こんにちは。データサイエンスチームの大山です。
前回の記事 (以下リンク先) では、Azure Machine Learning (Azure ML) の自動機械学習 (AutoML) を使った、時系列データの予測機能について解説しました。
今回は前編、後編の2回の記事に分けて、時系列データの異常検知 (Anomaly Detection) を題材に、 Azure ML のもう一つの目玉機能である、ノーコードで機械学習モデルの構築ができるデザイナー機能の紹介をしていきたいと思います。異常検知技術は、製造業など機器から収集したセンシングデータが利用できる分野では予知保全を目的として利用されることが多いです。また Web サービスの分野でも、システムの正常性監視やネットワーク監視などに利用されており、幅広い領域で需要がある技術であると言えます。
前編にあたる本記事では、 Azure ML デザイナー で時系列データの異常検知を使用するにあたり、必要となる前提知識 (Azure ML デザイナー の概要、異常検知技術の概要、主成分分析による異常検知手法の説明、異常検知を時系列データに適用する方法) について解説できればと思います。 なお、後編となる次回の記事では、本記事の内容を前提知識とした上で、実際に Azure ML デザイナー の操作をする手順について解説していきたいと考えています。
また、当社が提供する機械学習サービス ML Connect - Anomaly Detection では、 Azure ML の機能を活用し、主に IoT 分野向けに時系列データの異常検知機能の提供をしています。そのため、 ML Connect - Anomaly Detection の特徴や Azure ML を活用したことによる利点などについても後編の記事で解説する予定です。
