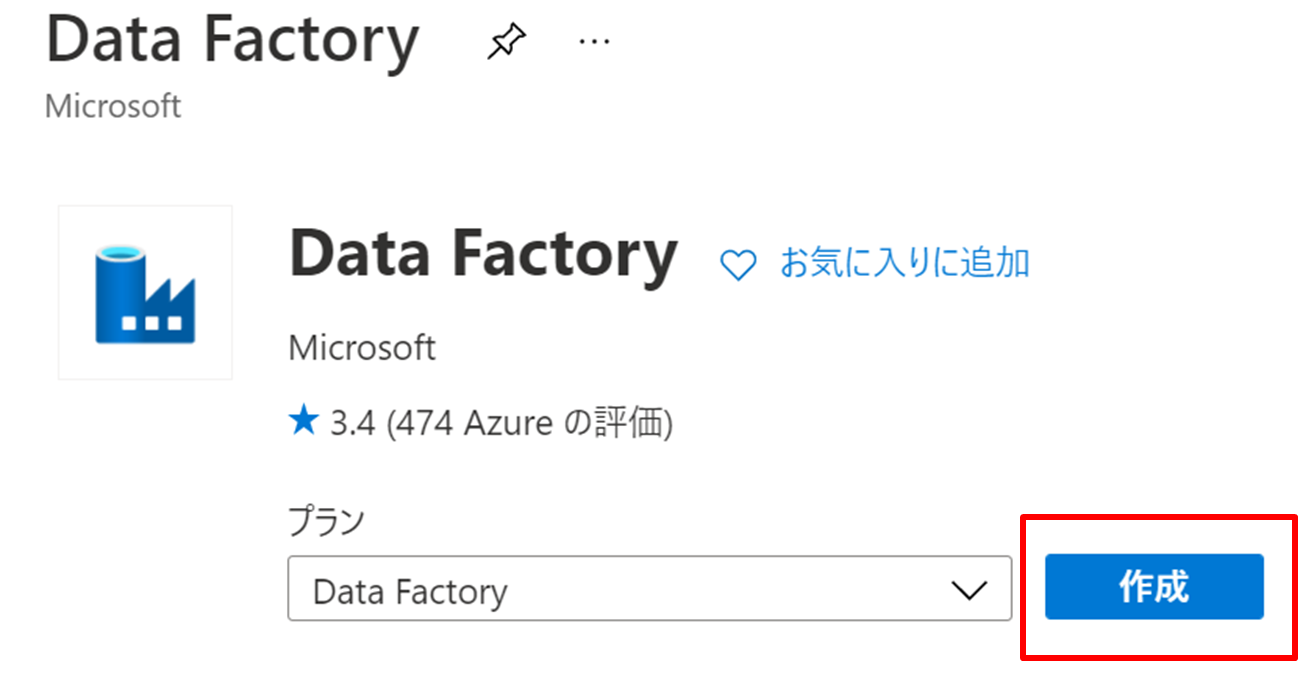
基本設定をします。
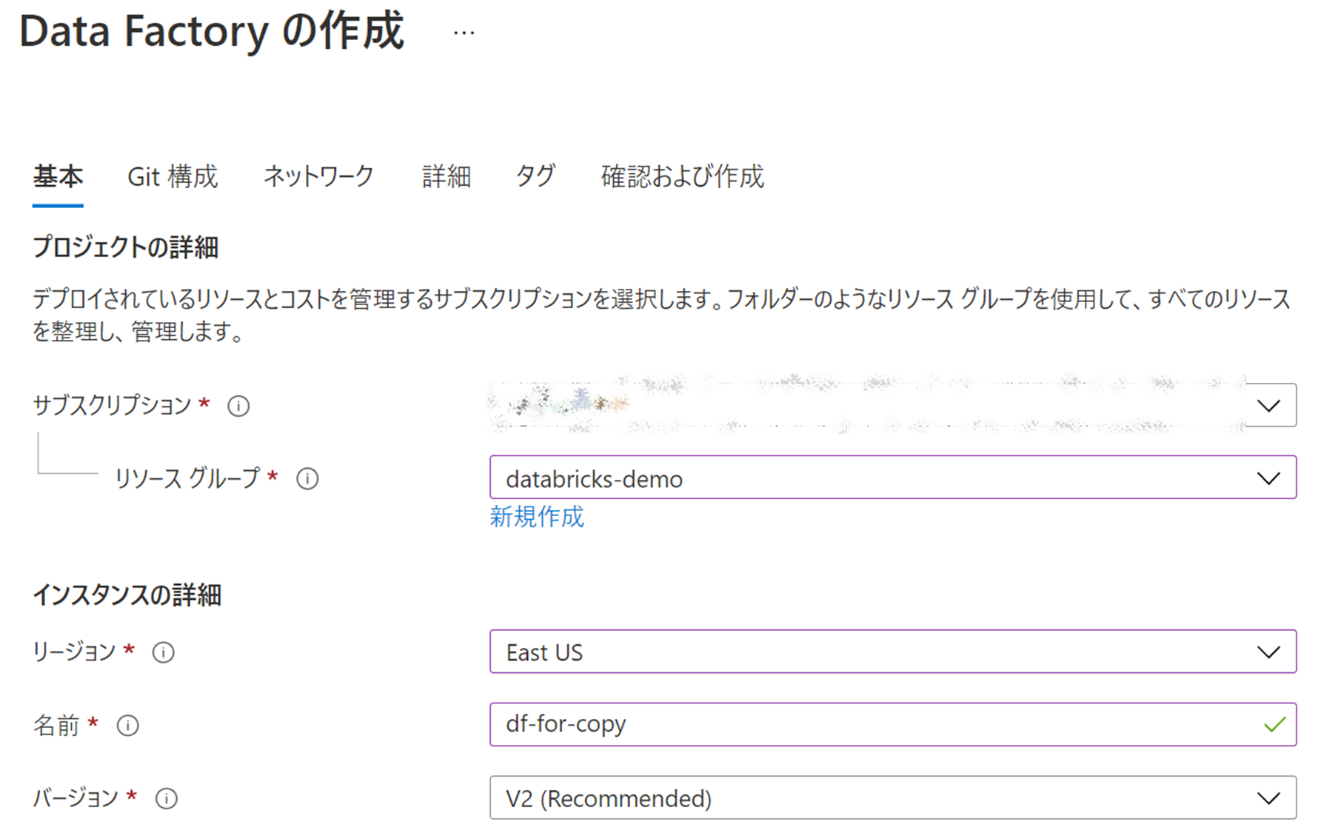
Git 構成の設定は「後で Git を構成する」にチェックをいれます。
これ以降の設定はデフォルト設定にします。
リソースを作成したら、当該リソースへ移動し、「Open Azure Data Factory
Studio」を押下します。
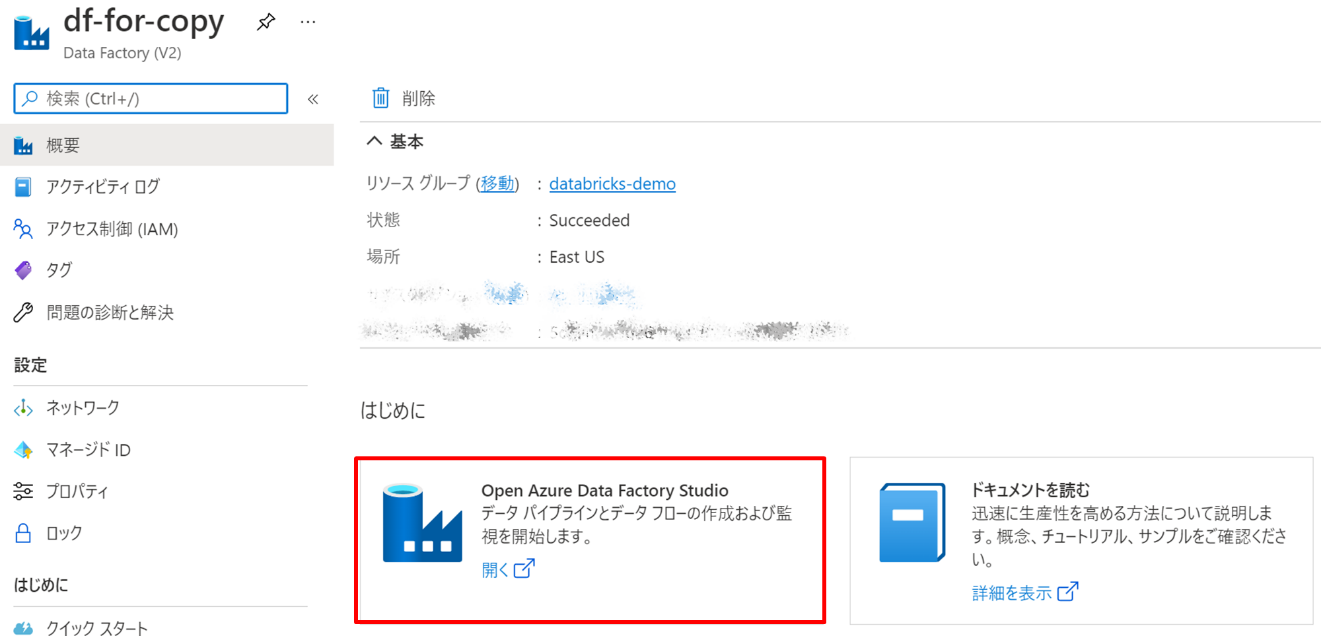
スタジオが開いたら、「取り込み」を押下します。
