こんにちは。データサイエンスチームの大山 です。
今年は、Azure OpenAI の登場により、Azure の AI 関連サービスが大きく拡充される年になりました。それに伴い、これまで Azure Cognitive Services として提供されていた各 AI 関連サービスについても、Azure AI サービス の枠内で提供される形に再編されています。しかしながら、従来の Cognitive Services で提供されていた機能に大きな修正が入った訳ではなく、価格や使用方法についても、基本的に大きな変更はしていないとのことです。
この Azure AI サービスでは、様々なデータやタスクの領域に関して、Microsoft が事前に構築した AI や 機械学習モデルを使ったサービスが提供されています。その中でも今回は、時系列データの異常の検出 (異常検知) を目的として提供されている、Anomaly Detector について、ある程度その技術的な内容にも踏み込みつつ、多少詳しく解説したいと考えています。
本記事の前半では、Anomaly Detector が提供する各機能の特色や、どの様な対象、そして分野で活用できるのかについて、Microsoft が公開している技術的な情報も踏まえた上で、ある程度詳しく説明していきます。
また、記事の後半では、Anomaly Detector の一変量時系列データの異常検出機能に関して、Microsoft が公開している論文の内容も踏まえながら、内部で使用している異常検知手法の技術的な内容まで解説し、一段階上の視点から、本サービスの活用イメージをつかんでもらえればと考えています。
【追記】非常に残念なことに、本記事執筆中に、Anomaly Detector のサービス提供について、2026年10月に終了するということが、Anomaly Detector の利用者宛てにメールにて案内されました。多変量異常検出機能の一般提供が、まだ1年経っていない 2022 年の 11 月であることや、異常検知タスクの重要性を考慮すると、かなり突然のアナウンスといった感想です。しかしながら、その重要性を考えれば、後継のサービスが提供されるのではないか?という期待もありますし、また本記事で説明する Anomaly Detector の内部的な仕組みや異常検知の利用用途の解説、また、内部で使用されている SR-CNN の手法自体が、非常に重要な内容であることに変わりはないので、記事として解説する意味はあると考え、そのままブログ記事として掲載しようと思います。
Azure AI の Anomaly Detector は、時系列データの異常検出を行うための機械学習技術を利用したサービスです。この Anomaly Detectorは、一般的なプログラミング言語が使える IT エンジニアであれば、機械学習やAIの知識を必要とせずに、利用することが可能なサービスとして提供されています。
Anomaly Detector の Web APIは、JSON形式のデータを送信するだけで、時系列データ中の異常なデータ点や変化点、異常なデータ相関を高度な機械学習技術によって検出することができます。また、Python、C#、JavaScript に対しては、Anomaly Detector 用のクライアントライブラリが提供されているため、これらのコードから利用する場合は、さらに容易に本サービスを利用することが可能となっています。
Azure AI Anomaly Detectorについて、より詳細を知りたい方や、自社のデータで活用したいという方は、以下の Azure 公式リファレンスについても参照いただければと思います。
Anomaly Detector では、大きく分けて2種類のタイプの機能が提供されています。それぞれ、一変量異常検出、多変量異常検出と呼ばれる機能で、それぞれの機能についての概要の説明は以下となります。
