こんにちは。 BI/Data 基盤チームの岡村です。
突然ですが、2025年にどれほどのデータ量が発生するか想像できますか?
デジタルデータ量は年々増加しており、 2025 年には全世界で発生するデータ量は 175 ゼタバイトにまで増えると予想されています。これらのビッグデータをビジネスに活用することは、企業の競争力向上・維持のために極めて重要と言えます。
本記事では、そのようなビッグデータ活用を促進するデータプラットフォームである Azure Databricks についてご紹介します。 Azure Databricks を使うことで、ストレージに格納した複数ファイルにまたがるデータの集計や成形、データのクラスタリングや機械学習モデルの作成、分析プロセス・結果のチーム間での共有、分析結果の可視化およびダッシュボードの作成まですべて Azure Databricks 上で行うことができます。本記事では Azure Databricks のセットアップからテーブルの作成までの手順について説明します。
【参照 : IDC】
https://www.seagate.com/files/www-content/our-story/trends/files/idc-seagate-dataage-whitepaper.pdf
Databricks とは Databricks 社が開発したデータエンジニアリング、機械学習、分析を支える統合データ分析プラットフォームです。巨大なデータに対して高速に分散処理を行うことができる Apache Spark をベースとしており、構造化 / 非構造化データに対してバッチあるいはリアルタイムで処理を行うことができます。
Azure Databricks は、 Microsoft Azure クラウドサービス用に最適化されたプラットフォームです。そのため Azure Databricks を使えば数分程度の時間で迅速に環境のセットアップをし、チームでのデータエンジニアリングやデータ分析が可能となります。 