こんにちは。データサイエンスチームの白石です。
深層学習モデルを構築するときに、当社では主に Azure Machine Learning Services(以下、AMLS)を使っています。
この記事では、PyTorch で実装したモデルを AMLS 上で使う方法について説明します。特に、PyTorch-Lightning(以下、Lightning)という高機能な PyTorch のラッパーライブラリを使うことで、効果的な訓練を実現する方法を紹介します。
まず、Lightning と AMLS がそれぞれどのようなものなのかを簡単に紹介します。次にこれらを使って具体的にモデルを訓練する手順を紹介します。最後に、Lightning や AMLS を使う上で生じやすい様々なトラブルについて、解決のための手引を紹介します。
「機械学習導入支援サービス」に関する資料請求・お問い合わせはこちら
Lightning は、PyTorch のモデルをラッピングし、効率的な Experiment を実現するためのラッパーライブラリです。このようなラッパーライブラリは、しばしば TensorFlow に対する Keras の立ち位置を表す "Keras-Like" なライブラリと呼ばれます。
PyTorch における Keras-like と呼べそうなライブラリは、以下のように複数乱立している状況です。
これらのライブラリの中で私が Lightning を気に入っている理由は、学習コストの低さと柔軟性にあります。公式リポジトリの冒頭には、以下のように Lightning の立ち位置が明言されています。以下、意訳です。
Lightning は、研究のためのコードをエンジニアリングから切り離すために PyTorch コードを整理する方法です。フレームワークというよりも、PyTorch のスタイルガイドのようなものです。
Lightning では、コードを3つの異なるカテゴリに整理します。
Lightning を使うためには、PyTorch で実装したネットワークの定義や損失関数、訓練・評価処理などを LightningModule というひとつの Python クラスの各メソッドとして実装する必要があります。これらのコードは3つのカテゴリのうちの1番目の研究コードに該当します。この作業は、いままで何十行も必要だったコードがわずか数行に収めらるというニュアンスの Keras-like という単語から受ける印象とはだいぶ異なっています。結局 PyTorch の基本的な処理は記述する必要があるので、実装にかかる時間は PyTorch を生で実装するのとほとんど変わりません。これが、「(Lightning は)PyTorch のスタイルガイドのようなものです」ということの意味です。
Lightning が素晴らしいのは、研究コードのスタイルガイドを守って LightningModule を実装しさえすれば、様々な機能を低コストで導入できる、という点にあります。
それを担っているのが2、3番目のカテゴリのエンジニアリングコードと各種 Callback です。LightningModule に適切に各処理を実装すれば、様々な機能を内包している Trainer と Callback を自由に組み合わせてモデルを訓練できるのです。たとえば、Trainer の基本的な機能の中に、簡単に PyTorch モデルを分散環境で訓練可能にできる、というものがあります。同一の LightningModule を用いて、使用する分散環境や GPU 数を、Trainer に与える引数で指定して実行することができます。PyTorch の標準である NCCL 以外にも、Horovod を指定したり、(Azure ではなく GoogleCloudPlatform や Colaboratory では)TPU も指定することもできます。もちろん、単一ノードの GPU や CPU での訓練も可能です。生の PyTorch 実装で分散環境での訓練を行ったことがある方にとっては、DistributedDataParallel まわりの処理を自分で書く必要がなくなる、といえばわかりやすいでしょうか。
また、モデルの訓練時に使用できる様々なテクニックが Trainer には実装されています。例えば、限られた GPU 数で大規模なバッチサイズの訓練をしたいというときに、擬似的に巨大なバッチでの訓練を行うという accumlate gradient や、モデルのパラメータの更新に使う勾配の大きさをある範囲内に収める gradient clipping、また、バッチサイズを GPU のメモリサイズに自動的に適応させる Auto scaling of batch size などがオプションとして指定できます。
さらに、各種の Callback が用意されています。ロギングの Callback として、デフォルトでは TensorBoard が使用でき、LightningModule に定義した訓練処理や評価処理で計算した損失などが自動で TensorBoard のログとして記録されます。TensorBoard の他には、CometML や MLflow といったその他のサービスやライブラリへの対応が可能です。その他の Callback としては、たとえば、早期終了(Eary Stopping)などの機能が用意されています。
