こんにちは。データサイエンスチームの高橋です。
日々増えていくテキスト、どのように分析していますか?
アンケートの自由記述や SNS 上の口コミを活用したいけどできていない、このような現状はないでしょうか。
現在、DX の推進にはデータ活用が不可欠と言われており、テキストのような非構造データをどう活用するかが重要となっています。
テキストの分析には「自然言語処理」の技術を利用します。自然言語処理は Natural Language Processing (NLP) とも呼ばれ、近年では AI を活用した NLP の技術が発展しています。その NLP において、現在最も広く使われている強力な技術として BERT というものがあります。当社でも活用している BERT は、Google が 2018 年に発表した NLP における機械学習モデルで、様々なテキスト分析タスクで高い性能を示しています。
また BERT は非常に汎用性が高いことも特徴となっており、ビジネスでも様々な活用が考えられます。例えば、SNS 上の口コミを分析するといったマーケティングへの活用や、チャットボットに応用して、社内外の FAQ を自動処理するといった業務効率化への活用などが考えられます。
しかし BERT は非常にモデルサイズが大きく、ゼロから自前で実装して学習させると非常にコストがかかります。また現在では ELECTRA や RoBERTa のような BERT の派生モデルも数多く登場しており、これらのモデルを逐一自前で用意するとなると、途方もない労力が必要となります。
そこで本記事では、このような労力をなくし、手軽に最先端のモデルが扱えるようになる Transformers というライブラリを活用して、 BERT と ELECTRA のモデルを利用してみようと思います。
Transformers とは Hugging Face 社が公開している、最先端の NLP モデルの実装と事前学習済みモデルを提供するライブラリです。Transformers を利用することで、BERT やその派生モデル (2021 年 11 月現在で 82 種類!) を誰でも無料で手軽に利用することができます。
また、NLP の代表的なタスク (文書分類、文書生成、質問応答、要約、固有表現抽出など) の実装も用意されているので、BERT をはじめとする事前学習済みモデルと組み合わせることで、簡単にモデルの構築を行うことが可能です。
Transformers は Python の実行環境があれば利用可能で、pip コマンドや conda コマンドで簡単にインストールできます。機械学習のフレームワークとしては PyTorch や TensorFlow、JAX が利用できます。
前章でも触れた BERT は、一言で表すと「すごい NLP モデル」です。BERT の登場によって NLP は急速に進化し、現在では NLP をやるなら BERT のような地位を築いているモデルとなります。
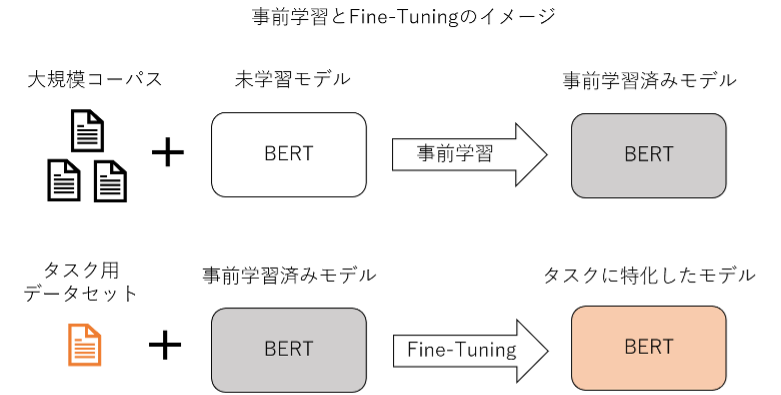
BERT では大規模コーパス (大量の自然言語のデータ) を用いて事前学習を行っています。これにより、文法や単語の意味といった汎用的な言語知識を捉えたモデルが作成されます。BERT を利用して特定のタスクを解きたい場合は、この事前学習済みのモデルをベースにして、タスク用のデータセットで Fine-Tuning (事前学習済みモデルを再学習し調整) を実施することで、タスクに特化させたモデルを作成することが一般的です。