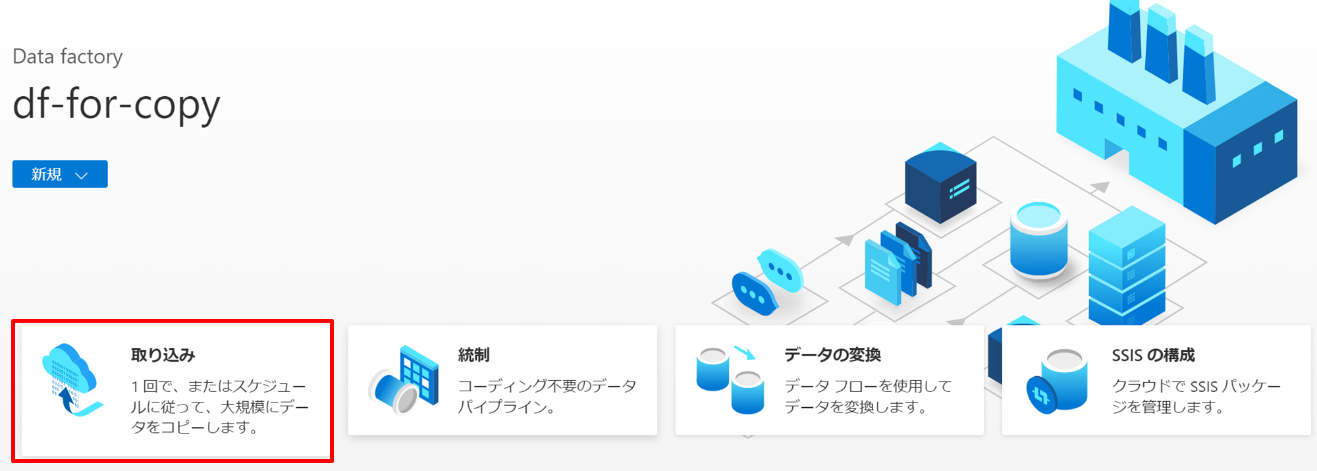
タスクの頻度またはタスクのスケジュールを「今すぐ1回実行する」にして「次へ」 を押下します。本格的に利用するならば定期的に実行できるようにスケジュールを選ぶ流れになります。

ソースデータストアは、今回で言うと csv ファイルを格納している Blob Storage にあたりますので、「Azure BLOB ストレージ」 を選択し、ストレージと接続する設定を行うために、「新しい接続」を選択します。
