こんにちは。データサイエンスチームの八木です。
DX が話題になっている昨今、皆さんはどのようなデータを収集・活用されていますか?
データには大きく構造化データと非構造化データがあります。ExcelやCSV などの構造化データの活用はすでに私たちの身近なものとなりました。そして、テキストや音声、画像、動画などの非構造化データについても近年活用が進んでいます。特に音声認識の分野では、議事録作成やテープ起こし業務の効率化、顧客満足度の向上を目的としたコールセンターの品質改善などでも広く活用され始めています。そこで今回は音声のデータをテキストに文字起こしするサービスである、Microsoft の Azure Speech to Text をご紹介しようと思います。
Azure Speech to Text とは、Microsoft が提供する音声をテキストに文字起こしするサービスのことです。これは、音声テキスト変換、テキスト読み上げ、音声翻訳などを提供する Speech Service 内のサービスの一つです。Azure Speech to Text を使えば音声のデータからテキストに文字起こしすることが簡単にでき、その結果を自然言語処理 (NLP) で分析して顧客満足度の向上につなげたり、議事録作成やテープ起こしの作業時間を削減したりすることが可能です。
Azure Speech to Text には 2 つの Web API が用意されています。バッチ処理かオンライン処理 (リアルタイム処理) のどちらに対応しているかという点が大きな違いです。
Azure Speech to Text の良い点、および使用する上で気を付ける点は以下です。
また、UIとして別途用意されている Speech Studio を使用することで、コードを書くことなく音声からテキストへ変換することができます。Speech Studio とは、Azure 音声サービスの機能を構築および統合するための UI ベースのツールセットのことです。GUI で作業ができ、リアルタイム音声テキスト変換や発音評価など様々な機能をコーディングすることなく使用することができます。次の章ではこの Speech Studio を使って、コーディングなしで音声を文字に起こしする手順について説明します。
Speech Studio のサイトにアクセスします。
https://speech.microsoft.com/portal