以上のように、Lightning は生の PyTorch の処理を LightningModule に配置するだけで高機能な Trainer と Callback を利用できるようになるライブラリです。研究コードは通常の PyTorch で書けるため、学習コストの低さや柔軟性をもたらしています。先程挙げたいくつかの Keras-like なライブラリの中には、Lightning に比べるとより抽象度の高いラッピングがなされているために、そのライブラリ固有の学習コストが高くなってしまったり、PyTorch そのものが持っている柔軟性を疎外してしまうために複雑なモデルの訓練が困難になったりすることもあります。もちろん、Lightning の抽象化の粒度も完璧ではありませんし、まだまだ発展途上の部分もありますが、筆者は一番気に入っています。
以上、PyTorch Lightning の紹介でした。興味のある方は、PyTorch から Lightning に移行するためのガイドが、メインコントリビュータである William Falcon 氏によって書かれているので、一読をおすすめします。
Azure Machine Learning Services(AMLS)についても、簡単にですが紹介しておきます。
AMLS はデータセット管理、訓練、デプロイを一気通貫で行えるように整備されたマネージドサービスです。ドラッグ&ドロップによって簡単に機械学習モデルを構築できる Visual Designer や、自動的に最適な機械学習モデルを作ってくれる AutoML、Jupyter Notebook を手軽に構築できる Notebook VM、手軽に訓練済みのモデルを公開できる WebAPI 機能なども用意されています。
今回は、独自の深層学習モデルを訓練するために最も汎用的な機能である Experiment を使用します。Experiment では、モデルの構築のために記述したスクリプトや依存ファイルを、SDK を通じて AMLS にジョブとして提出することで、Azure 上の計算資源を使ってモデルを訓練することができます。ジョブを実行する環境である ComputingTarget は自由に選ぶことができ、ちょっとした訓練であれば1つ GPU を積んだ1台の仮想マシンを指定することができますし、より大規模な環境として8GPU のノードを10台使うといった指定もできます。もちろん、リッチな ComputingTarget はそれなりにお値段がかかるので注意が必要です。以下のような設定の ComputingTarget を作ることでお値段を抑えて活用することができます。
さて、ここからが本題です。AMLS 上で Lightning の訓練を行ってみましょう。手順としては以下のとおりです。
以降は、私が書いたソースコードや jupyter notebook も併せてご確認ください。
まずは訓練に使用するスクリプトを作成しましょう。とはいえ、あまり凝ったものを作るのではなく、Lightning の公式リポジトリのサンプルとして使われている、MNIST を対象にした GAN の訓練を使いましょう。
AMLS への対応のために、Trainer に対していくつかの変更を行います。
今回は、Lightning の0.7.4以降でサポートされている Horovod を分散訓練環境として使用することにしましょう。Horovod を使用するときの注意すべき点として、`gpus` 引数があります。通常、この引数には全ノードにまたがって存在する GPU の数を指定しますが、Horovod のときのみ「1」を指定する必要があります。これによって、Horovod のプロセス数分の GPU を自動的に使用できるようになっています。
次にロギング用の Callback として、カスタマイズした TensorBoardLogger を指定します。Lightning ではデフォルトで TensorBoardLogger が使用されますが、ログの出力先がデフォルトでは lightning_logs というディレクトリになってしまいます。AMLS がサポートしている TensorBoard のログ出力先は、logs というディレクトリで固定なので、そのように指定した TensorBoardLogger を指定します。
その他の変更点として、あまり長時間訓練を行っても仕方ないので、`max_epoch` 引数を100に指定しています。
以上の変更を反映すると、main 関数の中は以下のように修正されます。
def main(args: Namespace) -> None:
# ------------------------
# 1 INIT LIGHTNING MODEL
# ------------------------
model = GAN(**vars(args))