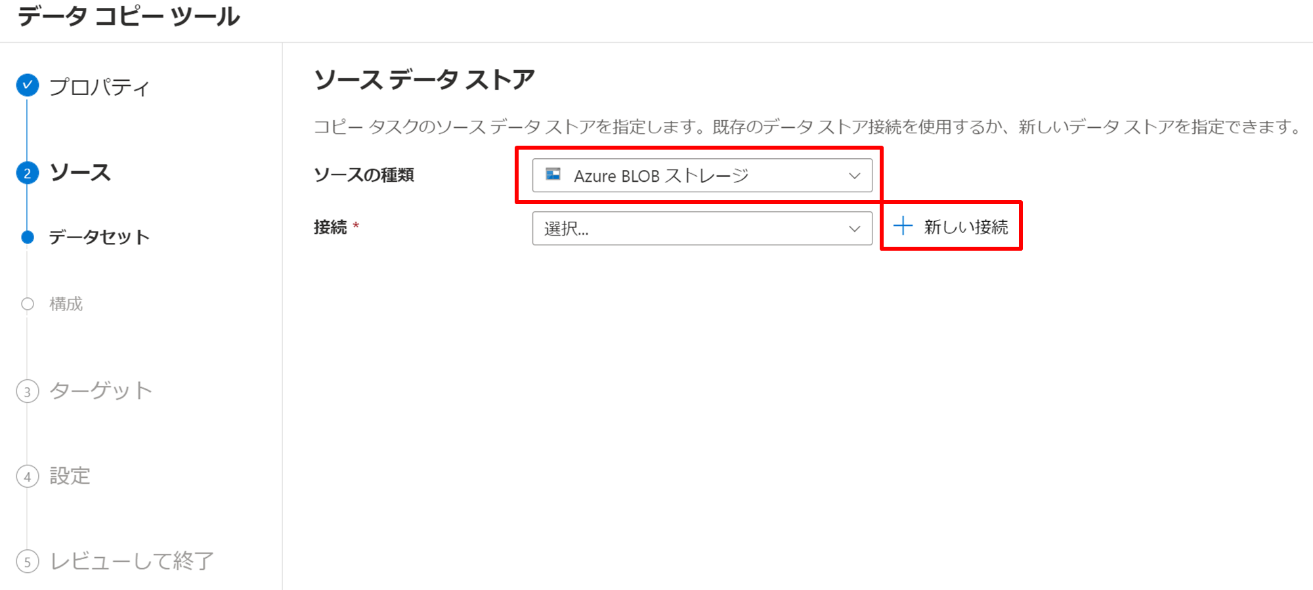
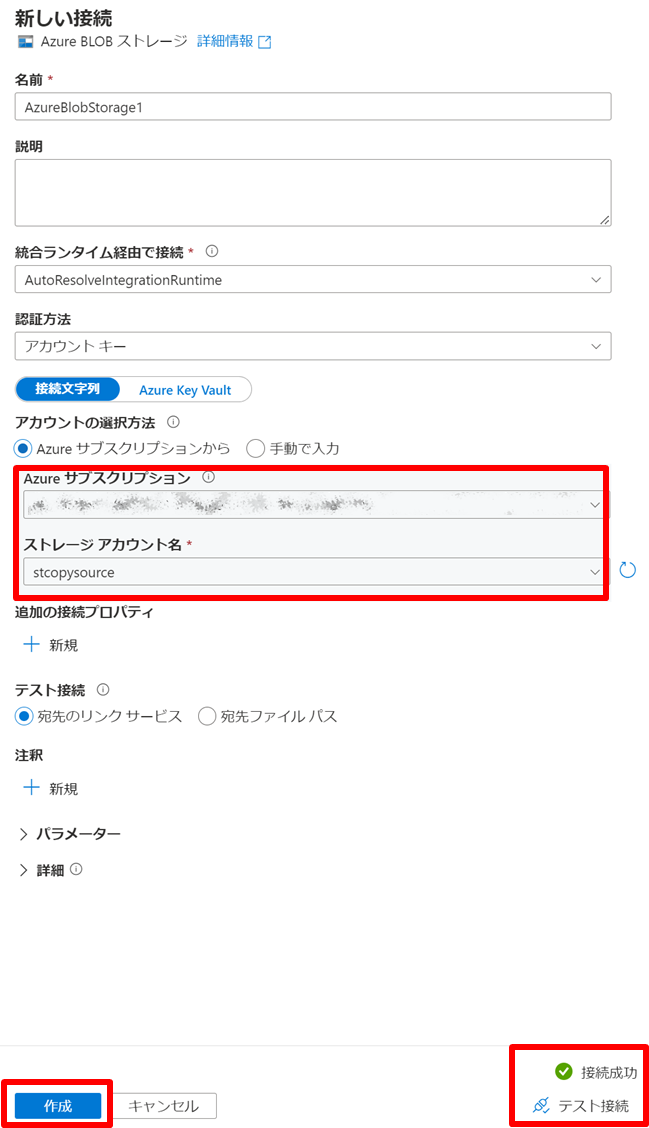
以下の設定をします。
うまく接続ができるかテストしたい場合は、右下の「テスト接続」を押下して検証できます。
ファイルまたはフォルダーの「参照」を押下して source コンテナーを選択して「次へ」を押下します。
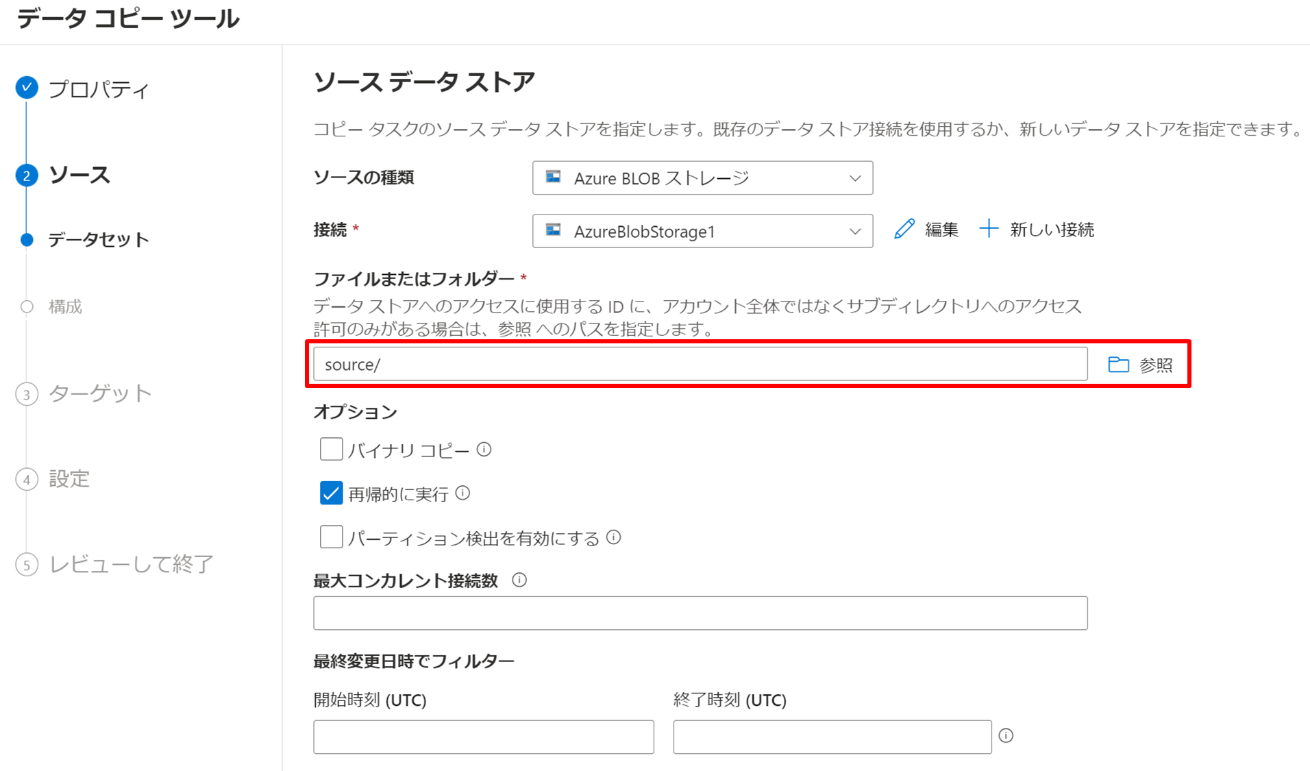
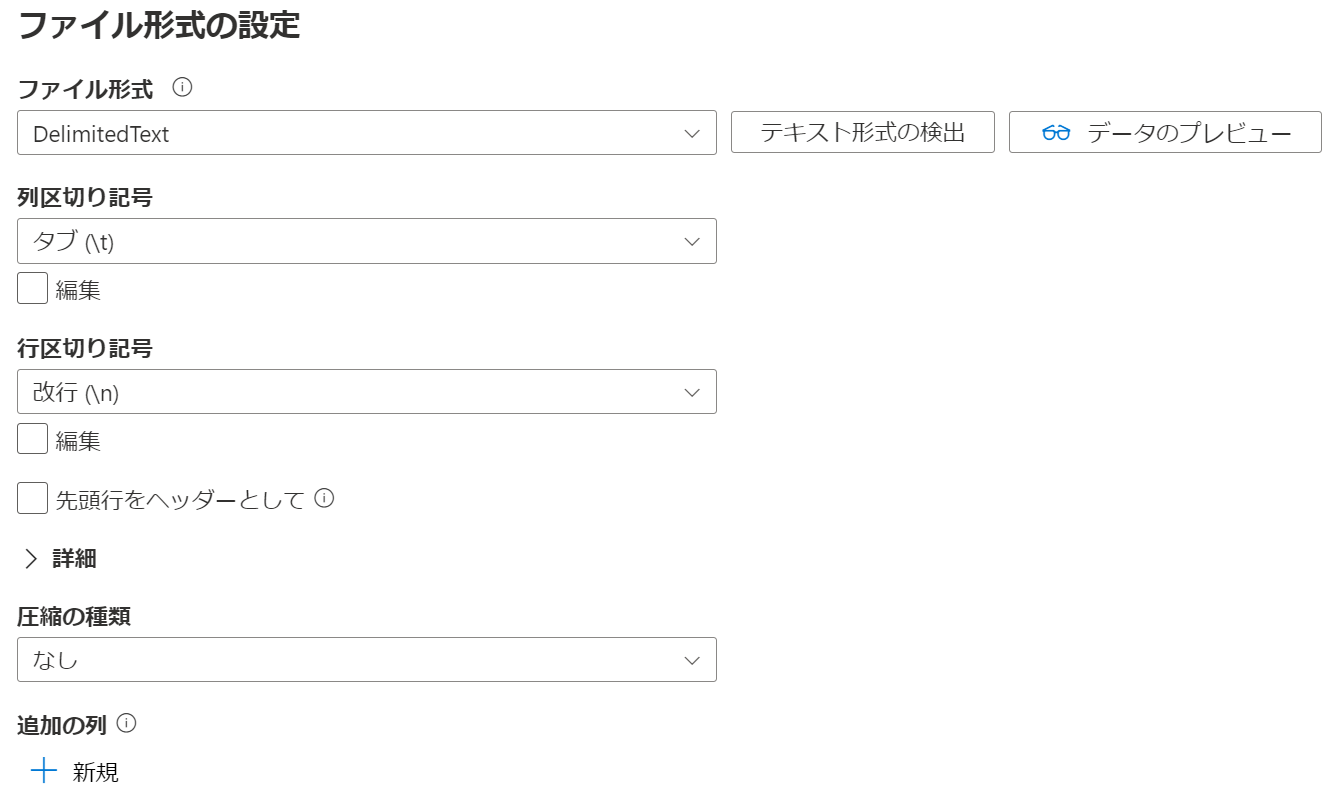