Python、 R、 Scala、 SQL などの言語をサポートしており、 TensorFlow や PyTorch、 scikit-learn などのフレームワークもサポートしています。また Azure のサービスとシームレスに統合することができ、データアクセスや管理の簡易化、 Azure AD を利用したシングルサインオン、新規ユーザーの作成、適切なアクセス権限の付与、ユーザーの削除に伴うアクセスのプロビジョニング解除が可能です。
【参照 : Azure Databricks】
https://azure.microsoft.com/ja-jp/services/databricks/
Azure Databricks のセットアップはワークスペース作成、クラスター作成、ノートブック作成を実施することで完了します。本章では各ステップの作成手順を説明します。
まずは Azure Portal から Azure Databricks ワークスペースを作成します。
Azure ポータルにアクセスし 「リソースの作成」 を選択します。

検索欄で 「Azure Databricks」 と検索して Azure Databricks を見つけ、 「Create」 ボタンをクリックします。

以下を参考に Azure Databricks workspace 作成時の必要事項を設定し、 「確認および作成」
をクリックします。なお本記事では下記項目以外はすべて既定値に設定しています。 「Pricing Tier」 は価格オプションのことでニーズに合わせて設定することができ、 「Premium」 レベルにすると後述するノートブック、クラスター、テーブル等のロールベースのアクセス制御や監査ログが利用可能となります。 「Premium」 は 14 日間だけ無料で使うことができるので、機能が気になる方は検証として触ってみるのも良いかもしれません。
【参照 : Azure Databricks pricing】
https://azure.microsoft.com/ja-jp/pricing/details/databricks/