【一変量異常検出】 変数が1つの時系列データに対して異常検知を行う機能です。例えば、時刻列が1列、データ列が1列の CSV ファイルや表形式の様なデータが、本機能の対象となります。異常検出の際は、過去のデータ、もしくはデータ全体を用いて、季節性やトレンドの分解、周波数特徴量の抽出などを行うことによりデータを数理モデル化し、その上で異常なデータの外れ値やデータの急変化を検出します。
この際、どの様なアルゴリズムで異常検知を行うかについては、Anomaly Detector 内で、入力された時系列データの種類を機械学技術により分類することにより、適切なアルゴリズムの組み合わせを自動で選択する仕組みになっています。例えば、季節性のあるデータ、季節性が無くかつ時間粒度が荒いデータ、季節性が無く時間粒度が細かいデータ、などの様に時系列データを分類し、その上で最適なアルゴリズムを選択します。
また、一変量異常検出の機能は、さらに3つのサブタスクに分類されています。
以下のグラフは、公式リファレンス上で公開されている、Anomaly Detector の対話型デモを用いて、ストリーミング検出とバッチ検出を実際に試してみた結果の画像です (上図:ストリーミング検出、下図:バッチ検出) 。実線が検知対象としたデータを表し、赤点が異常として検出されたデータ点、薄い紫の範囲は、Anomaly Detector が異常とみなす閾値の範囲を示しています。なお、今回この対話型デモで使用したデータは、単純な正弦波に若干のホワイトノイズを載せて生成した数値で、異常部分として一定期間だけ波の周期を短くしています。
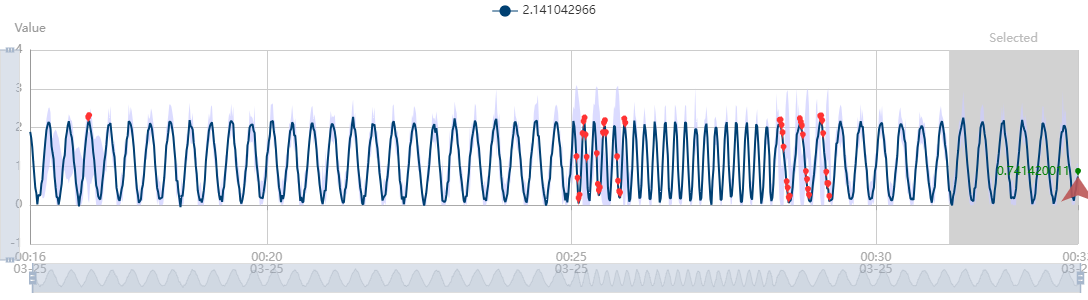
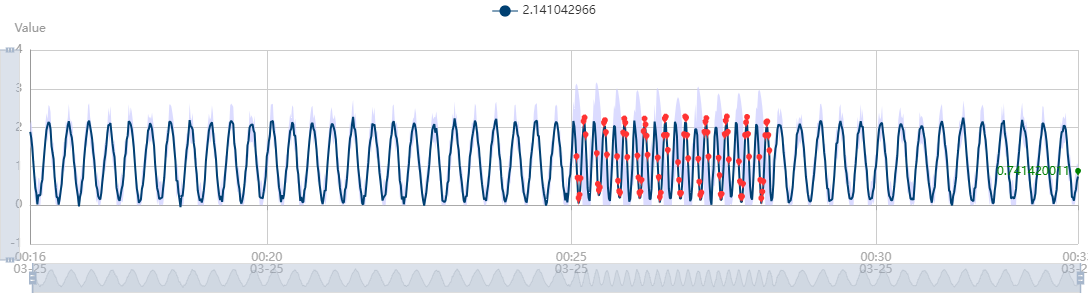
この図でわかる通り、ストリーミング検出とバッチ検出では、どこが異常として検出されるかに差が見られます。ストリーミング検出では、波の周期が短くなったはじめの期間と、逆にまた元の周期に戻った終わりの期間が異常として検知されているのに対し、バッチ検出では周期が短くなっている全期間が異常として検知されています。
この挙動は仕組みを考えれば当然で、ストリーミング検出を利用した際に使用した窓の期間が、波の周期異常が生じている期間より短いために生じた現象です。入力データを窓の範囲で区切って、 API に過去の時点から順番に送信していくとします。すると、窓の期間より異常の期間が長い場合、どこかで窓内の大半のデータ点が異常データになることが生じます。その時は、異常データのみを用いてモデルが生成されることになるので、この図の様に、異常の発生時と異常の終了時以外は、異常とみなされない結果になります。こうした挙動から、ストリーミング検出機能は、データの急激な変化を検出する目的により適していると言えるかと思います。
この対話型デモは、プログラミングを利用することなく、Azure に Anomaly Detector のリソースを作成すれば誰でも試すことができます。以下にデモページへのリンクを載せておきますので、お時間ある方は試してみていただければと思います。
また、一変量異常検知に関する、詳細な仕組みや挙動については、Microsoft の公式技術ブログに記事が掲載されていますので、より詳しく知りたい方はこちらも参照いただければと思います。
【多変量異常検出】 変数が2つ以上の時系列データに対する異常検知機能です。Anomaly Detector では、最大300列の時系列データまで分析することができます。この多変量異常検出機能では、時間方向のデータ構造の異常だけでなく、各列同士の相関についてグラフニューラルネットを用いたモデル化を行うことにより、相関異常の発生についても検出することを可能としています。具体的には、MTAD-GAT : Multivariate Time-series Anomaly Detection via Graph Attention Network と呼ばれる手法を利用しているとのことです。
多量異常検知に関する、詳細な仕組みや挙動についても、Microsoft の公式技術ブログに記事が掲載されていますので、より詳しく知りたい方はこちらも参照いただければと思います。
