みなさまこんにちは。クラウドアーキテクトの卵です。
本ブログも、リモートワーク環境で書いています。あれからまたちょっと模様替えしました。
スマホ置き場やヘッドセット置き場を設けたり、配線周りをもう少しスッキリさせたり、アロマコーナーを作ってみたり、お気に入りのフィギュアを飾ってみたり…。より機能的、かつ、より気分が上がる環境が整ってきました。
ちなみに、現在においても、一番の課題 (部屋がスッキリした状態を維持することができるか) は顕在化しておりません (強調) 。
今回は、前回のブログの続きとなります。
今回は実践編として「データガバナンス」の実現方法をまとめました。
前回のブログでは、データガバナンスとは、平たく言ってしまうと「データの運用ルール」のことであり、データ利活用にはデータガバナンスが必要不可欠、という内容をまとめました。
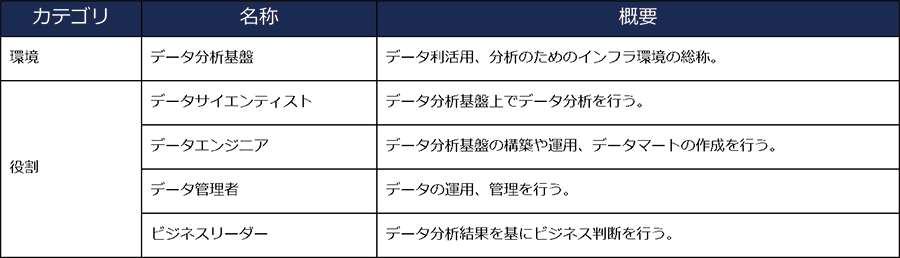
その中で、データ利活用に必要なもの・役割について、以下のように記載しています。
データの利活用に必要なもの・役割は、最低でもこれだけ必要と言われています。
(実際には、もう少し細分化されることもあります。また、会社によって名称が異なることもあります。特に「役割」の部分。)
本ブログでは、「Azure 上のデータ分析基盤環境において、実際にどのようにすればデータガバナンスが保たれるか」に焦点を当てています。そのため、プラットフォーム側で実現できるデータガバナンスの方法について記載します。
前回のブログの『3. データガバナンスの必要性』の部分で、以下のように記載しました。
お客様からの問い合わせや、データ系のセミナー / ウェビナーでよく紹介される事例 (お困りごと) は、「データの内容」と「データのセキュリティ」の大きく 2 つに分けられることが多いように感じます。
本ブログの「1. はじめに」に記載した内容が含まれています。
上記の問題を解決するには「データの品質を保つルール」が必要となります。
2 番目と 3 番目の内容は、一見背反しているように見えますね。
(データの管理者は辛いところだと思います。。。)
「誰が、どのデータを取り扱って良いか (もしくは、閲覧不可なのか) 」という権限管理が、データにおいても必要と言えるでしょう。
上記の問題を解決するには、「データのセキュリティを保つルール」が必要となります。
ここでは「データの品質を保つルール」について、Azure だとどのような施策が取れるかを考えてみます。
(「データのセキュリティを保つルール」については、次章に記載します。)
データの品質を保つには、誰かが適切に管理しておく必要があります。
しかし、ただ管理しているだけだと、データ利活用を促進するという最終目標に達するには少し弱いです。「このようなデータがここにあり、使える状態である」ということを、データサイエンティストをはじめとするデータ利用者が知らないと、データ利活用がままならなくなります。
(データの存在を知らない、ということは「あるある」です。「そのデータ、ウチの部署独自で持ってますよ」「えっ!?」という話も往々にして聞きます。)
上記より、データガバナンスを保つには、データの適切、かつ、利用可能な状態の管理が必要であると言えそうです。
データの適切な管理、データの利用可能な状態の管理について、Azure で実現可能な施策を調査しました。
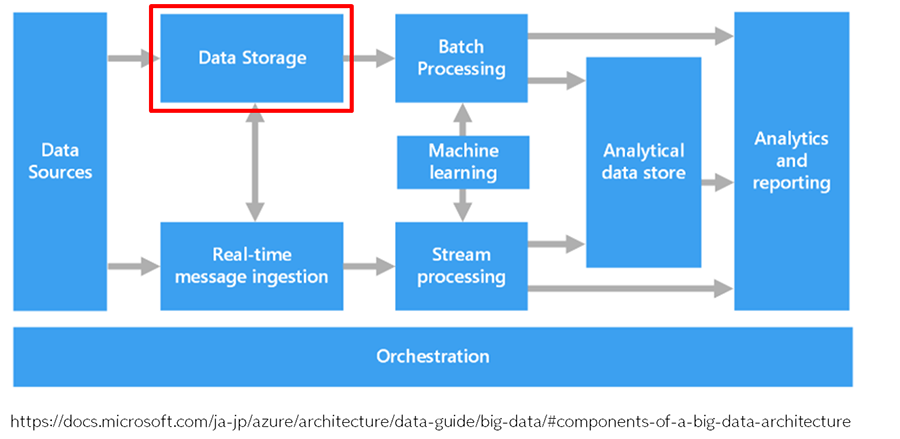
【参考:ビッグ データ アーキテクチャのコンポーネント】
https://docs.microsoft.com/ja-jp/azure/architecture/data-guide/big-data/#components-of-a-big-data-architecture