これで Azure Databricks のリソースが構築できました。次に下図の赤枠で囲まれた 「Launch Workspace」 を押下して、作成した Azure Databricks workspace に移動します。
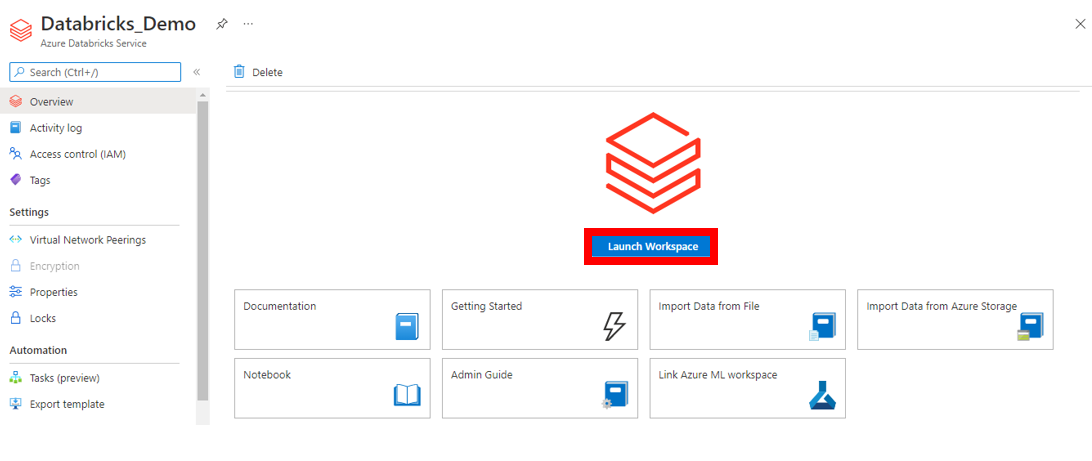
続いて Cluster を作成します。 なお Cluster とは Azure Databricks において様々なジョブの実行基盤となる計算リソースのことです。左メニューバーから 「Compute」 をクリックし、下記図の 「Create Cluster」 を押下します。
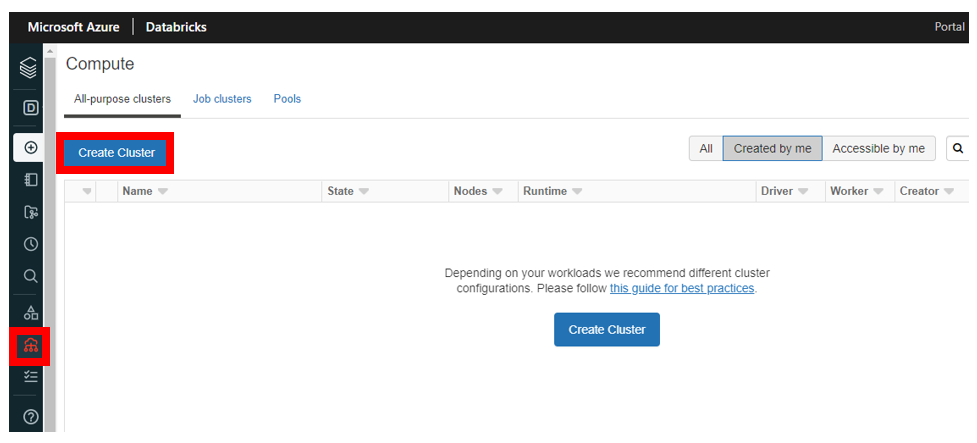
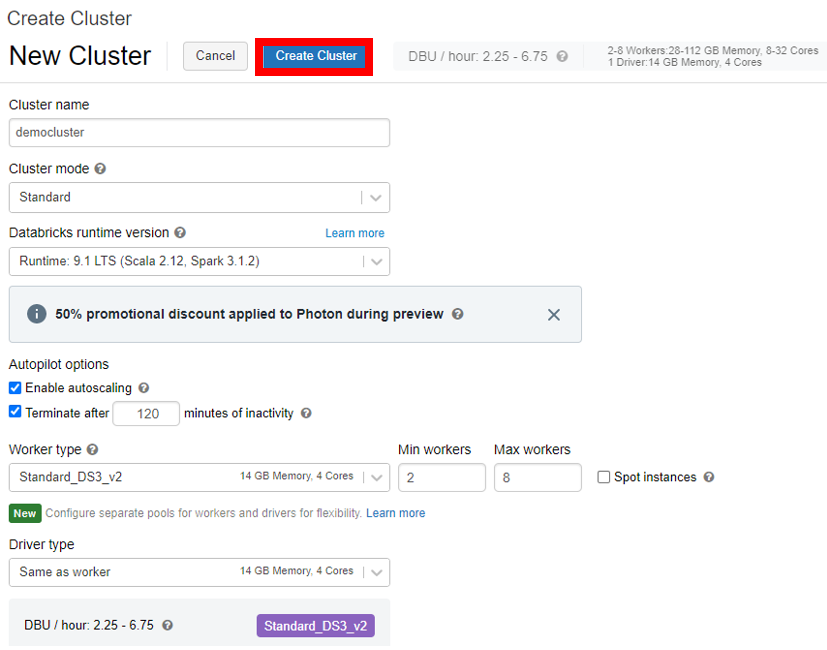
Cluster の作成画面が出てきますので、以下を参考に作成時の必要項目を設定します。下記項目以外は既定値で設定していますが、 「Terminate after 120 minutes of inactivity」 項目はクラスターの自動終了設定なので、余計な課金を防ぐためにもできるだけ短い時間に設定しましょう。また 「Enable autoscaling」 は自動スケール機能のことで、タスクに応じて、下記で設定する 「Min Workers」 と 「Max workers」 の間でワーカーを自動スケールし、並列分散処理を実行してくれます。
必要項目を設定したら、下記図の赤枠で囲まれた 「Create Cluster」 を押下します。
Cluster の作成が完了すると、下記図の赤枠で囲まれた部分のように緑のチェックマークが出てくるので、Cluster の作成が成功したことを確認することができます。なお使用している Azure Subscription の使用状況 によっては Cluster の作成が失敗する場合があります。その場合は Azure の Subscriptions の 「settings」 >「Usage + quotas」 から確認し、使用できる計算リソースを 「Worker type」 と 「Driver type」 に設定しましょう。