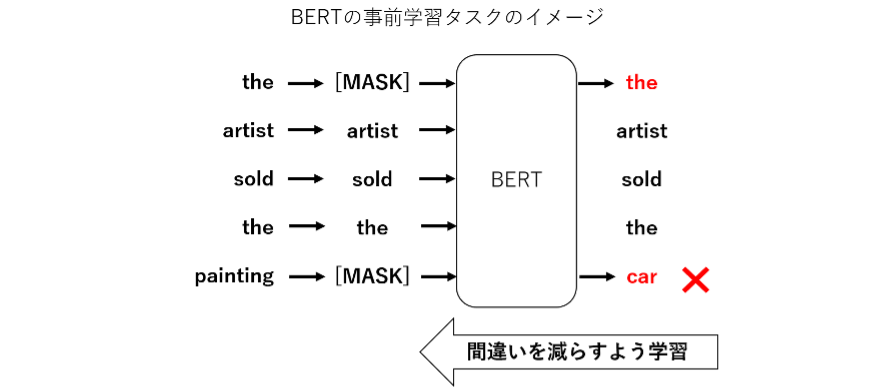
BERT では事前学習のタスクの 1 つとして、文中でマスクされた単語の穴埋めタスクを行っています。マスクされた単語を推測するためには、その周辺の文脈や文法の情報をうまくとらえられる必要があります。BERT では Attention 機構という特徴的な仕組みによって、文中の単語間の関係性が学習でき、文脈や文法の情報をうまく捉えられるモデルとなっています。この結果、より人間に近い文章の解釈が可能となり、様々な NLP タスクで高い性能を示しています。
BERT の登場後、たくさんの派生モデルが考案されています。その中でも BERT の後継ともいえるモデルとして ELECTRA があります。ELECTRA は Google が 2020 年に発表したモデルで、BERT の事前学習を改良して性能向上を報告しているものです。ELECTRA は Generator と Discriminator という2つのモデルから構成されており、それぞれのモデルは BERT と同様の構造となっています。Generator は従来の BERT 同様のマスク穴埋めを学習するのですが、Discriminator では Generator が穴埋めした文に対して、各単語が穴埋めされたものか否かの識別を学習します。
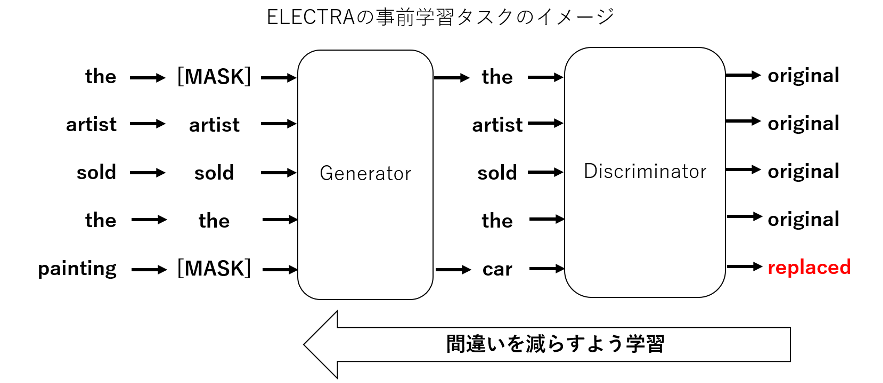
ELECTRA の提案論文において、同じ計算量・モデルサイズであれば ELECTRA は BERT を超える性能を示すことが報告されています。本記事では、Transformers を使って、BERT と ELECTRA の事前学習済みモデルを利用していきます。
本記事では BERT と ELECTRA を利用するにあたって、文書分類モデルを構築していきます。文書分類とは、与えられた文書に対して、それに対応するカテゴリを推定するタスクです。NLP において文書分類は基本的なタスクですが、様々な応用が可能なタスクとなっています。
文書分類の応用として、メールにおけるスパム分類などが有名ですが、前述した口コミの分析や FAQ 用のチャットボットも、文書分類の応用として考えることもできます。口コミの分析であれば、口コミが好意的か否定的かの分類タスクと考えることが可能です。また FAQ 用のチャットボットでは、あらかじめ用意した回答群に対して、質問を分類するというタスクと考えることができます。このように様々な課題を文書分類タスクとしてみなすことができるので、BERT をはじめとする AI の活用を考える際には、「文書分類タスクとみなせるか」という視点で考えてみるのはいかがでしょうか。
今回は、文書分類モデルの構築にあたって、Hugging face で公開されている BERT と ELECTRA の事前学習済みモデルを利用していきます。今回は以下の BERT-Base モデルと ELECTRA-Small モデルを利用します。
それぞれのモデルの情報は以下となります。
左右にスクロールしてご覧ください。
| モデル | BERT-Base | ELECTRA-Small |
|---|---|---|
| 事前学習のコーパス | 日本語 Wikipedia | 日本語 Wikipedia |
| 隠れ層の次元数 | 768 | 256 |