このデータレイク (上図の Data Storage ) の配置ルールを決めます。多少語弊があるかもしれませんが、とても平たく言うとフォルダ構成を決める感じです。
Azure の場合、Azure Data Lake Storage Gen2 を利用することをお勧めします。
普通の Blob Storage でも良いのですが、Azure Data Lake Storage Gen2 はビッグデータ分析用に特化した機能を有しています。中でも特徴的なのが、階層型名前空間が追加されている点です。
階層型名前空間の機能を使うと、コンピューター上のファイル システムを編成するのと同じ方法で、アカウント内のオブジェクト / ファイルのコレクションを、ディレクトリおよびネストされたサブディレクトリの階層に編成できるようになります。必要なデータの場所をファイルシステムと同じように指定できるため、データ解析のパフォーマンスも早いです。
(「多少語弊があるかもしれませんが、とても平たく言うとフォルダ構成を決める感じです」は、階層型名前空間を意識して書きました。)
【参考:Azure Data Lake Storage Gen2 の概要】
https://docs.microsoft.com/ja-jp/azure/storage/blobs/data-lake-storage-introduction
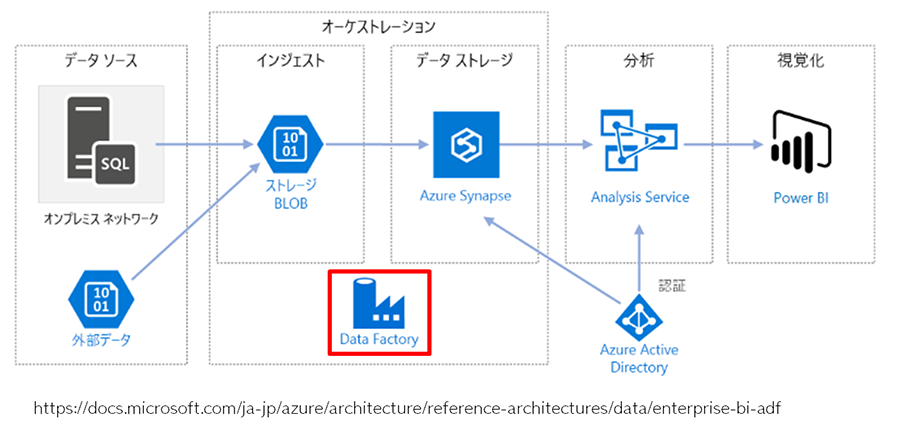
【参考:Data Factory の概要】
https://docs.microsoft.com/ja-jp/azure/data-factory/introduction
【参考:Azure Synapse Analytics と Azure Data Factory を使用して自動化されたエンタープライズ BI】
https://docs.microsoft.com/ja-jp/azure/architecture/reference-architectures/data/enterprise-bi-adf
「2. データ分析基盤としてのデータガバナンス」に関連して、データガバナンスについて Microsoft の Docs を確認したところ、『ベスト プラクティス : Azure Databricks でのデータ ガバナンス』という、そのものずばりの記事が出てきました。
【参考:ベスト プラクティス : Azure Databricks でのデータ ガバナンス】
https://docs.microsoft.com/ja-jp/azure/databricks/security/data-governance
そこには、「データガバナンスが重要な理由」として、以下の内容が記載されています。
データガバナンスは、組織内のデータ資産を安全に管理するために実装されたポリシーとプラクティスをカプセル化した包括的な用語です。データガバナンスを成功させるための重要な原則の1つとして、データセキュリティは大規模な組織にとって最も重要であると考えられます。データセキュリティにとって重要なのは、データチームが組織全体でユーザーデータアクセスパターンをより優れた可視性と監査機能を持つことができるようにすることです。効果的なデータガバナンスソリューションを実装することで、企業はデータを不正なアクセスから保護し、規制要件に準拠するための規則を確実に適用することができます。
「データガバナンスを成功させるための重要な原則の1つとして、データセキュリティは大規模な組織にとって最も重要であると考えられます。」という記載から、データガバナンスとセキュリティはかなり密接であるように見受けられます。
では、Azure Databricks のセキュリティについてどのように記載されているのかを確認したところ、とても興味深いことが分かりました。
【参考:セキュリティとプライバシー】