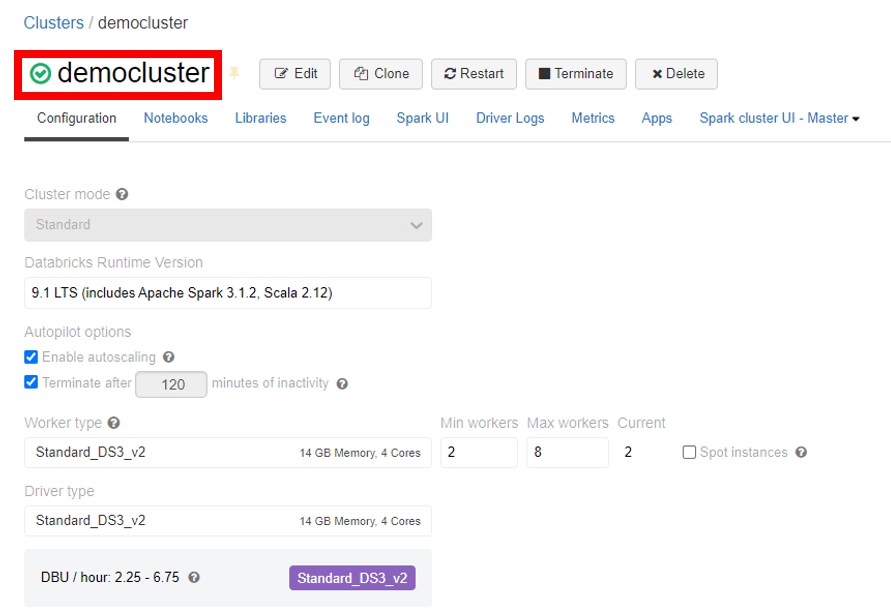
次に Notebook の作成を行います。この Notebook で Python や SQL 等を実行することになります。左のメニューバーから 「Create」 をクリックし、さらに下記図の赤枠で囲まれた 「Notebook」 をクリックします。
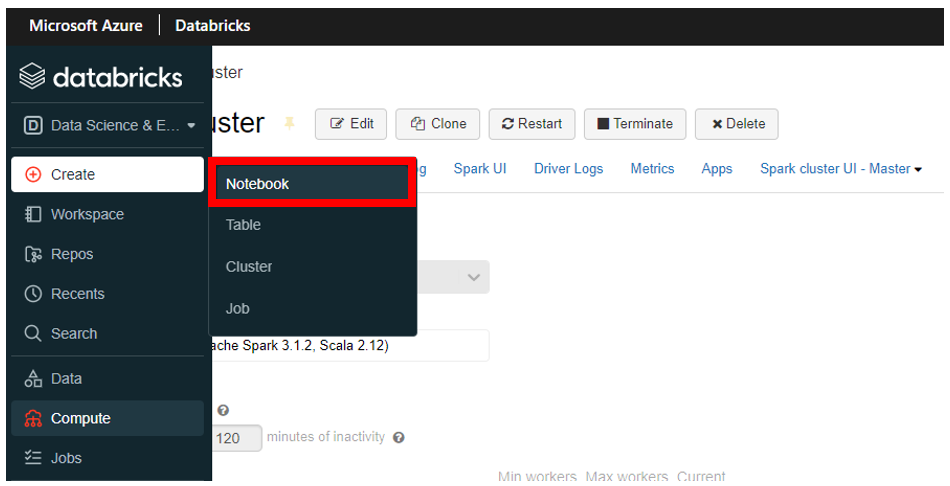
下記を参考に必要事項を設定し 「Create」 をクリックします。
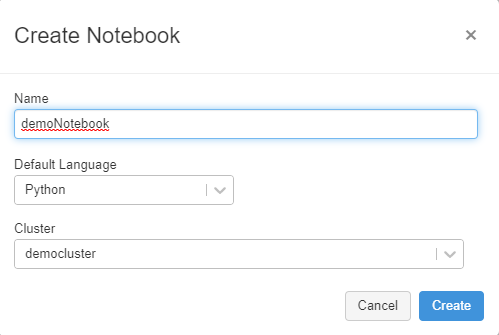
作成が完了すれば、 Azure Databricks のセットアップは以上となります。
続いてテーブルを作成します。本章では UI によるテーブル作成と Azure Blob ストレージに保存されたデータからのテーブル作成をそれぞれ紹介します。なお今回は Python の scikit-learn の datasets モジュールに含まれているBoston House Price を csv 形式で使用しています。このデータは1970年代後半におけるボストンの住宅価格の表形式データセットとなっています。
まず UI によるテーブル作成を紹介します。左のメニューバーから 「Data」 をクリックし、さらに下図の赤枠線の 「Create Table」 をクリックします。
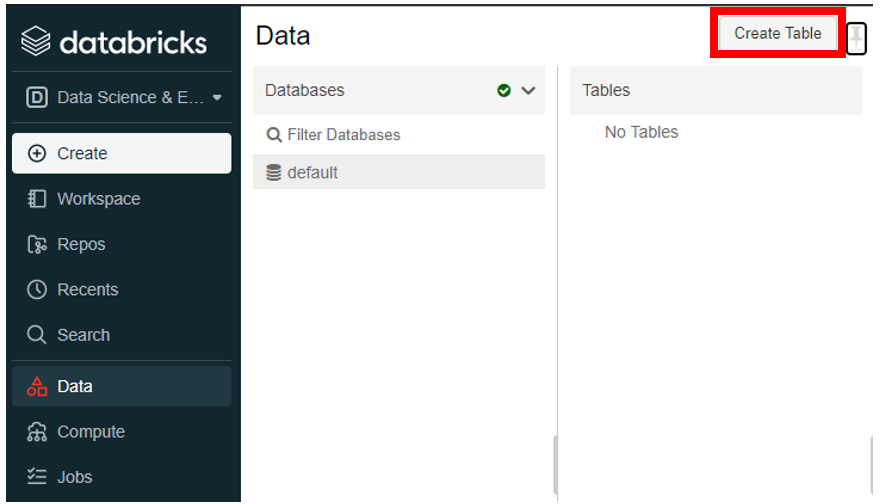
次に 「Upload File」 をクリックし、下記図の赤枠線の 「Drop Files to Upload, or click to browse」 をクリックします。任意のファイルを選択し、 「開く」 をクリックします。
