こんにちは。データサイエンスチームの高橋です。
以前の記事では Transformers というライブラリを活用して BERT や ELECTRA の利用方法を紹介しました。Transformers は BERT をはじめとする自然言語処理モデルを使うときに必ずと言ってよいほど利用するライブラリで、当社でも様々な案件や業務で活用しています。
非常に汎用性の高い Transformers ですが、一方で特定のモデルをより簡単に実装できるライブラリも存在しており、目的に応じて使い分けると効果的です。そこで今回は、文章の処理に有効な Sentence-Transformers というライブラリを取り上げたいと思います。
Sentence-Transformers では文章を適切なベクトルに変換するモデルが実装されています。文章のベクトル化については後述しますが、本ライブラリを利用することで、文章の意味を比較するようなタスクで性能の向上が期待できます。これはビジネスシーンでも有用で、例えば以下のような場合での活用が考えられます。
この他でも文章の処理が伴うタスクであれば、幅広い場面で利用できるライブラリとなっています。本記事では Sentence-Transformers を実際に利用してみることで、使い方や有効性を確認していきます。
冒頭でも文章をベクトル化すると述べましたが、まずはその意味について説明したいと思います。そもそもベクトルとは「向きを持った量」と説明されますが、数字の並びで表現される配列のようなものという認識で問題ありません。n 次元のベクトルであれば n 個の数字の並びとなります。機械学習における特徴量はもっぱらベクトルの形で表現されます。したがって文章のベクトル化とは、文章を数字の並びで表現することになります。ただ注意点として、文章を文字コードに変換してベクトル化するような操作ではありません。文章の特徴をうまく表現するようにベクトル化する操作になります。具体的なアルゴリズムは省略しますが、基本的には先に単語をベクトルで表現してから、それらを集約することで文章をベクトル化します。文章ベクトルを利用することで文章間の意味的な類似度を定量的に測れるようになります。
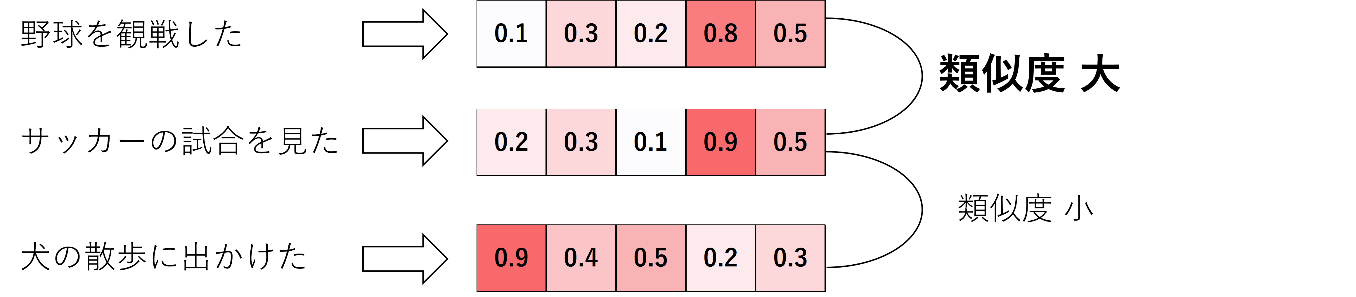
Sentence-Transformers は、その名前の通り文章を対象とした Transformer ベースのモデルが利用できる Python のライブラリです。実装されているモデルを利用することで、前章で説明したような文章ベクトルを簡単に作成することができます。この文章ベクトルを利用すると、文章の分類や類似文章の検索といったタスクを高い精度と効率で実行することが可能になります。
本ライブラリは pip で簡単にインストールすることができます。
pip install -U sentence-transformers
Pytorch と Transformers がベースとなっており、Transformers で利用したモデルをそのままロードして使用することができます。