https://docs.microsoft.com/ja-jp/azure/databricks/security/
Azure Databricks の「セキュリティとプライバシー」の 1 項目として、「Azure Databricks でのデータ ガバナンス」が挙げられています。
つまり、Azure、少なくとも Azure Databricks では、データガバナンスはセキュリティの中の 1 項目と捉えられている、ということになります。
※それぞれの URL をよく見ると、「セキュリティとプライバシー」 ( /security/ ) の下に「ベスト プラクティス : Azure Databricks でのデータ ガバナンス」 ( /security/data-governance ) がある構成になっていますね。
データ分析基盤としてのセキュリティで必要なことは、プラットフォームのセキュリティで必要なことと変わりはありません。主に以下の 3 点が重要になります。
『ベスト プラクティス : Azure Databricks でのデータ ガバナンス』でもいくつかの方法が記載されていますが、いずれもアクセス制御 (主に認証) かアクセスの監査に集約されています。

リソースによってデフォルトでセキュリティ施策が有効になっているものもある点が安心ですよね。

特にデータ自体に暗号化を実施する場合は、暗号化の対象となるデータと暗号化する理由を明確にしておくことが、データのセキュリティを守るためのルールとして必要になります。
※ちょっと余談ですが、セキュリティアセスメントを実施している際、以下のようなやり取りがしばしば見受けられます。
~ 開発中のシステムに対するセキュリティアセスメント時の一例 ~
SBT:「暗号化の対象となるデータやカラムを教えていただけますでしょうか。」
お客様:『機密情報と個人情報に関わるものを暗号化する予定です。』
SBT:「“機密情報”と“個人情報”は、具体的にどんな情報が該当するのか教えていただけますでしょうか。」
お客様:『えーっと…少々お待ちください…。』
※弊社のセキュリティアセスメントについてはこちらを参照ください (宣伝) 。

Azure での通信制御は、やはり NSG がキモになります。

認証・認可については、会社として一元管理をする方針を取った方が良いです。Azure だと Azure Active Directory という強力な認証基盤があるため、一元管理もしやすいのではないでしょうか。
今回は「Azure 上のデータ分析基盤環境において、実際にどのようにすればデータガバナンスが保たれるか」という観点で、Azure プラットフォーム側で実現可能なデータガバナンスの方法を調査してみました。意外と? (と言っては失礼ですが…) プラットフォーム側で実現できることが多いのかな?というのが、調査をしてみての正直な感想です。
また、Microsoft の Docs を確認してみても、データガバナンスとセキュリティは場合によっては混在して語られているように見受けられるため、両者は切っても切れない関係にあるように思えました。
(本ブログも、記載内容がセキュリティ寄りになっていますね)
以下、前回のブログの再掲になりますが…。
(大事なことなので 2 回言います)
データの品質やセキュリティを担保し、あらゆるデータを管理することは、データガバナンスが効いている状態に直結すると言えます。
そのためにも、システム的なルールだけではなく、組織・人を含めた全体的な運用ルールが必要となります。
(組織・人の部分が一番難しいことは承知していますが。。。)
データ利活用を促進するためにも、まずはできるところから始めてみてはいかがでしょうか。部分的にでも「データの運用ルール」を制定しておくと、後で全社統合する際に整理できている状態から始まるため、きっと役立つはずです。
関連ページ |