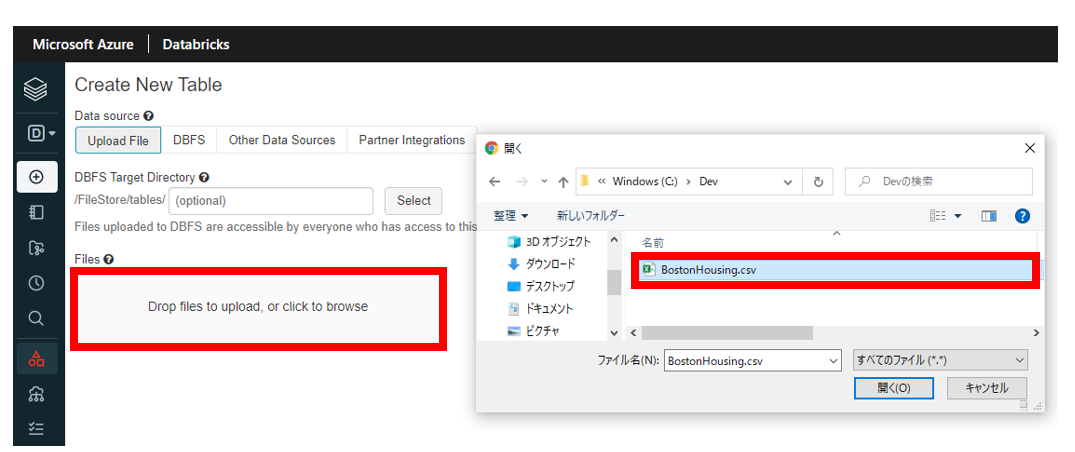
次に下記図の赤枠線で囲まれた 「Create Table with UI」 をクリックします。
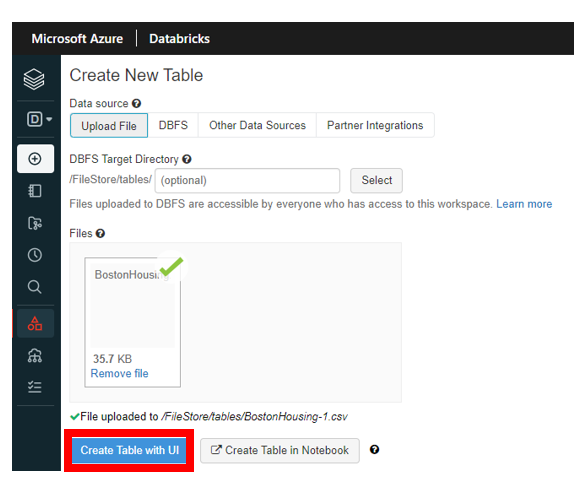
次に 「Cluster」 の項目に上記で作成した Cluster を設定し、 「Preview Table」 をクリックします。すると 「Specify Table Attributes」 が表示されるので、下記のように必要事項を設定し、 「Create Table」 をクリックします。下記項目以外は既定値で設定しています。 Infer schema は自動で列の型を推測してくれますが、間違っていることもあるので下図の 「Table Preview」 で型が適切なものか確認しましょう。また 「Table Preview」 では列名の変更も行えます。
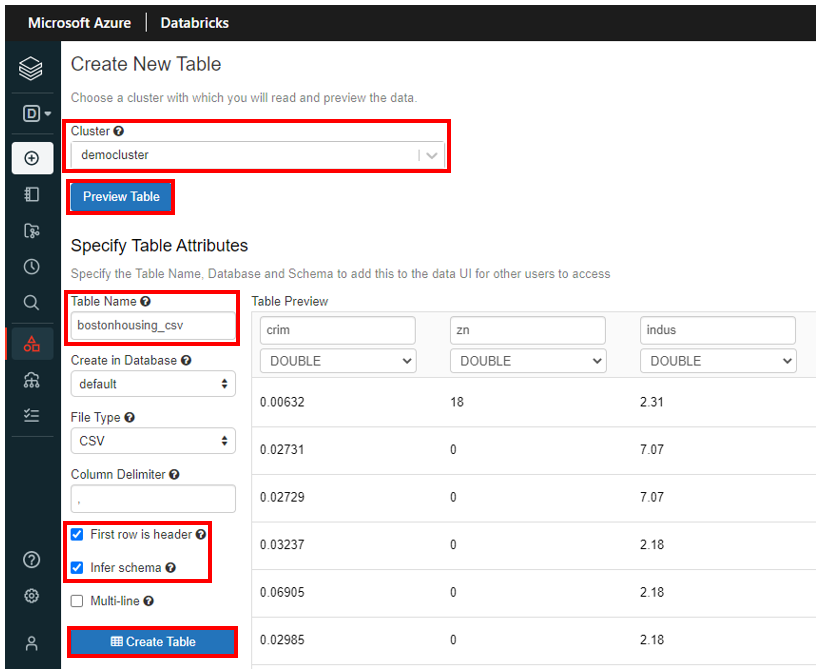
次に Notebook から、テーブルが作成されたことを確認します。
左メニューバーから 「Workspace」 をクリックし、上記で作成した 「demoNotebook」 をクリックします。
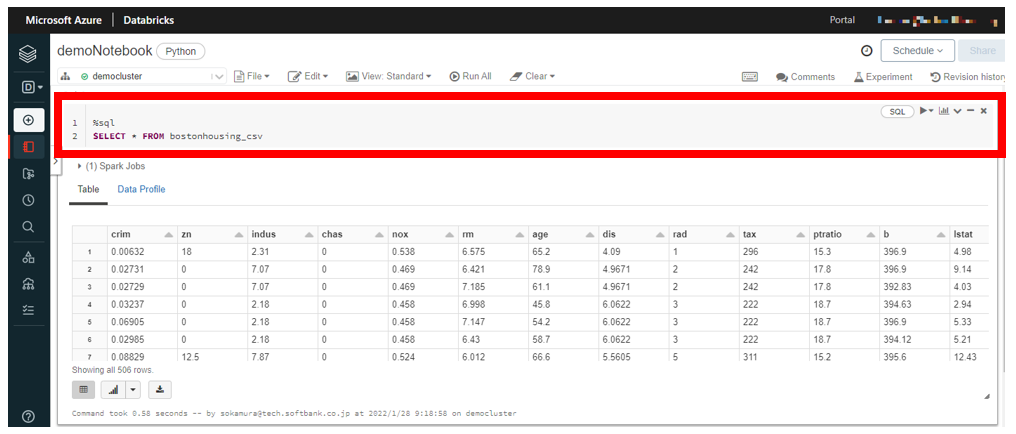
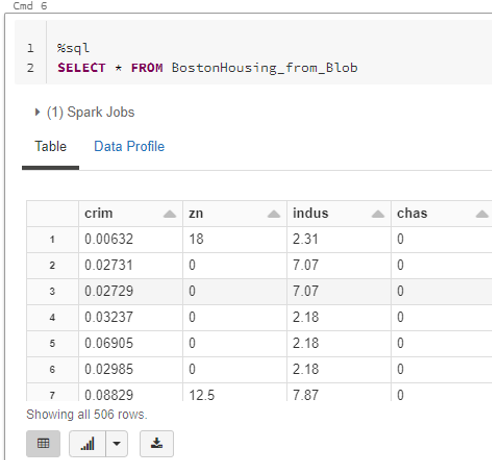
Notebook 画面が表示されるので、下記のように SQL 文を入力し、実行します。実行は Shift キー+ Enter で実行することができます。また実行言語はセルの右上から設定するか、セルの最初に 「%sql」 のように記載することで実行する言語を設定することができます。 「bostonhousing_csv」 の箇所は使用するテーブル名に合わせて変更してください。実行すると下図のように問い合わせしたテーブルが結果として表示され、正常にテーブルが作成されていることを確認できます。
%sql
SELECT * FROM {任意のテーブル名}