| パラメータ数 | 110M | 14M |
どちらのモデルも事前学習を日本語 Wikipedia で行ったモデルで、パラメータ数がモデルサイズと対応しています。一般的にはモデルサイズが大きいほど、性能が高くなります。BERT と ELECTRA の純粋な性能を比較するためには、パラメータ数を同じにする必要がありますが、検証実施時点で BERT-Base と同等のパラメータ数を持つ ELECTRA-Base モデルが公開されていなかったため、今回は ELECTRA-Small モデルを利用して、BERT-Base モデルにどの程度匹敵するかを確認しようと思います。
文書分類モデルを構築するためには、そのための学習データが必要となります。本記事では、文書分類タスクでよく用いられる Livedoor ニュースコーパスというデータセットを利用します。
Livedoor ニュースコーパスは、ライブドアニュースの記事が 9 種類のカテゴリに分類されているものです。今回は、各記事の本文情報からカテゴリに対応するラベルを推定する設定で、BERT と ELECTRA を用いた分類器を構築します。

今回の検証の全体像は以下の図のようになります。
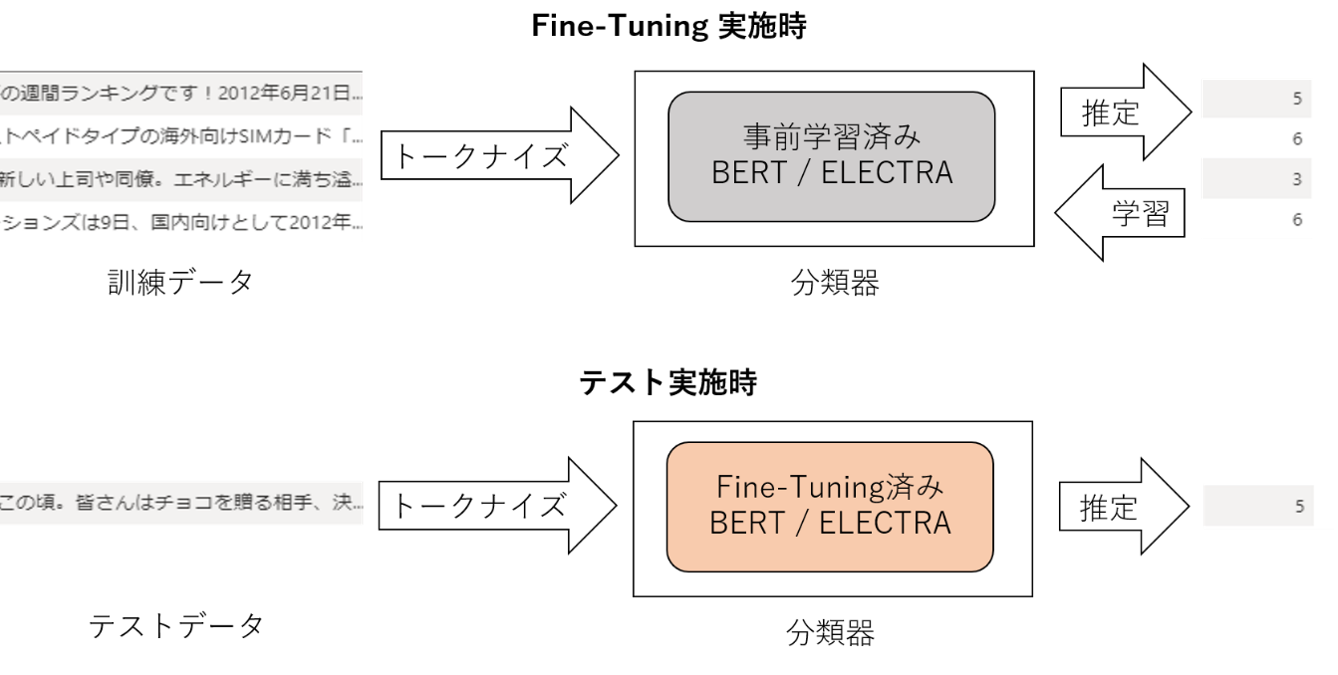
さっそく Transformers を利用してモデルを読み込んでみましょう。Transformers をインストール後、以下のコードを Python で実行するだけで、トークナイザと事前学習済みの分類器を読み込むことができます。 Transformers では BertForSequenceClassification のような分類器の実装が用意されているので、これらを利用することで簡単に分類器を構築できます。
# ライブラリのインポート
from transformers import BertJapaneseTokenizer, BertForSequenceClassification
# トークナイザの読み込み
tokenizer = BertJapaneseTokenizer.from_pretrained(
"cl-tohoku/bert-Base-japanese-whole-word-masking")
# 事前学習済みモデルを利用した分類器の読み込み
model = BertForSequenceClassification.from_pretrained(
"cl-tohoku/bert-Base-japanese-whole-word-masking", num_labels = 9)
モデルを読み込んだ後は、PyTorch を利用して Fine-Tuning を実施していきます。TensorFlow を利用する場合は、TensorFlow 用の Transformers のモデルを読み込んで利用します。
学習・推論部分の実装の詳細は省略しますが、通常の機械学習モデルと同じフローで実装可能となります。
BERT-Base モデルと ELECTRA-Small モデルについて Fine-Tuning を実施し、テストデータでの正解率をまとめたものが以下になります。なお本記事では Jupyter Notebook で実装を行い、Azure Machine Learning 上で実行しています。
左右にスクロールしてご覧ください。
| モデル(パラメータ数) | BERT-Base(110M) | ELECTRA-Small(14M) |