この様に、一変量異常検出の API と 多変量異常検知の API では、内部で利用されている数理モデルに加えて、API を利用する手順についても差異があります。以降、本記事では、前者の一変量異常検出の機能を中心に紹介していきます。
Anomaly Detector の公式リファレンスや、技術ブログ、手法を提案した論文を参考として、一変量異常検出、多変量異常検出、それぞれの機能で想定されている利用対象のデータや、利用場面について記載すると、以下の様になるのではと思われます。
【一変量異常検出の利用対象】
※ Microsoft が提案している Anomaly Detector の論文では、Web サービスの例としてBing、Office、Azure などが例に挙げられています。
一変量異常検出では、Web サービスの健全性維持を目的とした、ストリーミング検出 APIによる各種指標の監視などが、主要な用途の一つとして想定されています。また、バッチ検出 API では、月次・週次・日次程度の時間粒度を持つ時系列データについて、ビジネスに影響を与える可能性がある異常な兆候や変化の発生を早期に発見する、といった活用方法が考えられます。
Anomaly Detector の論文や公式技術ブログを参照すると、一変量異常検出機能は、オンライン Web サービスの健全性の監視について、特に主眼を置いていることが記載されています。それらのサービスでは、何百万もの時系列形式の指標データが監視対象であり、それらの時々刻々と状態が変化するデータについて、リアルタイムで異常を監視するには、データ毎に異常検知モデルを学習させるアプローチは、現実的ではありません。
そのため、Anomaly Detector の一変量異常検出 API では、Microsoft 自身が提案している SR-CNN と呼ばれる手法が利用されています。この SR-CNN は、時々刻々とデータの分布が変化するタイプの時系列に対して、データ毎に個別のモデルを学習することなしに、上手く異常を検知できることが、論文内で主張されています。
逆に言えば、事前に正常なデータを学習しておき、そのデータとデータ分布が異なってきた場合に、その変動を検知するというタイプの目的には適さないということです。この様な例としては、例えば機器の故障が発生する前の予兆の様に、変化が少しずつ生じるような場合が考えられます。また、各種データ間の相関に異常が生じる様な場合も、一変量だけの異常監視では対応できません。そのため、この様な状況が多く生じ得る、機器の予知保全などの用途を目的とする場合、Anomaly Detector の一変量異常検知 API は、あまり向いていないかもしれません。
なお、一変量異常検知に関して Microsoft が提案している論文の内容は、以下のページで読むことが出来ます。
【多変量異常検出の利用対象】
多変量異常検出では、複数のデータ間の相関構造についてモデル化し、その相関構造に生じた異常を検知することが可能です。また、正常な状態のデータを用いたモデルの学習を用いた仕組みとなっており、この際、データの時間方向の構造だけでなく、各データ間の相関構造についても同時にモデル化する仕組みとなっています。
適用可能な対象としては、工業用の機械や、自動車、航空機、宇宙船の様な多数のセンサーを備えたかなり複雑な機器についても言及されており、機器の故障などに対する予知保全についても主目的として考慮されていると考えられます。また、多数のデータ間の相関異常を検出できる特性から、複雑なソフトウェアやサーバーの AI 監視システムなどにも利用することができるとのことです。
その一方で、事前学習が必要ということから、対象のデータが時々刻々と変化してしまう場合や、大量の監視対象が存在するために、事前にモデルを学習することが困難という場合は、向いていないことが分かります。よって、その様な利用対象については、一変量異常検出を選択するべきということになります。