実装されているモデルは Sentence-BERT がベースとなっており、これは BERT に対して Pooling やLoss を工夫することで、より質の良い文章ベクトルを生成するモデルです。具体的にどのような Pooling や Loss が実装されているかは次の章で紹介します。
機械学習をはじめると Pooling や Loss という単語をよく目にすると思います。Sentence-Transformers でも文章ベクトルを得るために様々な種類の Pooling や Loss が用意されており、目的に応じて選択できるようになっています。
Pooling は日本語でも「プーリング」とそのまま呼ばれることが多く、あえて訳すなら集約のような操作となります。平均をとるような操作がイメージしやすいと思います。文章ベクトルを作成する場合においては、BERT などから出力される単語ベクトルを集約する操作に対応します。Sentence-Transformers では以下の 3 種類の Pooling が用意されています。
Loss は日本語では「損失」と表現されるのですが、「誤差」と言った方がイメージはつきやすいかもしれません。通常の教師あり機械学習では、推定したラベルと真のラベルの Loss を小さくするように学習することが多いと思います。このように「ラベルの推定」のみに興味がある場合は、通常の教師あり機械学習のアプローチが採用されます。一方で、文章ベクトルのように「特徴量の表現」自体に興味がある状況では、特徴量間の距離から Loss を算出して学習する方法があります。このような方法による学習はメトリック学習と呼ばれ、Sentence-Transformers による文章ベクトルの作成にも、メトリック学習のアプローチが採用されています。
Sentence-Transformers では 14 種類の Loss が実装されており、ほとんどがメトリック学習に使われるものとなっています。この中から 3 つだけピックアップして紹介したいと思います。
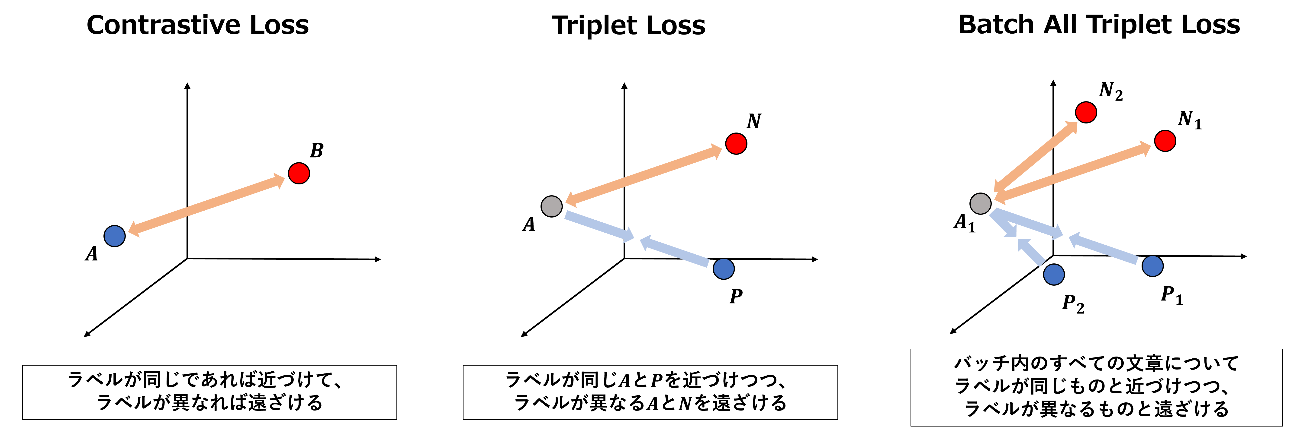
他の Loss に関しても、公式のリファレンスにて説明されています。興味がある方はぜひご覧ください。
本記事では BERT の事前学習済みモデルと Triplet Loss を利用して、文章ベクトルの作成とその可視化をしてみようと思います。
文章ベクトルの作成にあたって、以前の記事と同様の事前学習済みモデルを利用していきます。
データセットも前回の記事と同様に Livedoor ニュースコーパスを利用します。Livedoor ニュースコーパスは、ライブドアニュースの記事が 9 種類のカテゴリに分類されているものです。今回はカテゴリのラベルを推定するのではなく、Triplet Loss を利用し、同じラベルの文章ベクトルを近づけて、異なるラベルの文章ベクトルを遠ざけるようにモデルを Fine-Tuning していきます。

Triplet Loss を利用するにあたって、上記のようなデータから下記のような Anchor, Positive, Negative から成る Triplet データを用意する必要があります。Anchor を基準となる文章として Positive は Anchor と同じラベルの文章、Negative は Anchor と異なるラベルの文章をそれぞれランダムに抽出して Triplet とします。実装によっては学習時に逐一 Triplet をサンプリングする方法もありますが、今回はあらかじめ用意する方法で実装しています。