Azure ML デザイナーは、 Azure ML が提供するノーコードを基本とした機械学習モデル構築ツールです。操作は、自動機械学習機能と同じ様に、全て Azure ML スタジオ の GUI 上で操作することができます。そのため、 Python や R など、データサイエンス分野で良く利用されるプログラミング言語に関するスキルは要求されず、より幅広いユーザーが使用することを想定したサービスとして提供されています。
Azure ML デザイナー には、以下のサンプル画像の様に、各処理が実装されたコンポーネント (グレーの背景部分をキャンバスと呼ぶのですが、その上に配置されている四角いセルのこと) が用意されています。 コンポーネントには、データ前処理、特徴量生成処理、機械学習アルゴリズム、学習の実行処理、スコアリングや評価など、様々な処理が実装されています。そして、コンポーネントを連結した一連の処理フローのことを、 Azure ML ではパイプラインと呼びます。学習パイプラインや推論パイプラインは、これらのコンポーネントを複数連結することで構築することができます。構築したパイプラインは、異なるデータに対して学習処理を繰り返し実行したり、推論用の Web サービスとして推論パイプラインをデプロイしたりなど、繰り返し再利用することが可能です。
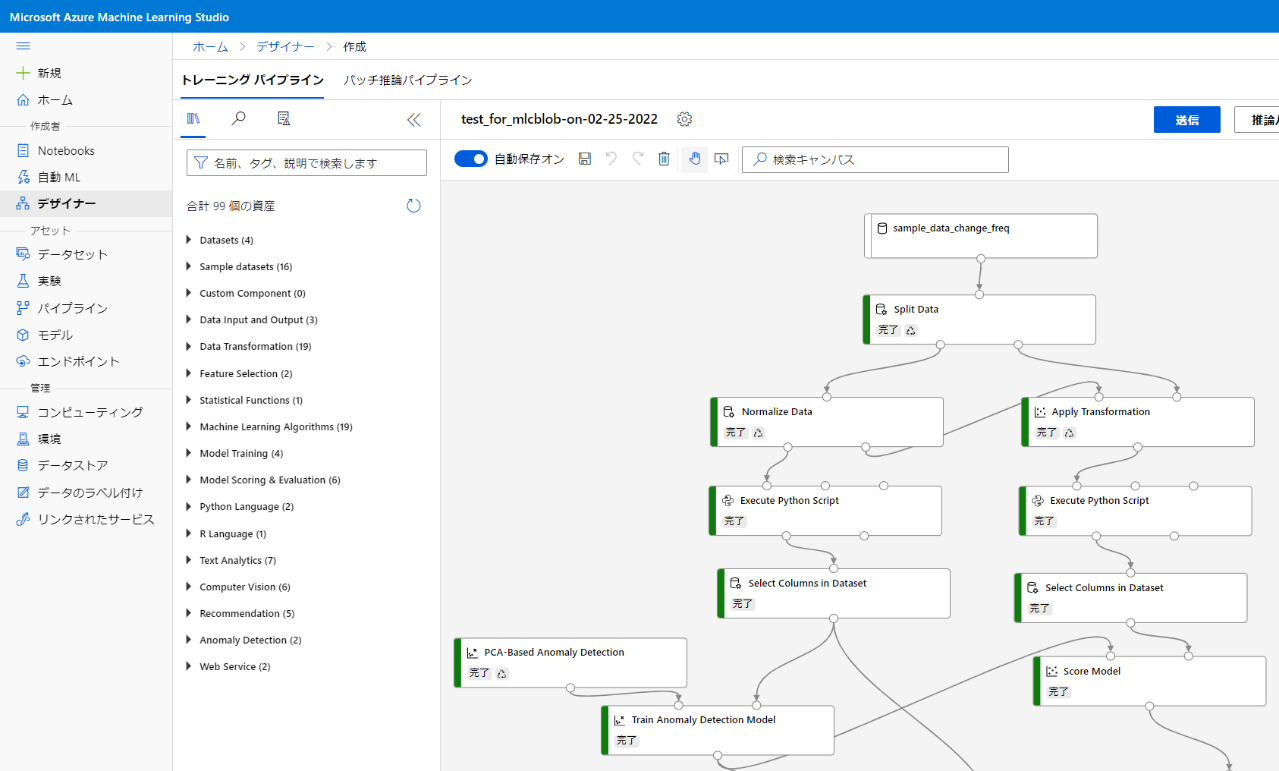
Azure ML デザイナー の詳細については、以下の Azure ML 公式リファレンスを参照ください。
異常検知と呼ばれる分野は、非常に広い範囲の技術体系を指しており、対象となるデータもテーブルデータ、時系列データ、画像データ、音響データなど多岐にわたります。そのため本節では、異常検知技術の詳細な説明には立ち入らず、その大まかな考え方や全体感の説明にとどめたいと思います。