この様に、Anomaly Detector という一つのサービスではありますが、一変量異常検出機能と多変量異常検出機能では、対象となるデータの種類に加え、その利用目的も異なっていることが分かります。一言で時系列データの異常検知と言っても、利用目的やデータの種類に合わせて、適切な手法を選択することが重要なポイントであると言えます。
Azure AI サービスでは、提供されている API の内部で用いられている機械学習モデルやその前処理手順、特徴量生成処理などについて、基本的にはブラックボックスであることが一般的で、具体的な手法レベルの情報については、非公開であることがほとんどです。
しかしながら、Anomaly Detector については、前述した技術ブログや論文という形で、一部ですが内部で利用されている手法や技術について公開されています。今回は折角なので、その公開されている情報の中から、Microsoft が Anomaly Detector に関する論文にて提案した、一変量異常検知の手法である SR-CNNの概要について、本節で紹介できればと思います。なお、この当該論文は、前節にリンクを記載した、”Time-Series Anomaly Detection Service at Microsoft”, arXiv:1906.03821 [cs.LG] となります。
また、本記事では、上述した論文に加えて、以下の公式技術ブログの説明も参考としています。
本手法の重要なポイントは、1次元の時系列データに対して、Spectral Residual (SR) 法と呼ばれる、フーリエ変換を利用した特徴量抽出を行う点にあります。名称の SR もSpectral Residualの略称です。このSR 法は、もともとは画像データ、つまり2次元配列形式のデータに対して、特徴的な部分を強調した画像を得る目的で利用されていた手法です。その様な、画像のことを顕著性マップ、もしくは英語でサリエンシーマップと呼びます。実際に画像データから得た顕著性マップの例が、上述した “Overview of SR-CNN algorithm in Azure Anomaly Detector” の記事中の “Inspiration” 節に掲載されていますので、時間のある方はその画像についても参照いただくと、顕著性マップのイメージが付きやすいかと思います。
この SR 法を用いると、画像中で特徴的な領域、つまり画像中の他の領域と比較した時に、傾向が異なる様な領域がどこか?ということについて、強調された画像マップを得ることが出来ます。この SR 法を1次元配列の時系列データに適用すれば、異常な特徴の部分が強調された時系列データの顕著性マップを得られるのではないか?というのが、SR 法を時系列データの異常検知に適用してみた動機とのことです。なお、顕著性「マップ」と記載していますが、この場合は顕著性マップも1次元配列となります。
この SR 法の具体的な手順は、フーリエ変換に関する知識が必要となり、普段それらの手法になじみがない方には若干ハードルが高いので、最後にまとめて記載します。ひとまずは、SR 法を使うと、データ内の特徴的な部分を強調することができるということだけ、理解しておけば問題ありません。
実際に、1次元配列の時系列データに対して、 SR 法を適用した結果のグラフが、当該論文の Figure 4 に載せられています。以下の画像は、その画像を引用したものです。
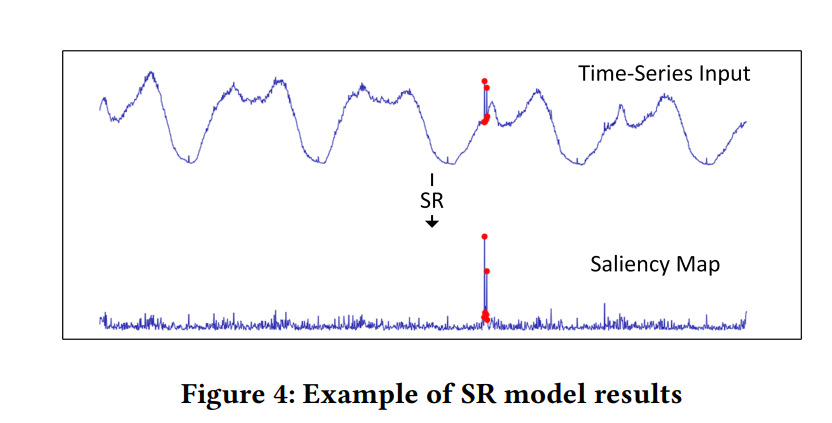
上側の実線が入力された元の時系列データで、下側の実線が SR 法によって変換された時系列データの顕著性マップに相当するグラフです。この図をみると、元データ中の特異的な変動をしている部分において (赤点のデータ)、顕著性マップの値が大きくなっていることが分かります。