# ------------------------
# 2 INIT TRAINER
# ------------------------
# If use distubuted training PyTorch recommends to use DistributedDataParallel.
# See: https://pytorch.org/docs/stable/nn.html#torch.nn.DataParallel
tb_logger = TensorBoardLogger(save_dir="logs", name="mnist-gan")
trainer = Trainer(
distributed_backend="horovod",
gpus=1,
logger=tb_logger,
max_epochs=10,
prepare_data_per_node=True,
)
# ------------------------
# 3 START TRAINING
# ------------------------
trainer.fit(model)
ここからは、ローカル環境や Notebook VM、Azure Notebook などで Jupyter Notebook を起動し、以下のドキュメントを参考に AMLS 環境を整えてきます。
https://docs.microsoft.com/ja-jp/azure/machine-learning/tutorial-1st-experiment-sdk-setup
https://docs.microsoft.com/ja-jp/azure/machine-learning/tutorial-train-models-with-aml
pip install -u azml-sdk[tensorboard]
(json)
{
"subscription_id": "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX",
"resource_group": "XXXXXXXXXX",
"workspace_name": "XXXXXXXXXXXXXXXXXXX"
}
ws = Workspace.from_config()
exp = Experiment(workspace=ws, name=EXPERIMENT_NAME)
if COMPUTE_NAME in ws.compute_targets: # ComputingTargetがすでに存在していたらそれを読み込む
compute_target = ws.compute_targets[COMPUTE_NAME]
if compute_target and type(compute_target) is AmlCompute:
print('found compute target. just use it. ' + COMPUTE_NAME)
else: # ComputingTargetが存在していなければ新規作成する
print('creating a new compute target...')
provisioning_config = AmlCompute.provisioning_configuration(
vm_size=VM_SIZE,
vm_priority="lowpriority",