統計学や機械学習をベースとした異常検知手法では、正常な状態との差異を何等かの方法で定量化し、その差異が大きい場合に異常であるとするのが基本的な考え方です。下図はその様な異常検知手法のイメージとなります。
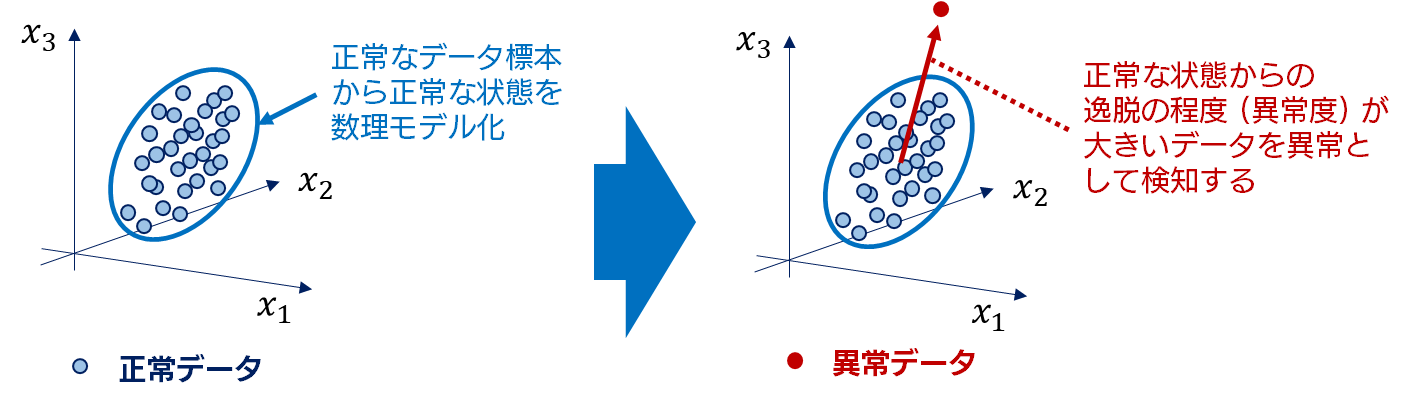
では、なぜ正常データと異常データの両方のデータを用いて分類モデルを構築するというアプローチが基本になっていないのでしょうか?十分な量のデータさえあれば、正常・異常の両法のデータによって二値分類モデルを構築する方が、分類精度が高くなると考えるのが自然です。しかし異常検知の分野では、以下の理由によって正常データを基にしてモデル化する手法が主流になっています。
※なお、少量の正常・異常のラベル付きデータを用いることで、より異常検知精度を高めるという半教師あり学習に分類される異常検知手法も近年はよく研究されています。
そうした、正常データ (もしくは多数が正常なデータ) から異常検知を行うことができる数理モデルについて、大まかにグループ分けを行うと、以下の様に分類されます。
なお、完全にどれかに分類できるわけではなく、variational autoencoder (VAE) や generative adversarial network (GAN) の様に再構成ベースかつ確率モデルというパターンも存在します。また、密度比推定の様に確率分布ではなく、その比を推定するといった手法もあるため、これらの分類はあくまで大まかな目安となります。また、時系列データの異常検知については、以下の Forecast ベースの手法もあります。