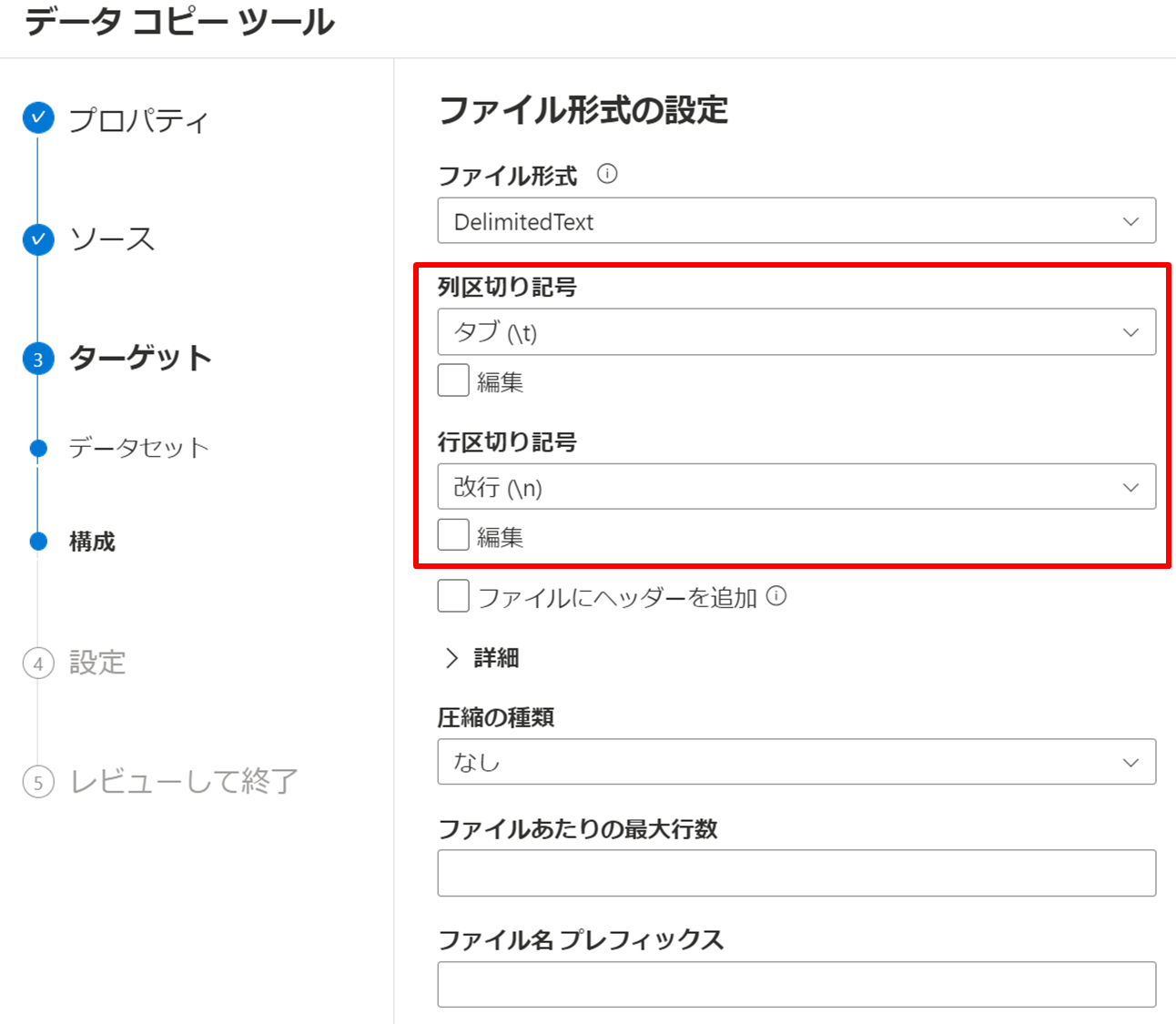
デフォルト設定のまま進めます。「次へ」を押下してください。今回の csv を開いてみると分かるのですが、中身は tsv です。それに伴い、列区切り記号はタブで問題ありません。
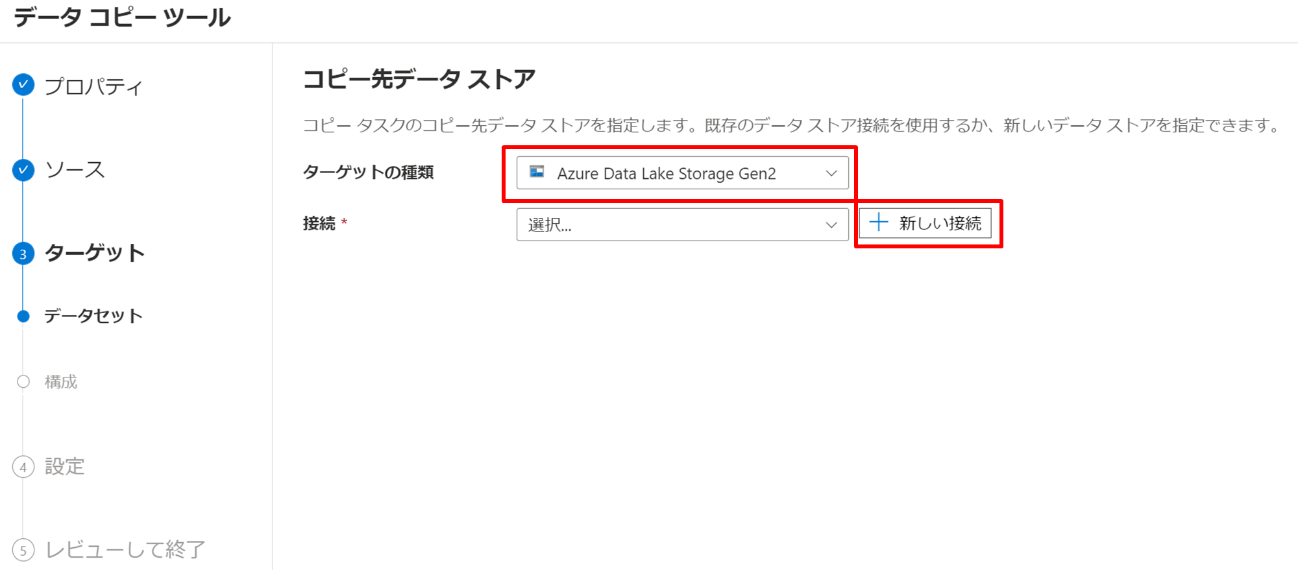
続いてはコピー先です。コピー元の設定と同じように進めます。
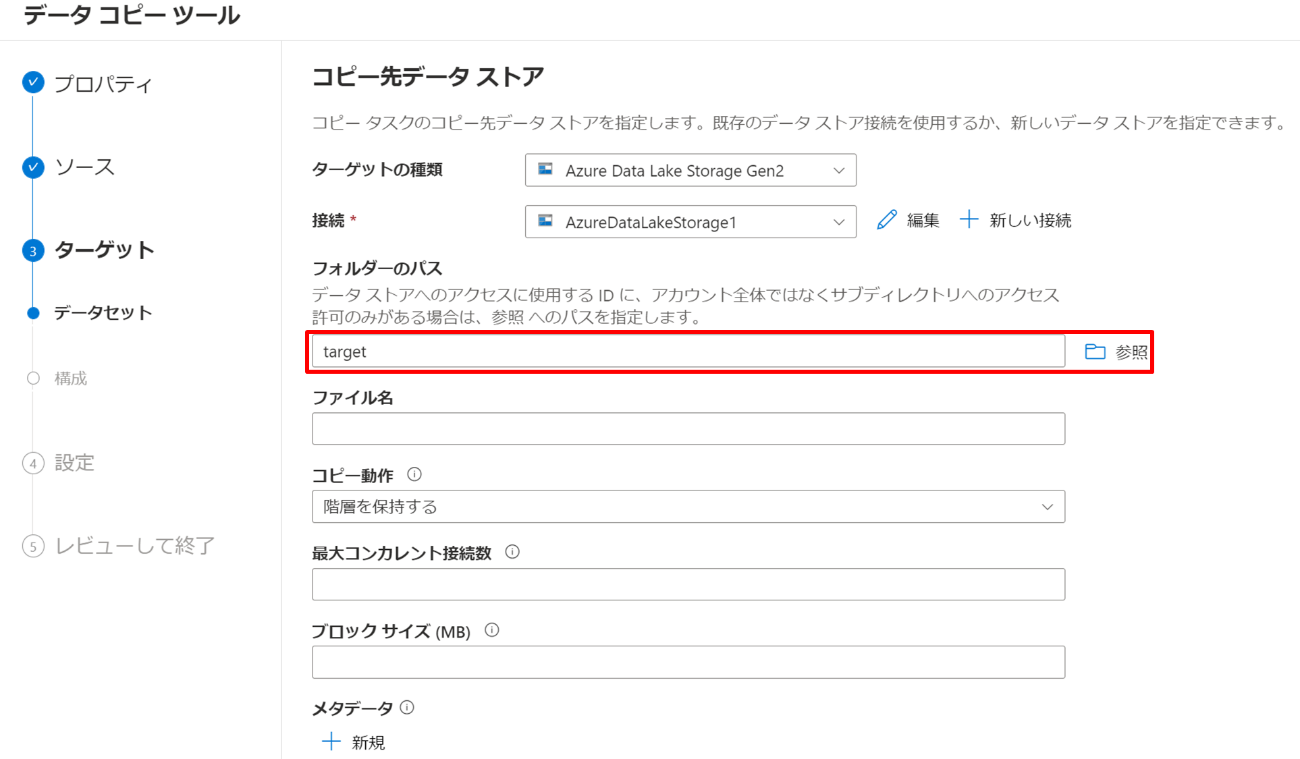
列区切り記号を「タブ (\t)」に、行区切り記号を「改行 (\n)」にして、「次へ」を押下します。