異常検知のタスクは、データ中で他の部分とは異なる領域を探し出すタスクともいえます。そのため、この SR 法を用いれば、時系列データ中で他の部分とは異なる特異な振る舞いをする領域、つまり異常である可能性が高い領域について、顕著性マップという形で上手く抽出することができるということが予想されます。とはいえ、特異的に振る舞う領域が必ず異常であるとは言い切れません。この点については、後述する CNN 層の導入によって解決します。
単純に考えると、この顕著性マップの出力結果をそのまま用いるだけでも、ある程度は異常検知ができてしまいそうに思われます。そこで、例えば以下の様な式で異常検出のルールを定め、ルールで定めた評価指標が、ある閾値より大きい場合は異常、それ以下では正常と見なすとすれば、比較的単純なルールで異常検知を行うことができます (当該論文中の式 (7) )。

なお、上式では、閾値が τ、x_iは時系列データのある1時点の値、O(x_i) の値は、異常では1、正常では0です。また、S(x) は顕著性マップの値、S(x) の上部に線が引かれている記号は、顕著性マップの局所的な平均値を示しています。つまり、この式は、顕著性マップの値が回りの平均値と比較して大きな値を取っている部分を異常であると見なそう、という異常検出のルールを示しています。
このルールは直感的にはある程度上手く機能しそうに思えますが、さすがに異常の検出ルールとしては、若干単純すぎるとは言えます。前述した様に、顕著性マップの値が周りの領域と比べて大きいからと言って、その部分が異常であるとは必ずしも言い切れません。
そこで、当該論文では、この異常の検出ルール部分をより一般化することに考察を進めます。その方法として提案されているのが、式 (7) のルールの部分を、CNN (畳み込みニューラルネットワーク) による正常・異常の二値分類モデルに置き換えてみる、という方法です。
つまり、下図 (当該論文の Figure 5 より引用) の様に、SR 法で生成した顕著性マップに対して、さらに CNN による二値分類モデルの層を追加することになります。この手法を当該論文では SR-CNN と呼んでいます。なお、当該論文では、CNN による二値分類モデルとして、2層の1次元 CNN 層+2層の全結合層+出力のシグモイド関数の構成を採用しています。
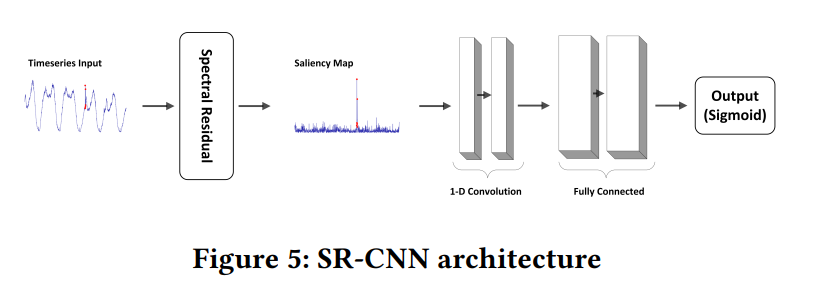
この際、CNN による二値分類モデルの部分については、何等かの正常、異常のラベル付きデータを用いて、パラメータの学習を行う必要があります。この学習処理を監視対象とするデータ毎に実施するのは、今回目的としている、全く種類の異なる時系列データが大量に存在するという状況では適していません。
そこで当該論文では、人工的に生成した異常値を注入したデータを用い、CNNによる二値分類モデルの学習を事前に行っておく、という手法を取っています。この方法であれば、新規データ毎に学習処理を行うことなしに、汎用的に時系列データの異常検知を行うことができる可能性があります。
当該論文では、上記手順が有効に働くかどうかを検証するため、いくつかの検証用のデータセットを用いて性能の評価を実施しており、全体的な結果として SR-CNN が、既存手法よりも良い結果を得ていることを主張しています。なお、検証用のデータセットとしては、複数の IT 企業から提供された KPI 時系列の公開データセット、Yahoo 社が公開している時系列異常検知の検証用データセット、Microsoft 社自身で収集した自社サービスに関する内部データセットを利用しています。
また、入力データに対して SR 法を用いることの有効性についても、当該論文では検証しています。具体的には、深層学習を用いた教師有り二値分類モデルの入力データとして、SR 法を用いない元々の時系列データを直接入力データにした場合と、SR 法によって顕著性マップに変換した上で入力データにした場合とで、異常検知の性能比較を行っています。結果として、SR 法を実施したデータを入力データとした方が、異常検知モデルとしての性能が向上するという結果が得られたと主張しています。
以上が、SR-CNN 手法に関する概要の解説となります。