この様に、異常検知には様々なアプローチがあるのですが、 Azure ML デザイナー で利用できる手法は、2022年3月時点で、 主成分分析 (principal component analysis: PCA) を用いた異常検知手法のみとなっています。 そのため次の節では、最も基本的な再構成ベースの異常検知手法でもある、主成分分析を用いた異常検知について解説し、その仕組みについて大まかなイメージをつかんでもらえればと思います。
なお、異常検知技術に関する詳細な解説や数学を使った説明に興味がある方は、以下の書籍が大変参考になりますので、参考文献として挙げておきます。
本節では、 Azure ML デザイナー で利用できる主成分分析による異常検知手法について、その大まかなアイディアの解説をします (数式を使った話はほぼしません) 。また、この異常検知手法を時系列データに適用するには、部分時系列化と呼ばれる前処理を行う必要があるため、その処理方法についても解説していきたいと思います。
主成分分析とは、データの次元削減を行う際に良く利用される分析手法です。次元削減とは、データを表す高次元のデータベクトルをより少ない次元のベクトルに情報を圧縮して表す手法全般のことを指します (ここで言う次元は、データの項目数や列数と考えてもらえばよいです) 。この次元削減は、高次元のデータを分析する際に生じる様々な問題を解決できるため、 広い分野で利用されている分析手法です (解決できる問題の例:データ容量の圧縮、次元の呪いの解消、不要な特徴量の削減、データ可視化の容易化)。
主成分分析は、線形変換を用いた最も基本的な次元削減手法の一つで、データの情報をより効果的に表現できる座標軸 (この軸を主成分と呼びます) を推定することで、データを低次元で表現することを目指します。下の図が、主成分分析において主成分の向きを推定する際の大まかなイメージです。
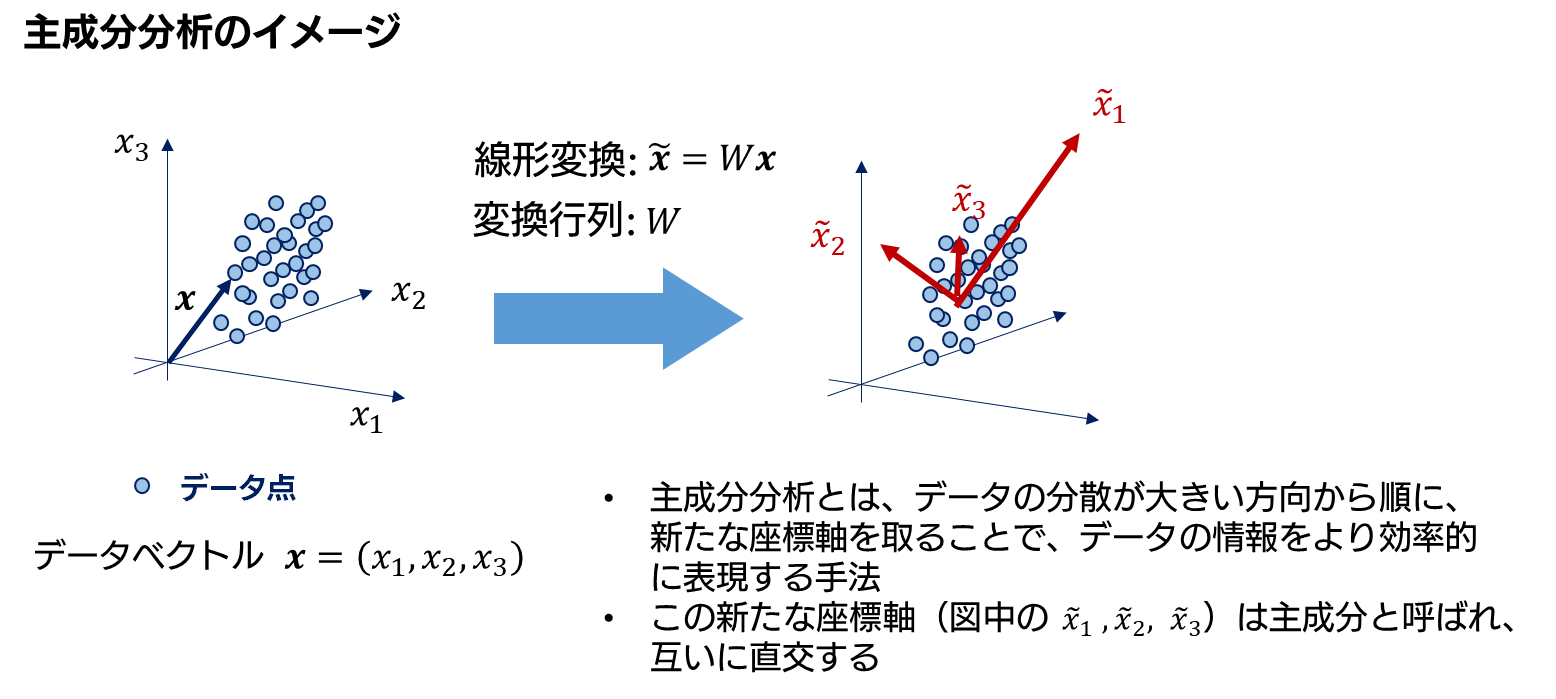