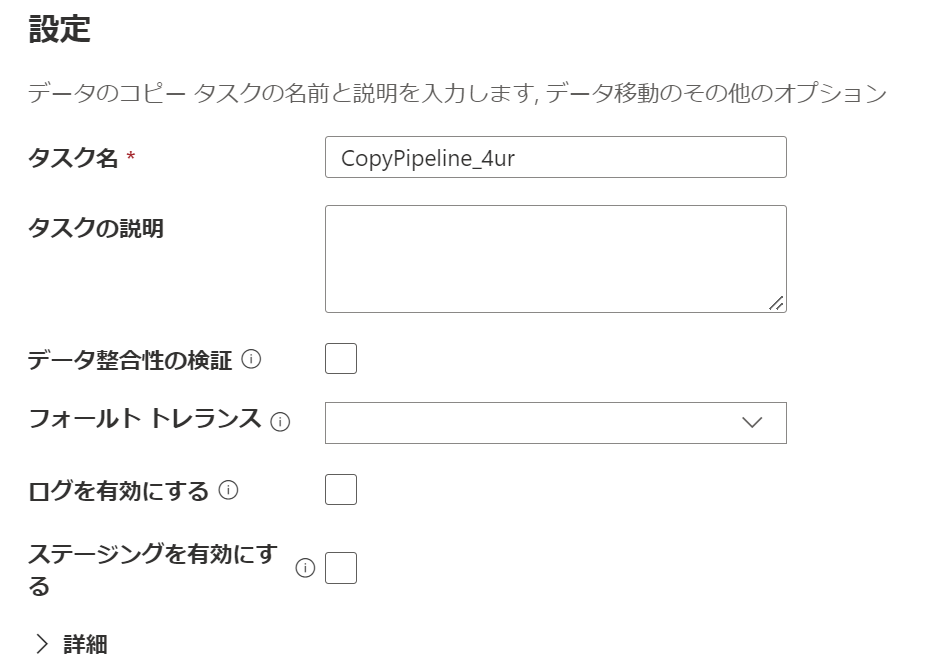
デフォルト設定のまま、「次へ」を押下します。
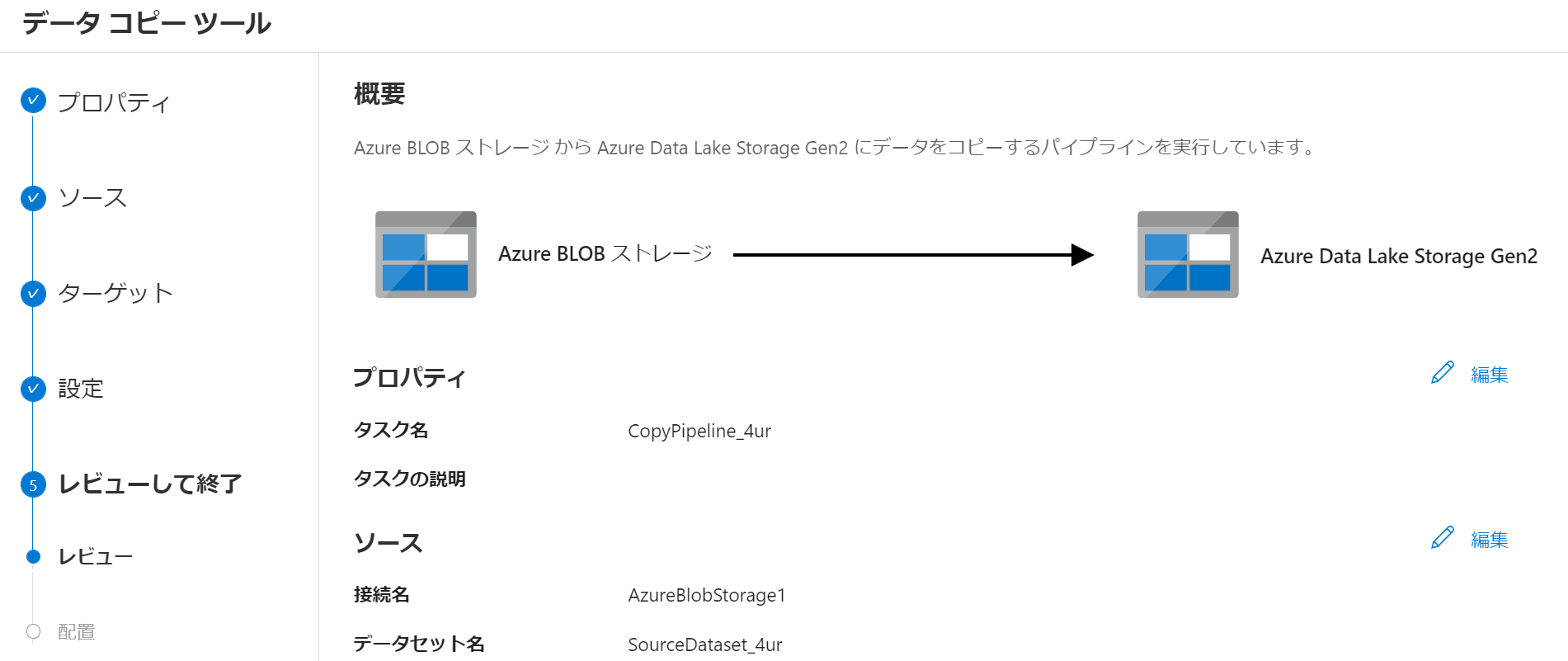
サマリーが出力されるので確認する。問題がなければ、「次へ」を押下します。
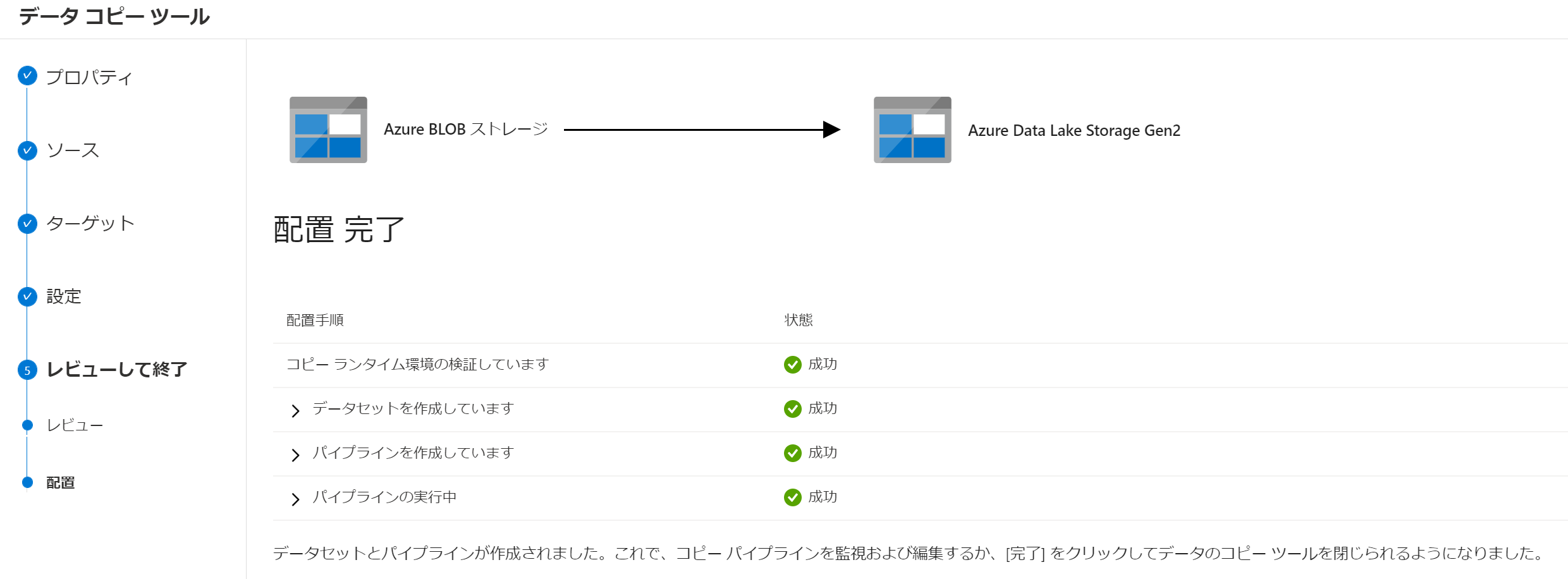
しばらくすると処理が完了し、すべて成功ステータスになることが確認できます。
実際に取り込みができているかは、 Data Lake にアクセスしてみると確認できます。