アクセスするとサインインを求められますので、ご自身の Azure アカウントでサインインを行ってください。
※ Speech Studio を使用するためには、Microsoft アカウントと Azure アカウントが必要です。無料で試すことができますので、まだ持っていない方は以下を参考に作成してみてください。
https://docs.microsoft.com/ja-jp/azure/cognitive-services/speech-service/overview#try-the-speech-service-for-free
サインインに成功すると、以下の画面が表示されます。
[リアルタイム音声テキスト変換] をクリックし、今回使用する Azureの[サブスクリプション] と [リソース] を選択したら、[リソースの使用] をクリックします。今回初めて使用される方は、[新しいリソースを作成する] をクリックして、新規リソースを作成してください。
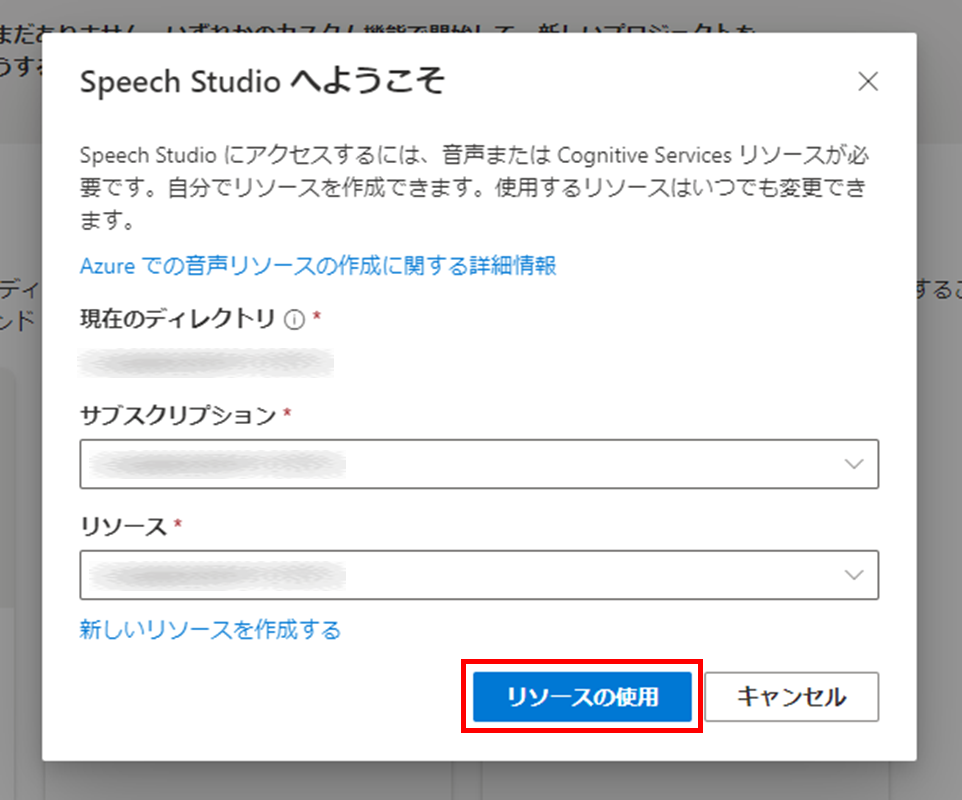
すると、[リアルタイム音声テキスト変換] の画面が表示されます。