この主成分は、データの情報を多く表現している軸から順に第 1 主成分、第 2 主成分、… と呼ばれます。逆に言うと、番号が大きな主成分ほど、データの情報に関する寄与が小さいということになります。そのため、データの表現に小さな寄与しか与えない主成分への射影を無視してしまうことで、データを少ない主成分の軸だけで効率的に表現することが可能となります。これが主成分分析による次元削減の大まかな流れです (下図が、主成分分析による次元削減のイメージとなります) 。
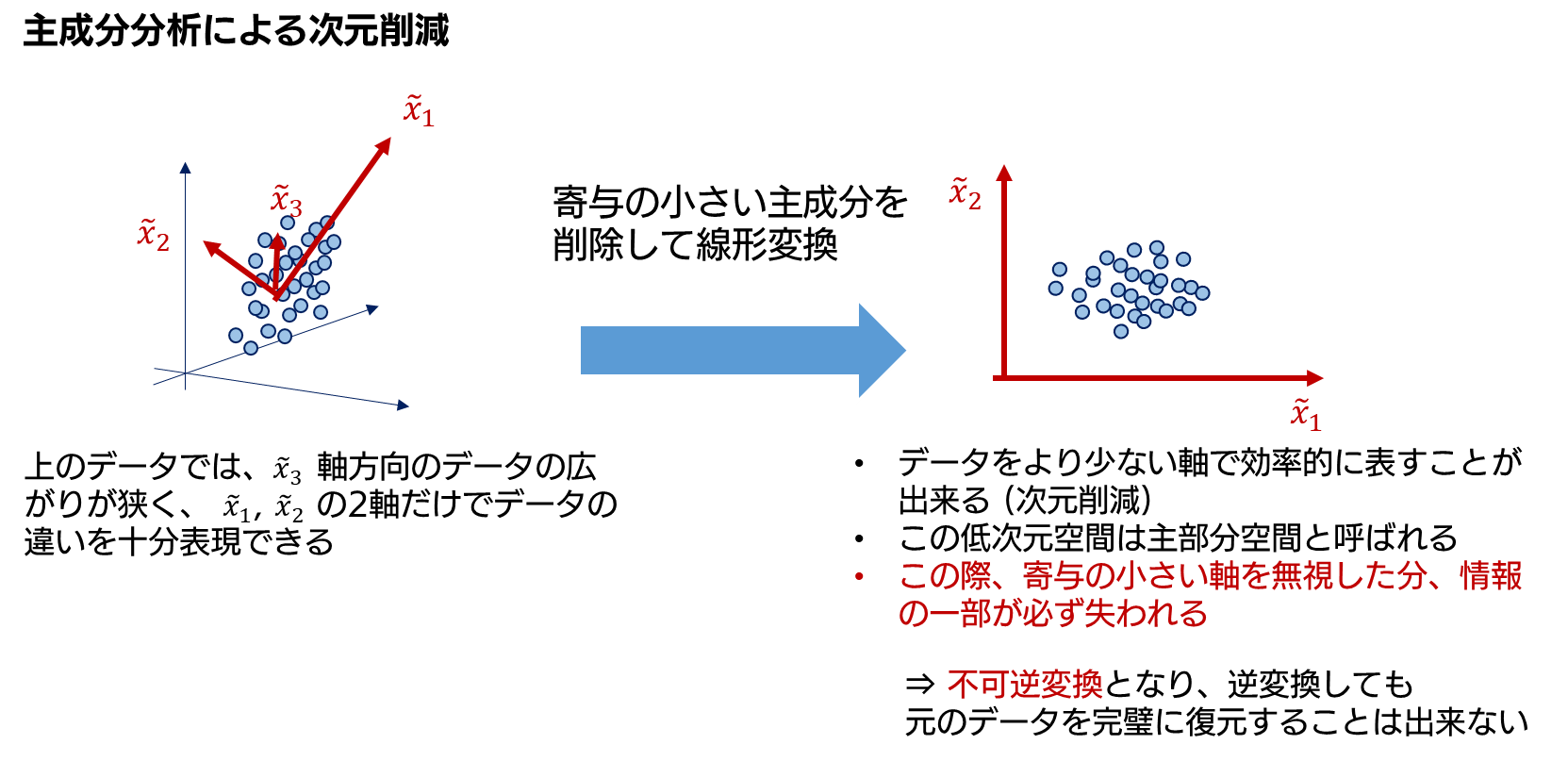
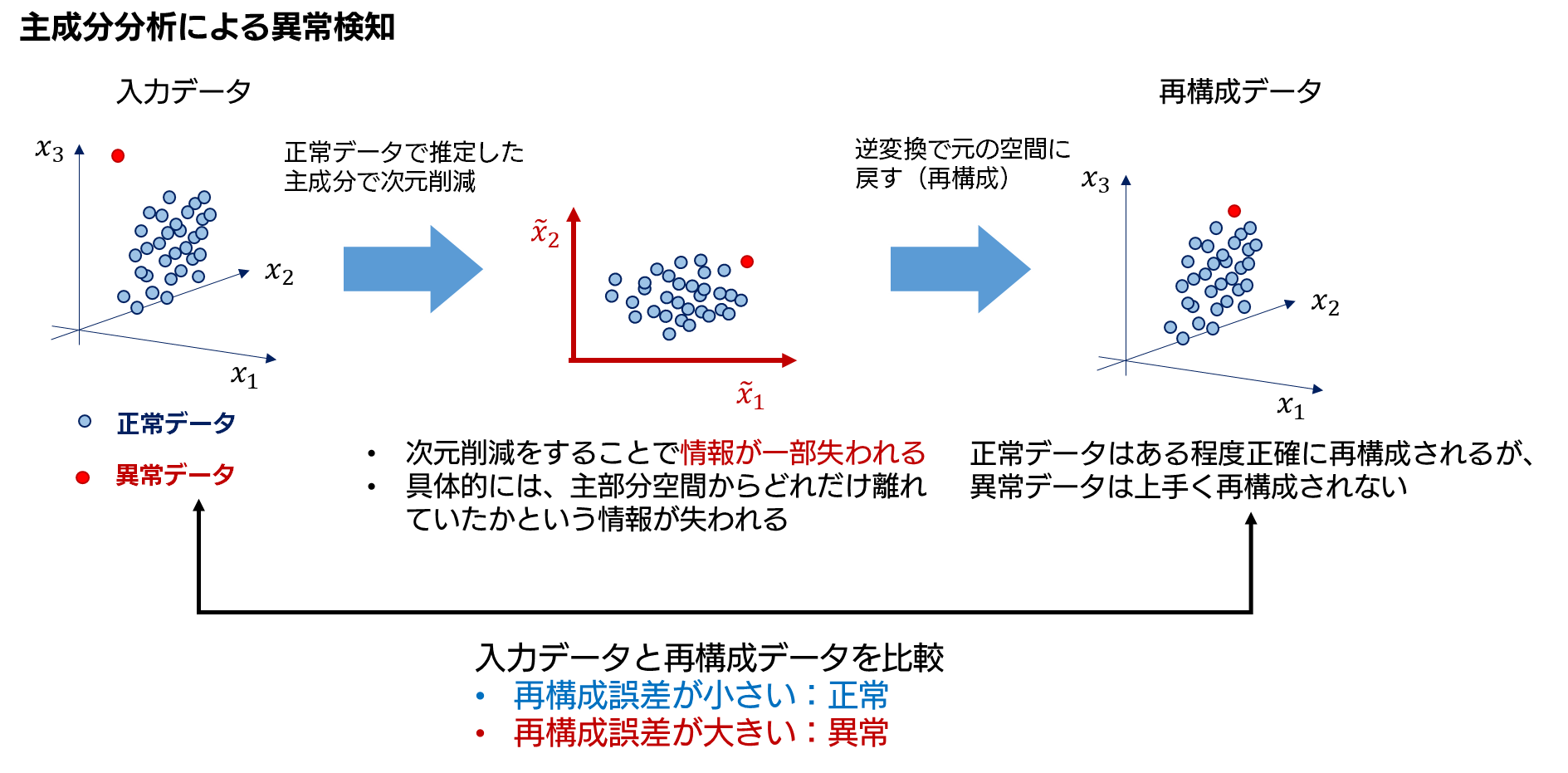
この次元削減の際、寄与の小さい主成分の情報が失われているため、逆変換しても元のデータが完全には再現されません (不可逆変換になっている) 。この様に次元削減によって情報が失われることが、主成分分析を異常検知に用いる際の重要なポイントになっています。
前述した様に、主成分分析による次元削減を行うと、データから一部の情報が削減されてしまい、逆変換を行っても元のデータを完全には再構成できません。ただし、この再構成の精度は、入力されるデータの性質によって異なってきます。まず、入力データが主成分の推定に用いたデータに近い性質を持っている場合、再構成は比較的上手く行えます (もう少し正確に書くと、ここで言う 「性質が近い」 とは、データが従う確率分布が似ているという意味合いになります) 。一方、入力データが主成分の推定に用いたデータと異なる性質を持っている場合、再構成は上手く行えません。
そのため、正常データを用いて主成分を推定しておけば、入力データが異常データの場合、次元削減してから逆変換を行っても、元のデータは上手く再構成されない結果になります。したがって、入力データベクトルと再構成されたデータベクトル間の差の大きさが、比較的大きくなるだろうと予想されます。