ここまで、SR 法で行う具体的な計算手順については、説明していませんでした。以下では、SR 法について、その手順の概要を説明します。なお、フーリエ変換の知識を前提とするので、特にその辺りに詳しくない方は読み飛ばしていただいて問題ありません。
SR 法の計算手順について、順番に箇条書きで説明すると、以下の3ステップに分けられます
なお、2番目の手順が Spectral Residual という名称の由来です。この操作を行うことにより、周波数領域において、特徴的な周波数成分、つまり近傍の他周波数成分と比較した時に逸脱が大きい成分の振幅が強調されることになります。
言葉での説明は以上なのですが、さすがにこれだけでは分かりづらいので、当該論文に記載されている数式の手順を引用すると以下となります。

数式の各記号については、引用した画像中に英語で説明されていますが、日本語でそれぞれの記号について説明すると以下となります。
なお、当該論文では、フーリエ係数の振幅の平均値 AL を計算する際に、畳み込み処理によって平均を近似計算すると書かれています。その際、任意の整数値 q について、q×q 行列 hq(f) を畳み込み計算のフィルタとして用いると記載しているのですが、今回の対象は1次元配列データのため、畳み込み処理も1次元配列のフィルタとなるはずのため、この部分の説明は論文の記述ミスなのではないかという気がします。この点について、元の Spectral Residual の論文では2次元配列の画像を扱っているため、q×q 行列をフィルタとした畳み込み処理と書かれています。その記述をそのまま持ってきてしまった、ということなのかもしれません。
この計算手順によって得た S(x) の値が、SR 法による顕著性マップとなります。なお、単純にこの計算を行うと、顕著性マップの両端、つまり時系列データの初めの時点および最後の時点付近において、データが有限長であることから生じる、意図しないピーク信号が生じてしまう傾向があります。当該論文では元時系列データの最終時点以降に、追加のデータを補完して埋め合わせることにより、この問題をうまく回避する工夫を行っています。
SR 法についての概要の説明は以上となります。
本記事では、Azure AI サービスの Anomaly Detector について、提供されている機能の特徴や、各機能の利用用途に関して、公開されている技術情報も踏まえた上で、ある程度詳しく解説しました。また、一変量異常検知については、公開されている論文の内容も参考にして、さらに一歩踏み込み、内部で利用されている異常検知手法である、SR-CNN についても、その技術的内容を説明しました。
異常検知技術は、製造業における予知保全を目的とした利用だけでなく、情報・通信の領域におけるシステムの正常性監視やネットワーク監視にも利用されるなど、広い領域で活用できる技術です。それら、現実の課題を解決する際に、当記事で解説した Anomaly Detectorや異常検知技術に関する技術的内容が、少しでもお役に立てば幸いです。
また、本記事では、Anomaly Detector の多変量異常検知機能について、その中身の仕組みをほとんど説明することが出来ませんでした。この多変量異常検知に関しても、ある程度技術情報が公開されているため、機会があれば別途記事として紹介できればと考えています。
なお、当社では時系列データに限らず、画像、言語、マーケティング、 Web サイト、 IoT機器のセンサーデータなど、様々な領域のデータについて、 AI や機械学習技術を通した支援を行っています。また、これら技術に関する、新規技術の検証や開発に関するサポートについても承っておりますので、より高度なデータ活用を進めたい、技術的支援を希望したいなどのご要望がありましたら、ぜひ当社までご相談いただければと思います。
関連ブログ記事
ノーコード AI 構築ツール:Azure ML デザイナー を使って、時系列データの異常検知を実践する【後編】
|
関連ページ
機械学習導入支援サービス |