min_nodes=MIN_NODE, # 0
max_nodes=MAX_NODE
)
# create the cluster
compute_target = ComputeTarget.create(
ws, COMPUTE_NAME, provisioning_config)
# can poll for a minimum number of nodes and for a specific timeout.
# if no min node count is provided it will use the scale settings for the cluster
compute_target.wait_for_completion(
show_output=True, min_node_count=None, timeout_in_minutes=20)
# For a more detailed view of current AmlCompute status, use get_status()
print(compute_target.get_status().serialize())
最後に、Estimator オブジェクトを作成します。Estimator オブジェクトは、どのような環境で、どのようなスクリプトを実行するのかを定義するオブジェクトです。今回は PyTorch に特化した Estimator クラスを使用し、以下のような項目を指定することで作成します。
ソースコードは以下のようになります。
mpi_config = MpiConfiguration()
mpi_config.process_count_per_node = 2
est = PyTorch(
source_directory=SCRIPT_DIR,
entry_script=ENTRY_SCRIPT,
script_params=SCRIPT_PARAMS,
compute_target=compute_target,
use_gpu=True,
conda_packages=["pip"],
pip_packages=["pytorch-lightning"],
node_count=NUM_NODE,
distributed_training=mpi_config,
framework_version="1.5",
shm_size="8G",
)
run = exp.submit(config=est)
Run オブジェクトは、ログの保管場所なども管理しているので、この情報を元に、TensorBoard でログを確認することができます。
from azureml.tensorboard import Tensorboard
tb = Tensorboard([run], port=8008)
tb.start()
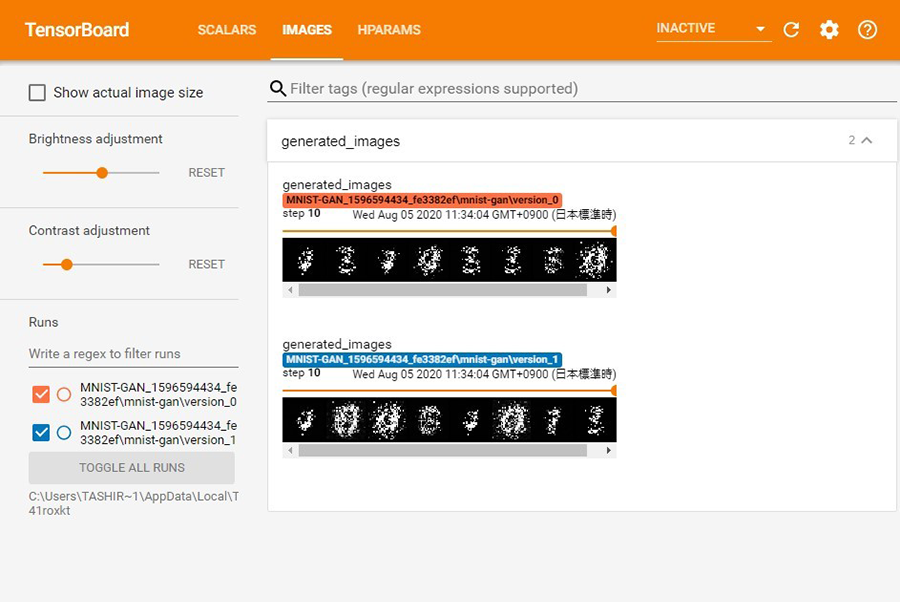
TensorBoard は、以下のように停止することができます。
tb.stop()
Lightning を AMSL で使用するための方法を紹介してきました。とても簡単に分散環境でのモデルの構築ができるのですが、いくつか落とし穴があります。ここではそれらの解決するための手引を共有します。