この差の大きさは再構成誤差と呼ばれます。再構成誤差の大小は、データの異常の程度を定量的に表しているとみなせるため、この誤差をデータ毎に評価すれば、データが異常であるかどうかを検知することができるのです。この様に、再構成誤差を異常の指標 (異常度) に用いてデータが異常かどうか判定するという考え方が、主成分分析を使った異常検知の大まかなアイディアとなります (下図はそのイメージです) 。
今回、異常検知の対象に使用するサンプルデータは、以下形式の time 列と sensor1 列を持つ 1変数の時系列データです (以下の表は正常データの先頭10行分を抜き出しています) 。
| time | sensor1 |
| 2022-03-25T0:00:00 | 0.065570609 |
| 2022-03-25T0:00:01 | 0.18615289 |
| 2022-03-25T0:00:02 | 0.632584192 |
| 2022-03-25T0:00:03 | 0.863652373 |
| 2022-03-25T0:00:04 | 0.939186368 |
| 2022-03-25T0:00:05 | 0.898592237 |
| 2022-03-25T0:00:06 | 0.841505445 |
| 2022-03-25T0:00:07 | 0.854546032 |
| 2022-03-25T0:00:08 | 0.584081824 |
| 2022-03-25T0:00:09 | 0.381308443 |
グラフとして表示したのが以下の図になります。上が正常データ (2000 行) 、下が検証用の異常を含むデータ (2000 行) です。本サンプルデータは、正弦波に正規分布に従うノイズを加えただけの単純なデータとなっています。異常部分は、正弦波の周期を正常領域より短くしてあり、より高速に振動している状態として入れています。