※ 今回はMicrosoft Azure Data
Explorer で確認しました。
Data Factory を使って、 Blob Storage のデータを読み込み、 Data Lake にコピーすることができました!
本記事では Azure Databricks を使用するためにデータ基盤の整備を中心に説明してきました。 Azure Data Factory で貯めているデータをインジェストして Azure Data Lake にコピーするフローは、今回のように一つのデータソースだけではなく、もっと多くのデータソースからテキストデータや外部データ集めることで真価を発揮します。この後は Part 2 として Azure Databricks を使ってデータを取得し、機械学習による分析を実施する流れをご説明する予定です。
Azure Databricks
からは少し離れますが、温度計や振動計といったセンサーデータを活用して将来の需要を予測する、または異常波形が発生していないか監視する ML
Connect
という製品を当社ではご用意しています。貯める一方で活用できていない設備データを用いて、ロスの軽減や新しい価値を模索したい方はぜひ下記 URL
をご確認ください。
https://www.softbanktech.co.jp/service/list/azure-iot/ml-connect
当社では、 AI 活用支援をはじめ、機械学習のモデル構築、クラウドを活用したシステム構築支援までご支援しています。現行の作業を軽減してより重要な作業に時間を充てたい、取得しているデータを活用して課題解決を行いたいなど AI 活用を検討中のご担当者の方、まず何からはじめればよいか悩んでいるといったお客様も、ぜひ一度お問い合わせください。
関連ページ
「CogEra」はこちら |