次に Azure Blob ストレージに保存されたデータからのテーブル作成を行います。まず Azure Blob ストレージの作成から行います。すでに Azure Blob ストレージが作成済みで Azure Databricks からアクセスできるデータが格納済みの場合は、このセクションはスキップしてください。
上記で Azure Databricks を作成したリソースグループから 「Create」 をクリックし、検索バーに 「Storage account」 と入力し、選択します。
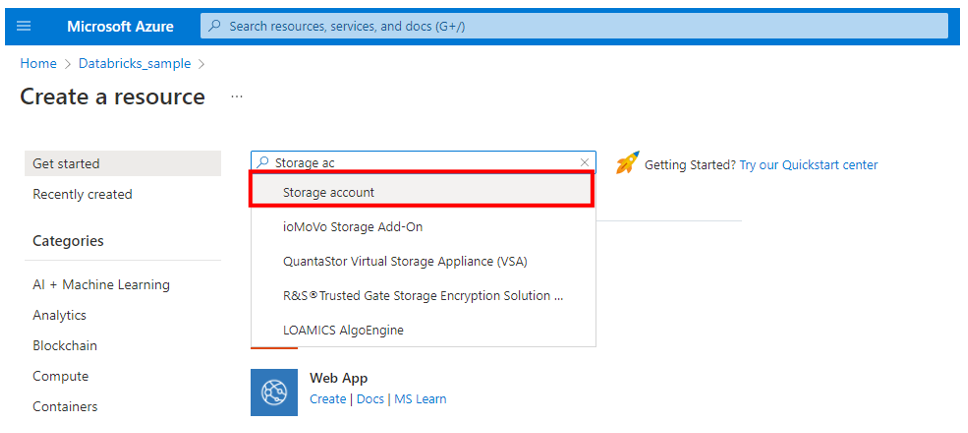
「ストレージアカウント」 が表示されるので、 「作成」 ボタンをクリックします。
以下を参考にストレージアカウント作成時の必要事項を設定し、 「確認および作成」 をクリックします。
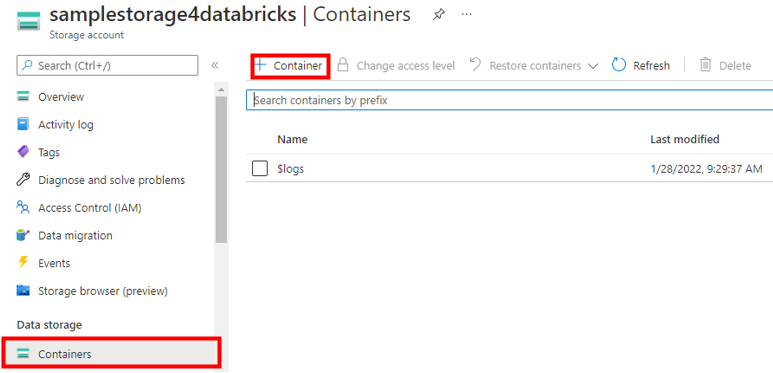
これでストレージアカウントのリソースが構築できました。次にストレージアカウント内にファイルを格納するための Blob コンテナーを作成します。作成したストレージアカウントに移動し、左メニューバーから 「Containers」 をクリックします。次に下記の赤枠線で囲まれた 「+ Container」 をクリックします。右に出てくる 「新しいコンテナー」 に任意の名前を入力して 「作成」 ボタンをクリックします。
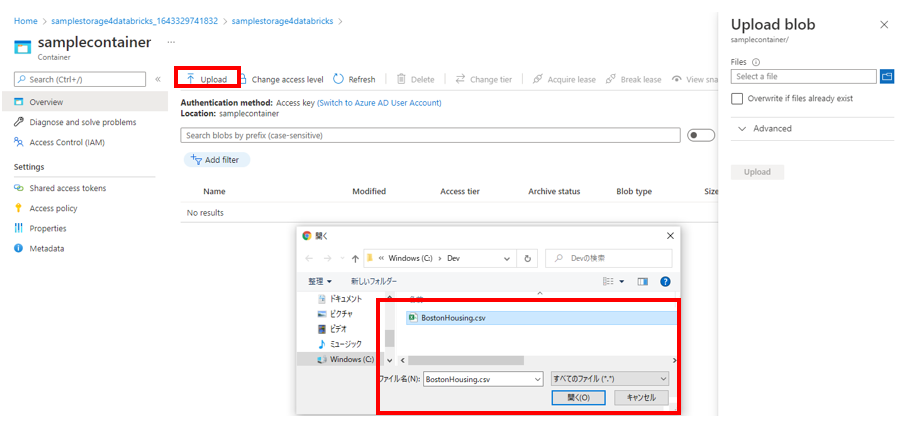
コンテナーが作成されたら、作成したコンテナーに移動し 「Upload」 ボタンをクリックします。右の 「Upload Blob」 の青色ボタンをクリックし、 Azure Databricks に読み込ませるファイルを選択し、 「Upload」 ボタンをクリックします。
アップロードが完了すると下図のように作成したコンテナー内にファイルがあることが確認できます。
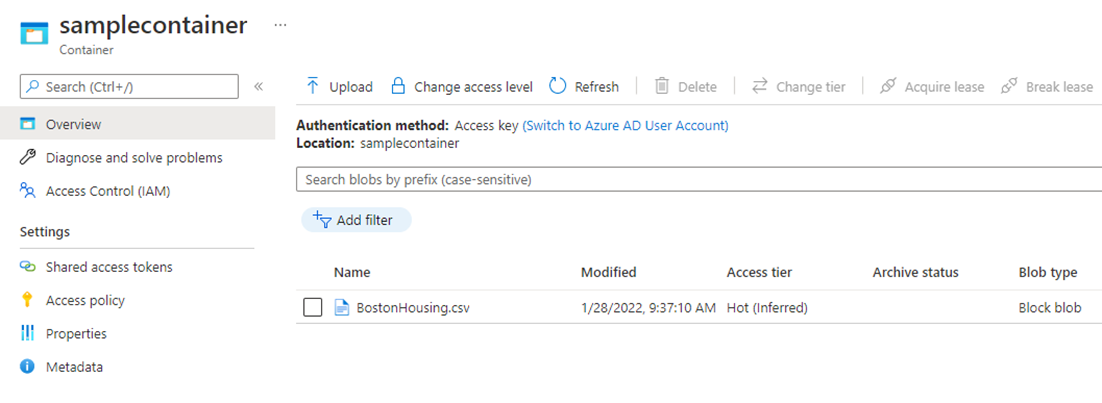