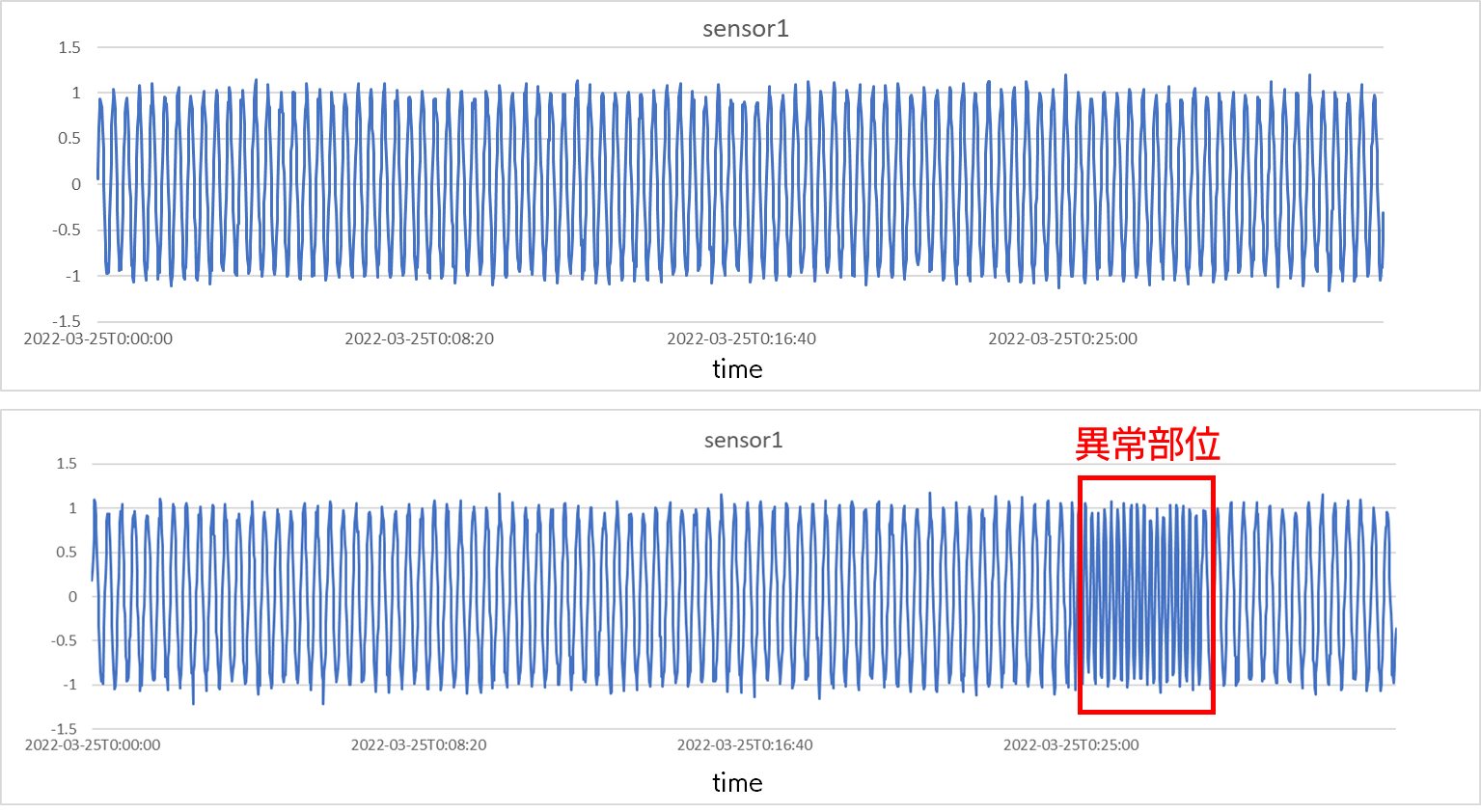
この様な異常は、単に閾値を設定するだけのルールベースの手法で検知しようとしても、数値自体は正常の範囲に収まっているため、検知することができないということになります。
さて、この様な1変数の時系列データをどの様に主成分分析が可能な形式に変換すればよいのでしょうか?この時系列データは 1 変数データであり、このままでは次元削減という操作自体ができない状態です。そこで、なんらかの方法で複数列を持つデータ形式に変換する必要があります。この際、よく使用される手法の一つに、スライド窓を用いた部分時系列化という方法があります。以下、その方法について順を追って説明します。
部分時系列とは、時系列データに対して、区間 (窓と呼ばれます) を設定し、その区間のデータだけを抜き出したデータのことです。部分時系列化では、この窓を1時点ずつスライドさせていくことで、複数列 (つまり多次元のベクトル) のデータを得ることができます。その操作を説明したのが、以下の図となります。
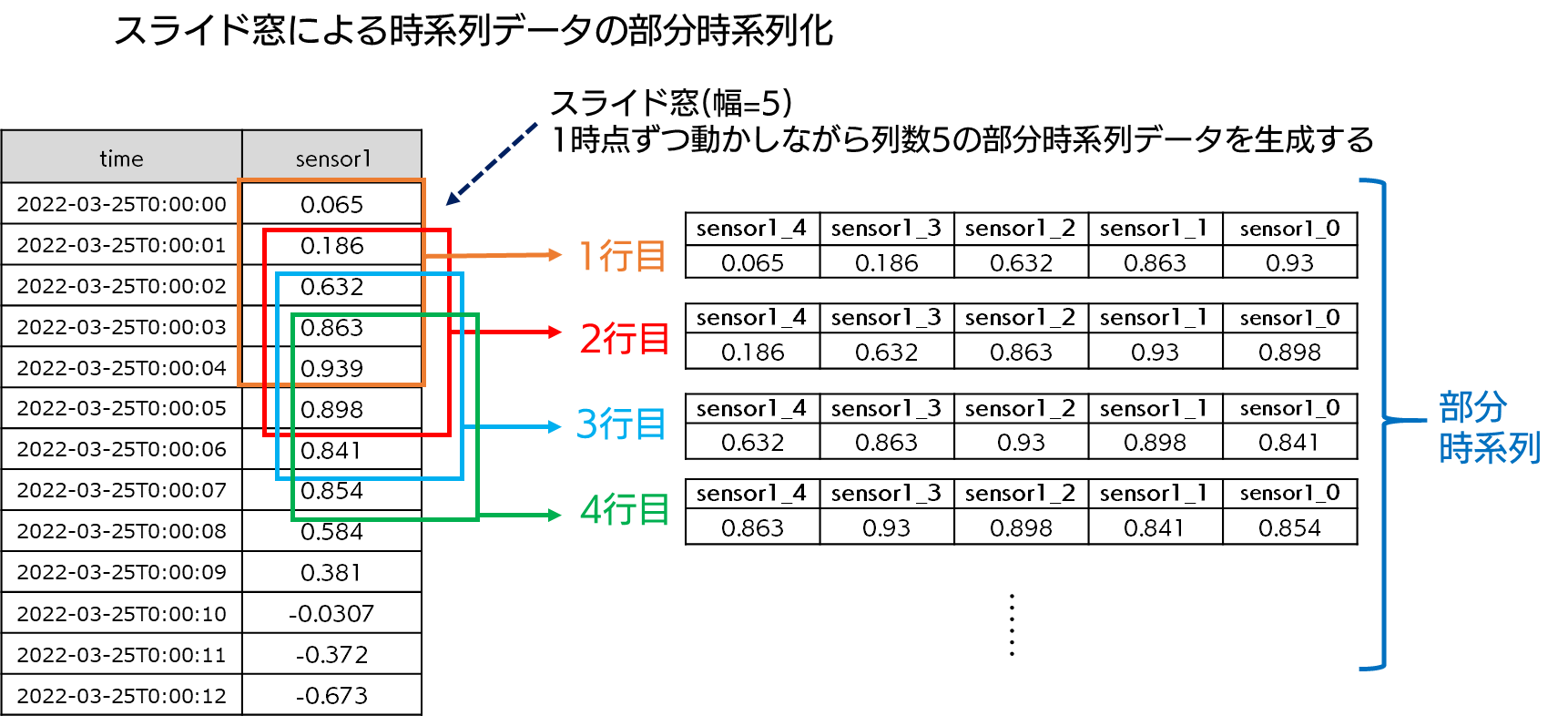
この操作は、ある時点より過去のデータ点を特徴量 (分析対象のデータの特性を定量的に表す数値のこと) にする操作を行っているということになります。この過去の自身の数値を使った特徴量のことをラグ特徴量と呼ぶこともあります。
こうして、時系列データを多変数の形式で表すことができ、主成分分析で異常検知を行うことが可能になりました。これで、必要な事前知識の説明は終わりです。次回の記事では、本節で説明した主成分分析を使った時系列データの異常検知について、 Azure ML デザイナー上で実践していきたいと思います。