まずは AMLS についてです。AMLS はまず環境構築に落とし穴があります。一度やり方を確立するまでは、Docker イメージの構築や依存ライブラリのインストールなどに苦戦するかもしれません。
また、スクリプトレベルで解決しなければならない問題として、分散環境やマルチプロセス固有の問題が挙げられます。例えば、複数のプロセスから同一のファイルを触ってしまう可能性がある実装になっている場合に、この問題が生じやすいです。
いずれの場合も、まずは AMLS のログを確認する、ということを心がけましょう。ログは AMLS のポータルから確認することができます。各ジョブの「出力とログ」タブの azureml-logs ディレクトリの下に以下のような形で表示されます。
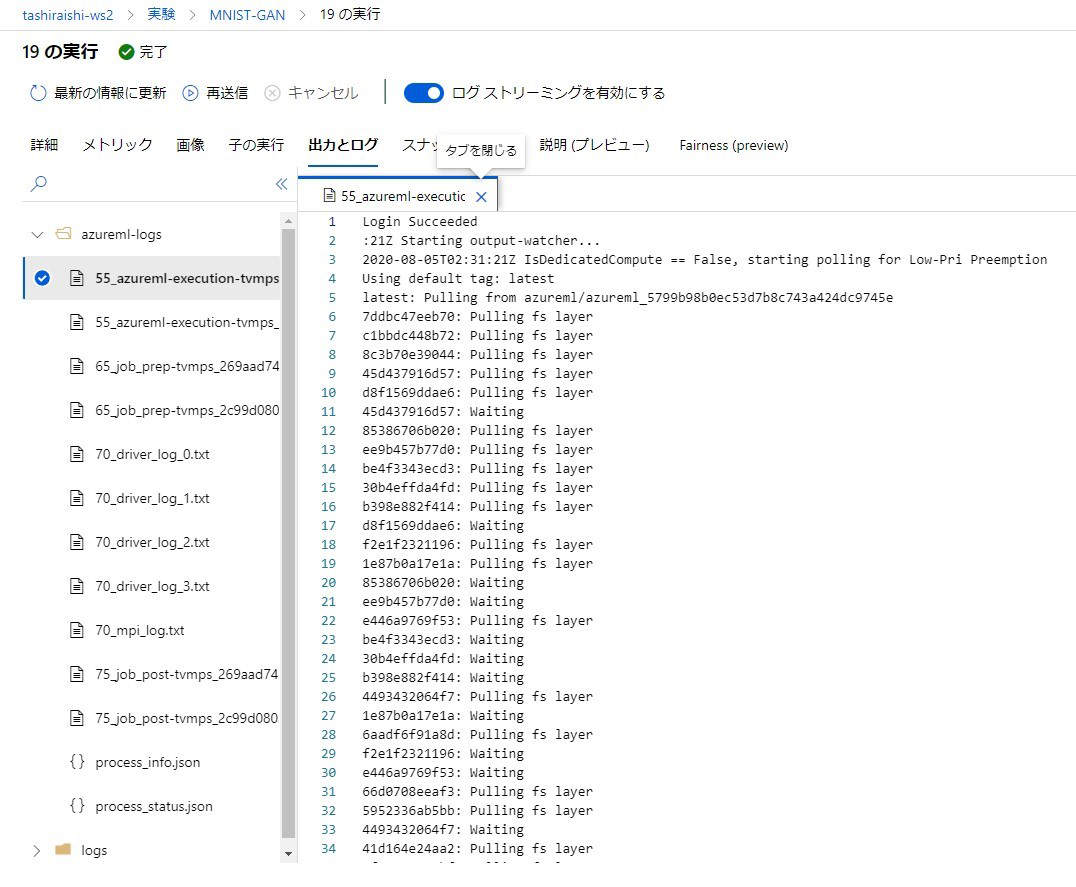
基本的には、環境構築に関するログは55から始まるファイル、実際にスクリプトが実行されたあとの各プロセスのログは70から始まるファイルに吐き出されます。この区分は問題の切り分けに使えますが、実行時エラーの原因が環境構築にある、というタイプの問題に注意しましょう。例えば、Estimator オブジェクトを作成するときの `shm_size` が小さすぎると、環境構築はうまく行っても実行時にエラーが生じることがあります。ログに表示されている内容をよく読んで、内部でどのような問題が生じているのかを把握した上で各種設定を最適化する必要があります。
続けて、Lightning で生じる問題の解決方法を確認しましょう。
まずは、Lightning の公式ドキュメントにあるデバッグのための機能をよく読みましょう。これらの機能は、訓練プロセスの問題を明らかにすることがあります。
特に、分散環境での訓練を行う前に、そのそも単一のシングル GPU や CPU 環境下で期待どおりの訓練が行えるのかを確かめましょう。`fast_dev_run` や `overfit_batches` といった引数は、限られたデータで期待通りの訓練が進むかを事前に検証できる機能です。
次に、LightningModule についてのドキュメントをよく読み、各メソッドの実行サイクルや分散環境のどのランクで実行されるのかを把握しましょう。これを理解せずに LightningModule を記述すると、同一のファイルを複数のプロセスで同時に触ってしまい、訓練に使用するデータが壊れてしまうといった問題が生じることがあります。
ドキュメントを読んでもよくわからない、ということであれば、公式リポジトリの issue を検索してみましょう。Lightning は日々改善されており、最新版を再インストールするだけで問題が解決する可能性もあります。もちろん、デグレードなどが生じることもあるので、安定した動作が確認できたら、AMLS の Estimator オブジェクト作成に使用する引数でバージョンを指定することも必要です。
以上、AMLS 上で Lightning を使ってみるための手順について説明しました。
最後に少し大変そうな話をしましたが、大前提として、Lightning と AMLS の組み合わせは PyTorch モデル構築の非常に強力な手段となります。
深層学習のモデル構築は気にかけなければならないことが盛り沢山ですが、少しでも考え事を低減させるために、Lightning のように便利なラッパーライブラリや AMLS のようなマネージドサービスを活用することをおすすめします。
関連ページ |