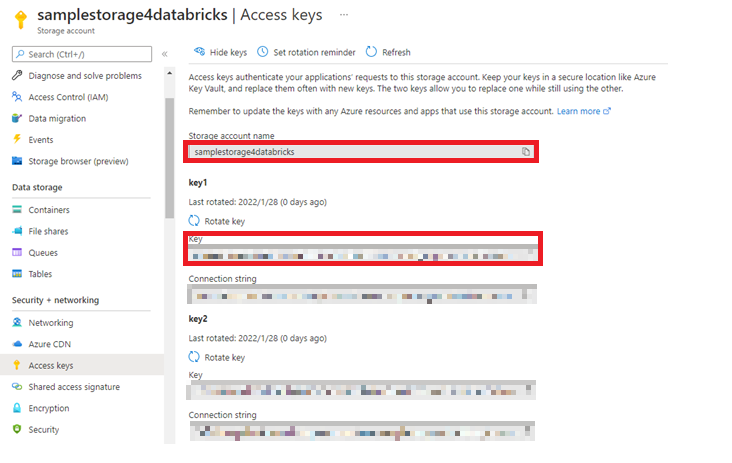
次に Azure Databricks からデータを取得するために必要なストレージアカウントへのアクセスキーを確認します。左メニューバーの 「Access keys」 から 「Storage account name」、 「Key1」 の Key を後ほど使えるように控えておきましょう。
ストレージアカウントの作業はここまでになります。ここからは Azure Databricks で、作成したストレージアカウントとマウントし、テーブルを作成していきます。ここでの「マウント」は Azure Databricks とストレージアカウントを接続し、使える状態にするという意味です。
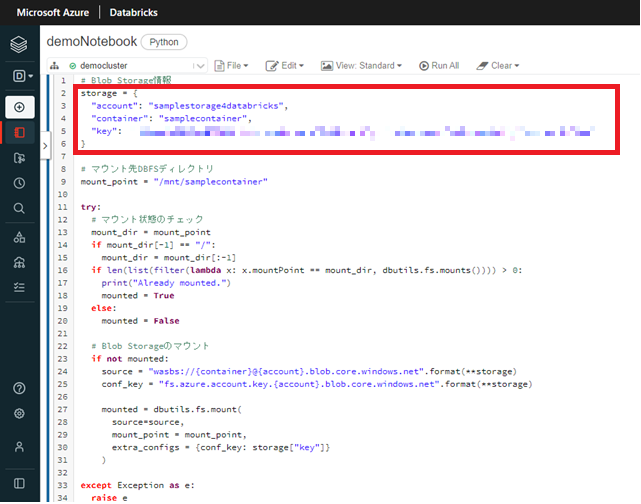
上記で作成した Azure Databricks workspace に移動し、作成した Notebook に移動します。次にセルに下記のコードを入力します。この時ストレージアカウント名、 Blob コンテナー名、アクセスキーは先ほど控えたものを入力し、実行します。なお実行言語は Python の設定です。
storage = {
"account": "{ストレージアカウント名}",
"container": "{Blobコンテナー名}",
"key": "{アクセスキー}"
}
# マウント先DBFSディレクトリ
mount_point = "/mnt/{マウント先ディレクトリ}"
try:
# マウント状態のチェック
mount_dir = mount_point
if mount_dir[-1] == "/":
mount_dir = mount_dir[:-1]
if len(list(filter(lambda x: x.mountPoint == mount_dir, dbutils.fs.mounts()))) > 0:
print("Already mounted.")