本記事では、 Azure ML デザイナー を使用して、時系列データの異常検知を行うことを目指し、その際に必要となる前提知識 (Azure ML デザイナー の概要、異常検知技術の概要、主成分分析による異常検知手法の説明、異常検知を時系列データに適用する方法) を解説しました。異常検知技術は、製造業における予知保全を目的とした利用だけでなく、システムの正常性監視やネットワーク監視など、多くの業界で需要がある技術です。本記事が、異常検知技術の概念やイメージをつかむ上で、少しでも皆様の参考になれば幸いです。
今後公開する予定の後編の記事では、本記事で説明した主成分分析を使った時系列データの異常検知について、 Azure ML デザイナー 上で実施する手順を解説していきたいと考えていますので、ご期待ください。
また、当社では時系列データを対象とした機械学習システムとして、時系列データの将来値予測向けに ML Connect - Forecast、時系列データの異常検知向けに ML Connect - Anomaly Detection の2種類のサービスを提供しています。もし、自社で取得している時系列データについて、その活用方法を見出せていないなどの課題をお持ちのご担当者の方がいましたら、ぜひ当社までお問い合わせください。
なお、当社では時系列データに限らず、画像、言語、マーケティング、Web サイト、IoT 機器のセンサーデータなど、様々な領域のデータについて、 AI や機械学習を活用するための支援を行っています。業務で収集しているデータを活用したい、 AI を使用してみたいが何をすればよいかわからない、やりたいことのイメージはあるがどの様なデータを取得すればよいか判断できないなど、データ活用に関する課題であれば広くサポートしますので、その際はぜひ当社までお気軽にご相談いただければと思います。
関連ページ |