さっそく Sentence-Transformers を利用してモデルを実装してみましょう。Sentence-Transformers をインストール後、以下のコードを Python で実行するだけで、トークナイザと事前学習済みモデルを用意することができます。全体の流れとしては、
# 1. ライブラリのインポート
import transformers
import sentence_transformers
transformers.BertTokenizer = transformers.BertJapaneseTokenizer
from sentence_transformers import SentenceTransformer
from sentence_transformers import models
from sentence_transformers.losses import TripletDistanceMetric, TripletLoss
from sentence_transformers.readers import TripletReader
from sentence_transformers.datasets import SentencesDataset
from torch.utils.data import DataLoader
# 2. モデルの定義
bert = models.Transformer("cl-tohoku/bert-base-japanese-whole-word-masking")
pooling = models.Pooling(
bert.get_word_embedding_dimension(),
pooling_mode_mean_tokens=True,
)
model = SentenceTransformer(modules=[bert, pooling])
# 3. データの読み込み、パラメータの設定
triplet_reader = TripletReader(".")
train_dataset = SentencesDataset(
triplet_reader.get_examples("triplet.tsv"),
model=model,
)
BATCH_SIZE = 8
NUM_EPOCH = 15
EVAL_STEPS = 100
WARMUP_STEPS = int(len(train_dataset) // BATCH_SIZE * 0.1)
train_dataloader = DataLoader(
train_dataset,
shuffle=False,
batch_size=BATCH_SIZE,
)
train_loss = TripletLoss(
model=model,
distance_metric=TripletDistanceMetric.EUCLIDEAN,
triplet_margin=1,
)