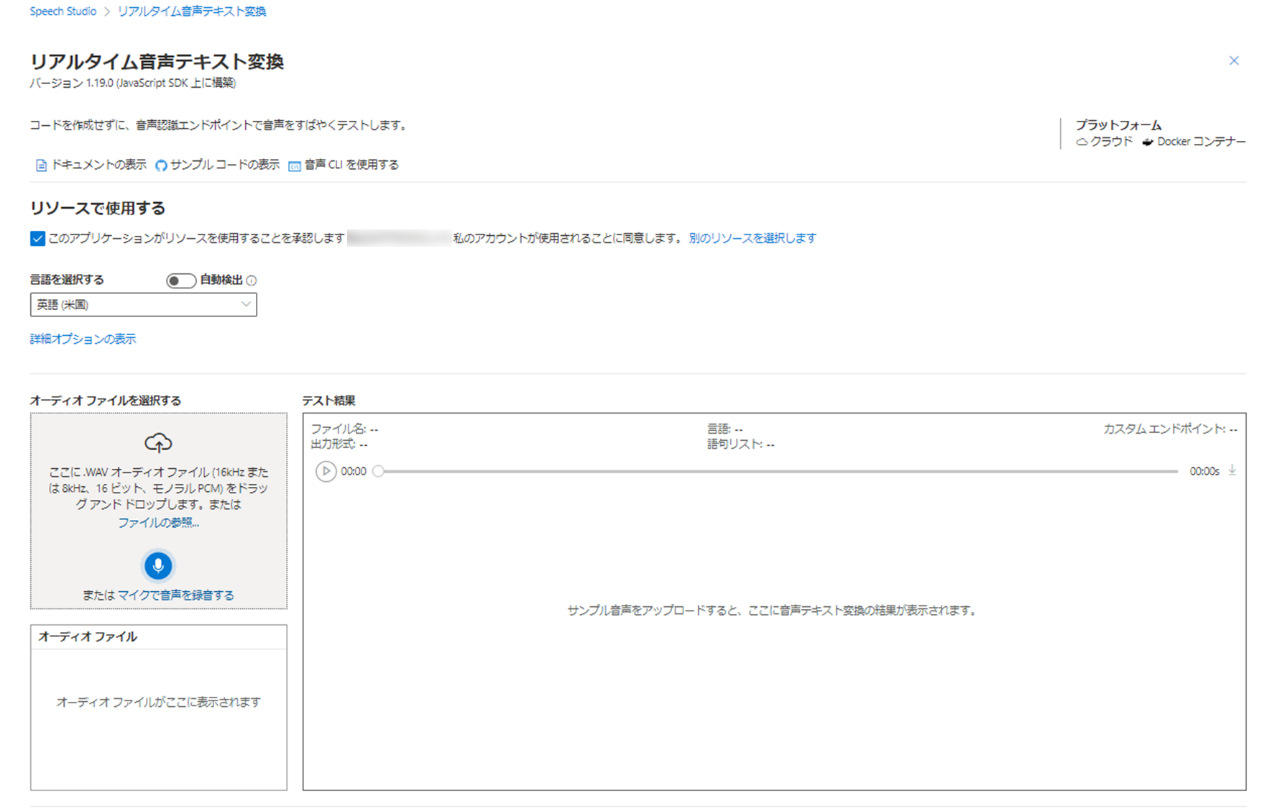
早速ファイルをアップロードして結果を見てみたいと思います。今回は Speech SDK にサンプルとして用意されている日本語のデータで試してみようと思います。以下 URL から Speech
SDK の
GitHub にアクセスし、[Download] をクリックしてください。
https://github.com/Azure-Samples/cognitive-services-speech-sdk/blob/master/sampledata/customspeech/ja-JP/training/audio-and-trans.zip
ダウンロードしたフォルダを解凍すると、2 つのファイルが入っています。1 つが日本語の音声データ、もう 1 つが正解のテキストデータです。日本語の音声データは合成音声で、Custom Speech についての内容になっています。

[audio.wav] をアップロードして文字起こしを実行しましょう。まず、[言語を選択する] から [日本語(日本)] をクリックします。