mounted = True
else:
mounted = False
# Blob Storageのマウント
if not mounted:
source = "wasbs://{container}@{account}.blob.core.windows.net".format(**storage)
conf_key = "fs.azure.account.key.{account}.blob.core.windows.net".format(**storage)
mounted = dbutils.fs.mount(
source=source,
mount_point = mount_point,
extra_configs = {conf_key: storage["key"]}
)
except Exception as e:
raise e
"mounted: {}".format(mounted)
エラーなく、実行されたら作成したストレージアカウントをマウントできているか確認します。下図のようにセルに 「mounted」 と入力して実行し、 True と表示されればマウントは成功しています。

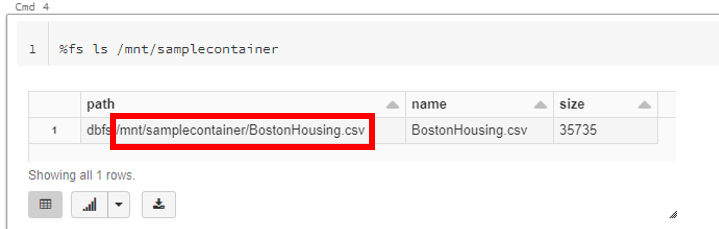
また下記のようにコマンドを入力することでファイルが格納されていることも確認できます。ここで結果として出力されるファイルの path は後ほど使うので控えておきましょう。
%fs ls (マウント先DBFSディレクトリ)
次にマウントされたコンテナー内のファイルからテーブルを作成します。下記のように入力し実行します。成功すれば、テーブルが作成されます。
dataFrame = “{上記で保存したファイルの path }”
spark.read.format(“csv”).option(“header”,“true”)
.option(“inferSchema”,“true”).load(dataFrame)
.write.saveAsTable(“{任意のテーブル名}”)
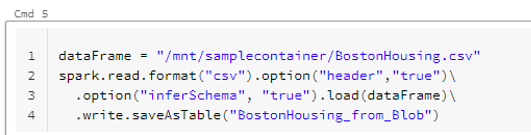
次に UI によるテーブル作成の時と同様に SQL を実行し、テーブルが作成されているか確認します。確認ができれば Azure Blob ストレージに保存されたデータからのテーブルの作成は完了です。
検証が終われば、しっかりリソースを削除します。 Azure Databricks は並列分散処理が手軽に利用できることが強みではありますが、VMを多く使う分、他リソースに比べて使用料金が高いです。
本記事では Azure Databricks について説明し、実際にセットアップと二種類のテーブル作成の手順を説明しました。続編として Azure Databricks 上でのデータエンジニアリング、モデル作成、データ分析についても記事を執筆予定ですので、ぜひご参照ください。
Microsoft はクラウドサービスとして他にも様々な機能を提供しており、やりたいことを実現するための手段として活用できることは多いと思います。何かに取り組む時には、使えるサービスや技術がないか一度調べてみることをお勧めします。当社でも多数の紹介記事を公開しておりますのでぜひ参考にしてください。
また当社では AI や機械学習を活用するための支援も行っております。持っているデータを活用したい、AI を使ってみたいけど何をすればよいかわからない、やりたいことのイメージはあるけれどどのようなデータを取得すればよいか判断できないなど、データ活用に関することであればまず一度ご相談ください。一緒に何をするべきか検討するところからサポート致します。データは種類も様々で解決したい課題も様々ですが、イメージの一助として AI が活用できる可能性のあるケースを以下に挙げてみます。
AI が活用できる可能性のあるケースの例
上記は一例となりますがデータ活用に関して何かしらの課題を感じておりましたら、当社までお気軽にお問い合わせください。
関連ページ |