モデルの用意が完了したら、以下を実行するだけで学習が可能です。
model.fit(
train_objectives=[(train_dataloader, train_loss)],
epochs=NUM_EPOCH,
evaluation_steps=EVAL_STEPS,
warmup_steps=WARMUP_STEPS,
output_path="./sbert",
)
モデルの利用も非常に簡単です。テスト用に分割したデータを作成したモデルに入力することで、簡単に文章ベクトルを得ることができます。
sbert = SentenceTransformer('./sbert')
vector = sbert.encode('ベクトル化したい文章')
前章の手順で作成した文章ベクトルを可視化することで、その性質を確認します。今回作成した文章ベクトルは BERT の出力と同じ 768 次元あります。これを t-SNE というアルゴリズムで 2 次元へと次元削減を行い可視化します。比較のため以下の文章ベクトルについても可視化を行います。
以下に結果を示します。

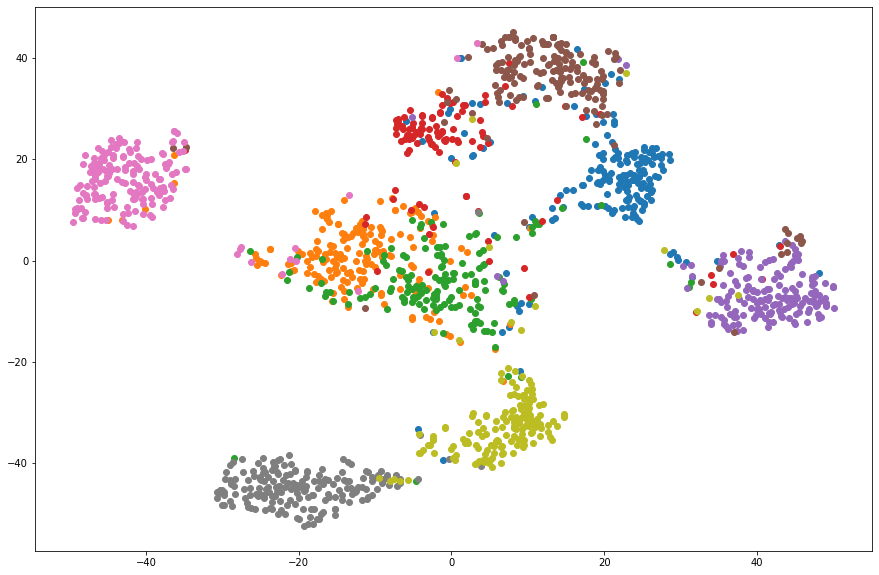
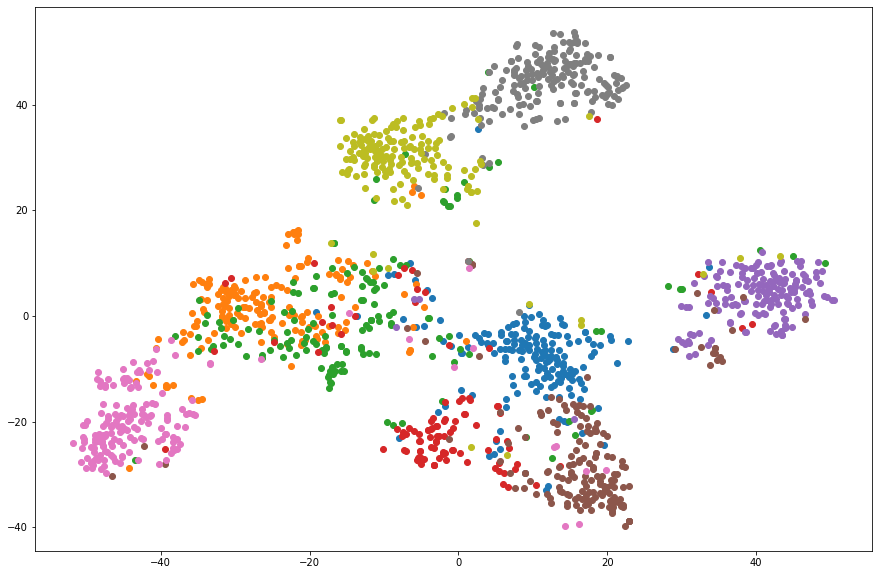
以上の結果から、Triplet Loss によって適切な文章ベクトルが作成できていることが確認できました。この文章ベクトルに対して k-近傍法を適用することでカテゴリの分類も可能であると考えられます。また今回の実験では、膨大な Triplet の組み合わせの中からごく一部を学習したに過ぎません。学習するデータ量を増やすことで、カテゴリ毎により分離された文章ベクトルが作成されると期待できます。
本記事では Sentence-Transformers を紹介し、Triplet Loss を利用した文章ベクトルの作成と可視化を行いました。今回のように最低限の実装であれば、非常に少ない記述でモデルの構築から学習、推論まで実行可能であることが確認できました。可視化結果からも適切な文章ベクトルが作成できることが確認でき、実応用も可能と考えられます。文章ベクトルは非常に汎用的な表現であり、既存のモデルに取り入れることでシステムのパワーアップにも有用だと思われます。前回の記事で紹介した Transformers と本記事で紹介した Sentence-Transformers、それぞれの特徴を考慮して使い分けていくことが、効果的な AI の活用につながると期待できます。
今回紹介したライブラリの使いやすさからもわかるように、AI を利用したデータ活用のハードルは年々低下してきています。当社でも、アンケート分析や SNS の口コミ分析向けのソリューションである CogEra や、問い合わせ対応自動化を実現する Knowledge Bot 、センサーデータの解析プラットフォームである ML Connect など、ノーコーディングでデータ活用が実現できるサービスを用意しています。また、データ活用の方針検討から AI モデルのスクラッチでの実装についても、相談したい課題がありましたら、お気軽にお問い合わせください。
最後までお読みいただきありがとうございました。
関連ページ |