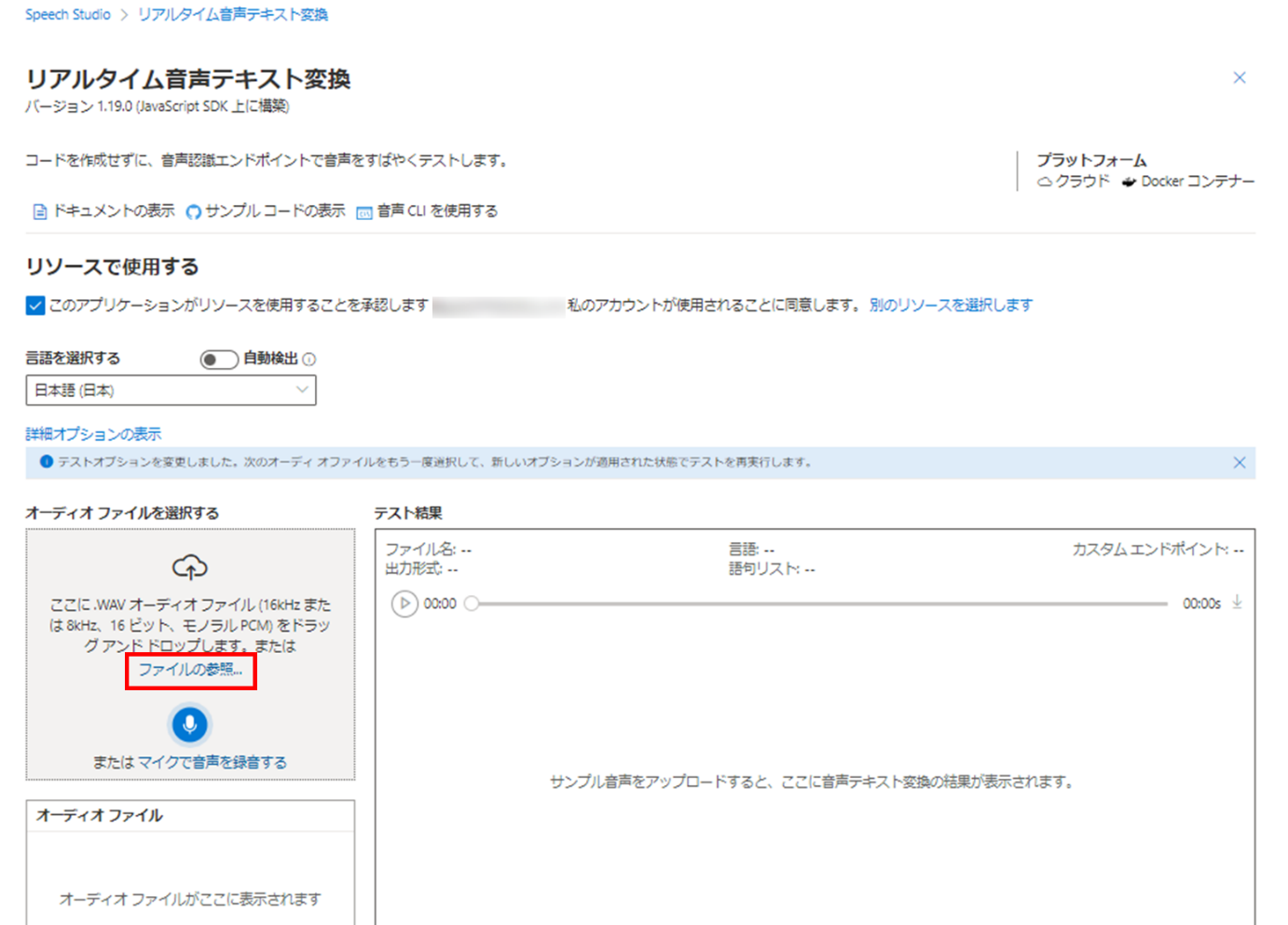
その後、[ファイルの参照] をクリックしてファイルを選ぶか、グレーの [オーディオ ファイルを選択する] 欄にファイルをドラッグアンドドロップしてください。
使用できるファイルは WAV オーディオファイル (16kHz または 8kHz、16ビット、モノラル PCM) のみとなっています。
音声データのアップロードが完了すると、自動で文字起こしが始まります。解析の実行中は [オーディオ ファイル] のファイル名の前にあるアイコンが回転していますが、実行完了すると緑色のチェックマークに変わります。
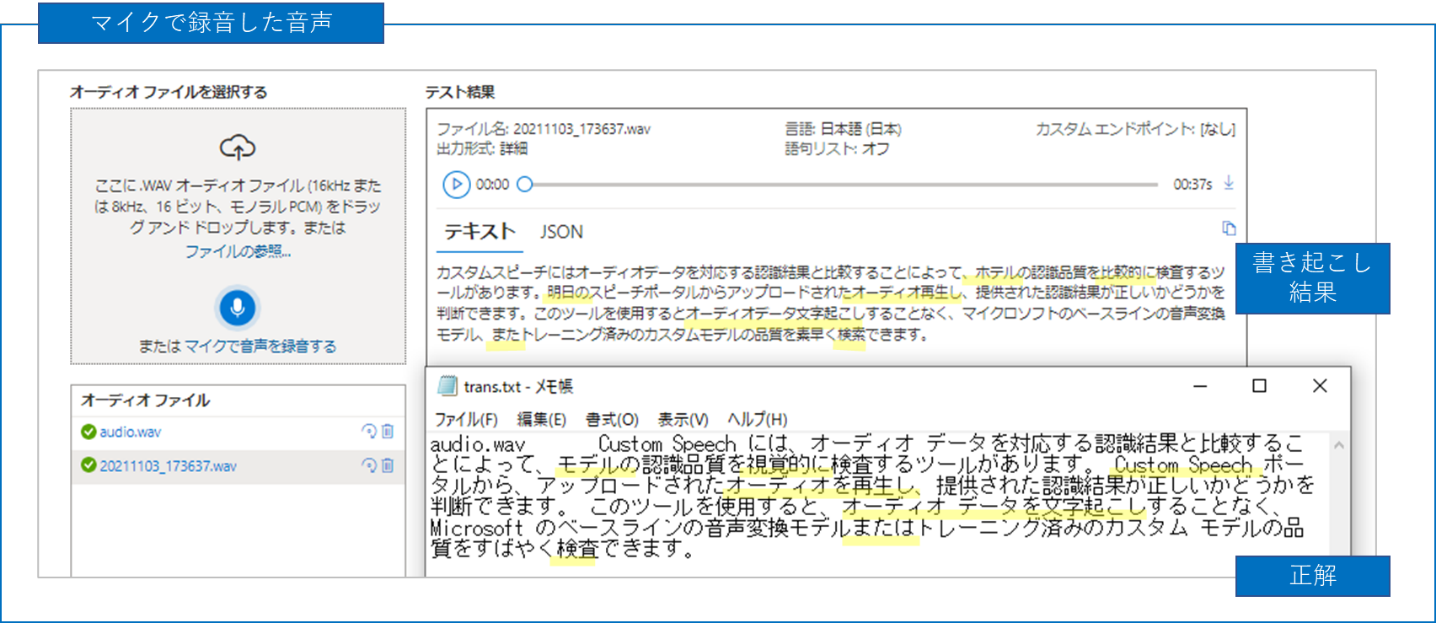
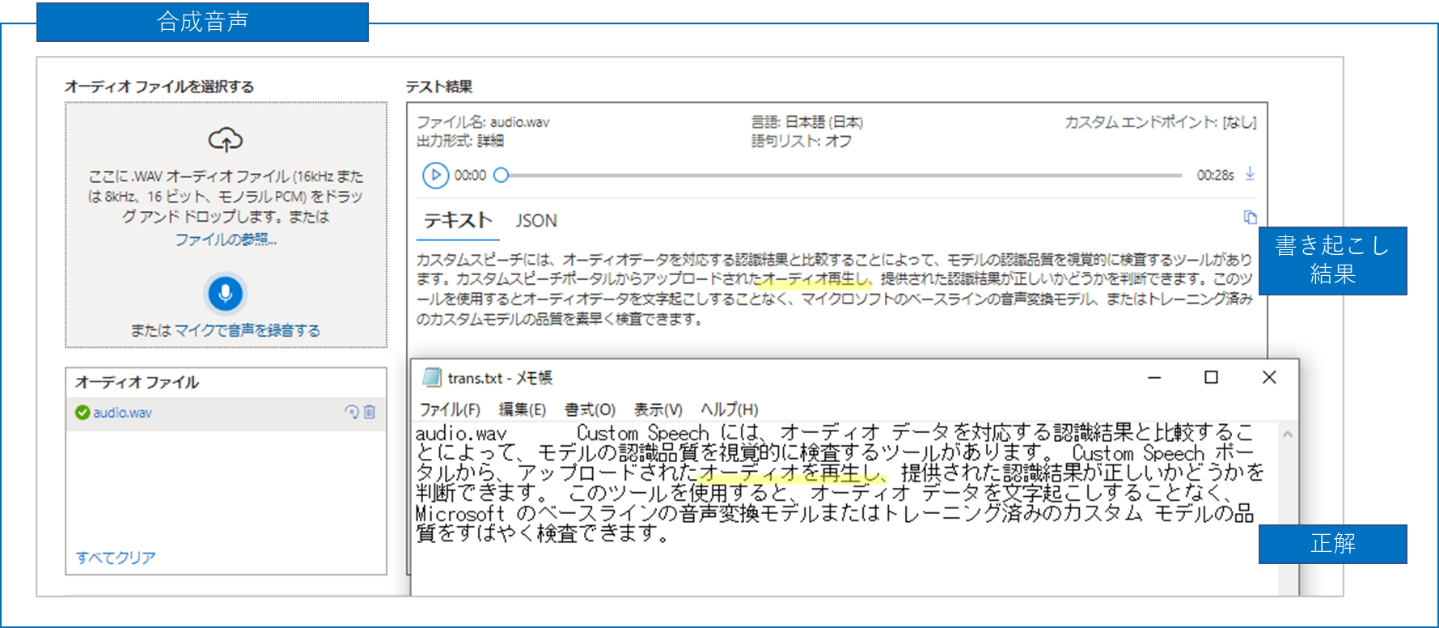
実行が完了したら、結果を確認してみましょう。ここでは、同じスクリプトに対して作成された合成音声と実際にマイクで録画した音声の結果を比較してみます。結果を見ると、合成音声はほとんど合致していますが、今回マイクで録音した音声については誤認識しているものが多く見られました。実際の人の声をテキスト化するのはそのまま提供されているモデルでは難しいかもしれません。その場合は Custom Speech を使ってモデルをカスタマイズすることも可能です。