|---|---|---|
| 正解率 | 92.6 | 88.2 |
| 学習時間(時間) | 1.25 | 0.75 |
表の結果から、パラメータ数が 110M とモデルサイズの大きい BERT-Base モデルが高い正解率となることが確認できます。一方モデルサイズの小さい ELECTRA-Small モデルであっても、小さいモデルサイズでありながら 9 割近い正解率を達成しています。また Fine-Tuning に要した時間では、ELECTRA-Small モデルが BERT-Base モデルよりも短くなっていることが確認できます。
推論に要した時間をまとめたものは以下になります。なお CPU での推論時間は Azure NC6 vCPU という CPU を利用し、GPU での推論時間は Azure NC6 1X K80 という GPU を利用しています。
左右にスクロールしてご覧ください。
| モデル(パラメータ数) | BERT-Base(110M) | ELECTRA-Small(14M) |
|---|---|---|
| CPU での1文あたりの推論時間(秒) | 0.3578 | 0.0923 |
| GPU での1文あたりの推論時間(秒) | 0.0708 | 0.0183 |
表の結果から ELECTRA-Small モデルは BERT-Base モデルと比較して約 1/4 の推論時間となることが確認できます。ELECTRA-Small モデルでは CPU でも比較的高速に推論可能であることも確認できます。
以上の結果より、今回利用した 2 つのモデルに関しては、精度を最優先する場合では BERT-Base モデルを利用し、学習時間や推論時間を短くしたい場合や、使用メモリを抑えたい場合では ELECTRA-Small モデルを利用すると効果的であることが分かります。
本記事では Transformers を活用して BERT と ELECTRA で文書分類モデルを構築・評価しました。今回のように複数のモデルの検証を行いたい場合では、Transformers を利用することで効率的に進められると考えられます。BERT や ELECTRA のような最先端の機械学習モデルも Transformers を利用することで簡単に構築・検証を行うことができるので、BERT の活用をご検討されている方は、ぜひ Transformers の利用や、ELECTRA などの派生モデルの活用についてもご一考ください。
AI の活用というとハードルが高い印象を持たれる方も多いかと思いますが、現在は様々なフレームワークやツールの開発により、データさえあればすぐに分析ができる環境も整ってきています。当社でも、アンケート分析や SNS の口コミ分析向けのソリューションである CogEra や、問い合わせ対応自動化を実現する Knowledge Bot 、センサーデータの解析プラットフォームである ML Connect など、ノーコーディングでデータ活用が実現できるサービスを用意しております。また、データ活用の方針検討から AI モデルのスクラッチでの実装についても、ご相談などがありましたら、お気軽にお問い合わせください。
今後は当社が強みとする Azure の AI 関連サービスについてのブログを続々と執筆予定なので、乞うご期待ください。最後までお読みいただきありがとうございました。
関連ページ |