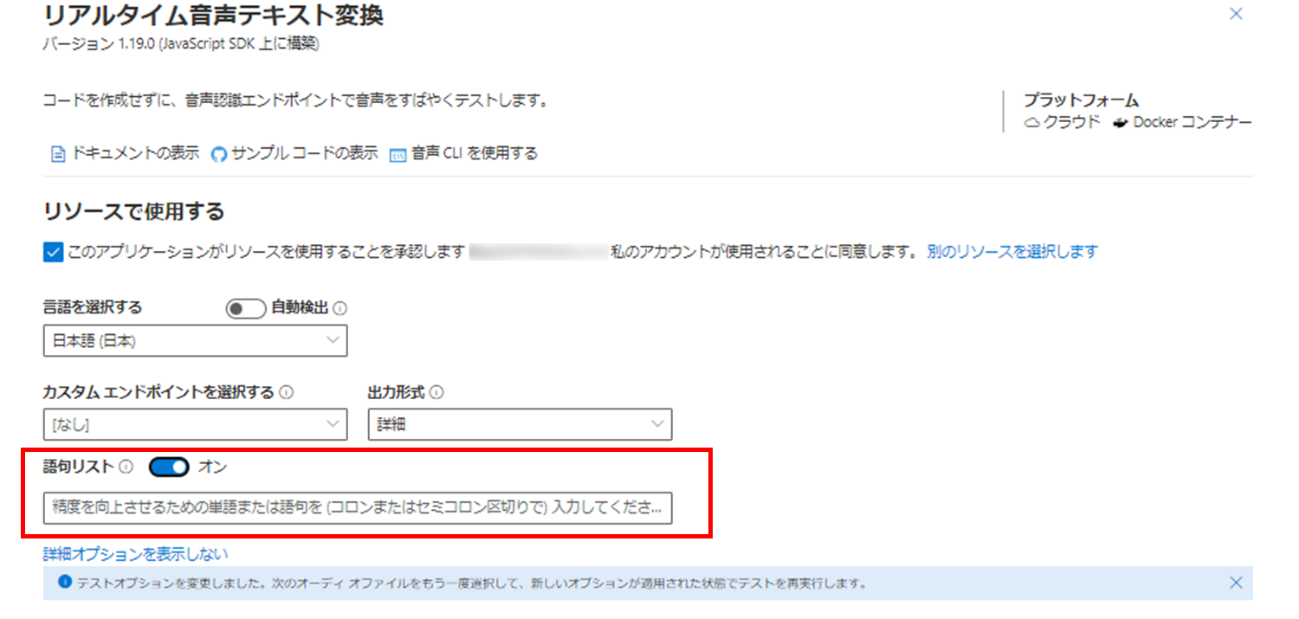
また、精度を向上させるための取り組みとして固有名詞に対応したい場合は [オーディオ ファイルを選択する] の上にある [詳細オプションの表示] から個人の氏名や特定の場所、業界用語などを指定することも可能です。
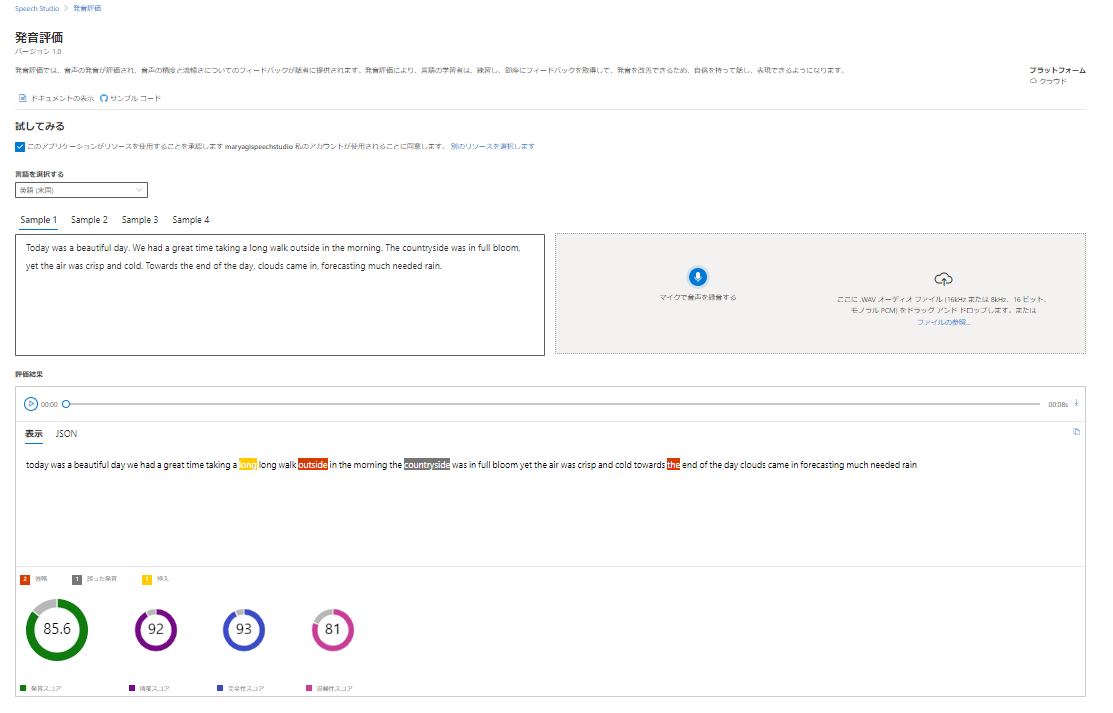
今回は音声データからテキストへの文字起こしをリアルタイムで行った結果を見てきましたが、最近ではリアルタイムの発音評価も実施できるようになり、発表者に音声の精度と流暢さに関するフィードバックを提供できるようになりました。
さらに、プレビュー中ですがテナントモデル (Custom Speech with Microsoft 365 data) というサービスもあり、組織の Microsoft 365 データからカスタム音声認識モデルを自動的に生成し業務効率化に活用することも可能です。
Microsoft が提供する音声をテキストに文字起こしするサービス、Azure Speech to Text をご紹介しました。Azure Speech to Text を使えば音声のデータからテキストに文字起こしすることが簡単にでき、その結果を自然言語処理 (NLP) で分析して顧客満足度の向上につなげたり議事録作成やテープ起こしの作業時間を削減したりすることが可能です。Azure Speech to Textは Azure アカウントがあればすぐに試すことができますので、ぜひご自身でもどのような結果になるか試してみていただければと思います。
弊社では、このような Azure のサービスを使用した AI 活用支援をはじめ、様々な分野での機械学習モデル構築やデータ分析支援を承っております。現行の作業を軽減してより重要な作業に時間を当てたい、取得しているデータを活用して課題解決を行いたいなどAIや自社データの活用を検討しているご担当者の方がいましたら、ぜひ弊社までお問い合わせください。実際に機械学習モデルをアプリケーションに組み込みたいお客様や、DX を推進したいがまず何から始めればよいか悩んでいるといったお客様も、お気軽にご相談いただければと思います。
関連ページ |




