みなさまこんにちは。クラウドアーキテクトの卵です。
前回の記事で自己紹介を失念しておりました (!!!) ので、ちょっとだけ自己紹介をいたします。
私は元々アプリケーション構築のチームに所属しており、Azure を利用したシステム構築にも携わっていました。縁あってクラウドアーキテクトのチームに異動し、現在はクラウドアーキテクトの卵として活動中です。
今回はそろそろ何か新しいことをして (自分の) レベルアップをしよう!ということで、ビッグデータの分析を実施してみました。
今回は「新しいことやってみよう!」企画として、Azure Data Lake Analytics を触ってみました。
「ビックデータの分析」というと、Hadoop や Spark を使用した大規模データ分析や、R や Python を使用したデータ分析・統計処理を想像するのですが、いずれも手軽にやってみるには少し敷居が高く感じました。
Azure Data Lake Analytics はオンデマンド分析ジョブ サービス(SaaS)です。SQL と親和性の高い U-SQL という言語を使用し、ジョブとして実行することで大容量データを数秒で処理できます。ジョブごとに処理能力(Azure Data Lake Analytics ユニット= AU)を割り当てることで、パフォーマンスを向上することが可能です。料金はジョブの実行時間× AU で算出します。
参考:Data Lake Analytics - Microsoft Azure
https://azure.microsoft.com/ja-jp/services/data-lake-analytics/
参考:Azure Data Lake Analytics とは
https://docs.microsoft.com/ja-jp/azure/data-lake-analytics/data-lake-analytics-overview
上記を基に、今回、私が Azure Data Lake Analytics を触ってみようと思ったきっかけをまとめました。
早速環境を作成し、分析してみましょう!今回は下記の流れで実施しました。
1.Azure ポータルを開き、[Analytics] → [Data Lake Analytics] を選択します。
![[Data Lake Analytics] を選択](/-/Media/SMC/special/blog/ms-azure_blog/2018/0071/dg01.png)
2. 以下を入力します。
左右にスクロールしてご覧ください。
| 項目 | 内容 |
|---|---|
| Name | Azure Data Lake Analytics の名前です。 半角英数字、かつ、3~24文字で入力してください。 |
| サブスクリプション | サブスクリプションを指定します。 |
| Resource Group | リソースグループを指定します。新規作成することも可能です。 |
| 場所 | どのリージョンにあるものを使用するかを選択します。現時点では、以下の4リージョンしか選択できないようです。
|
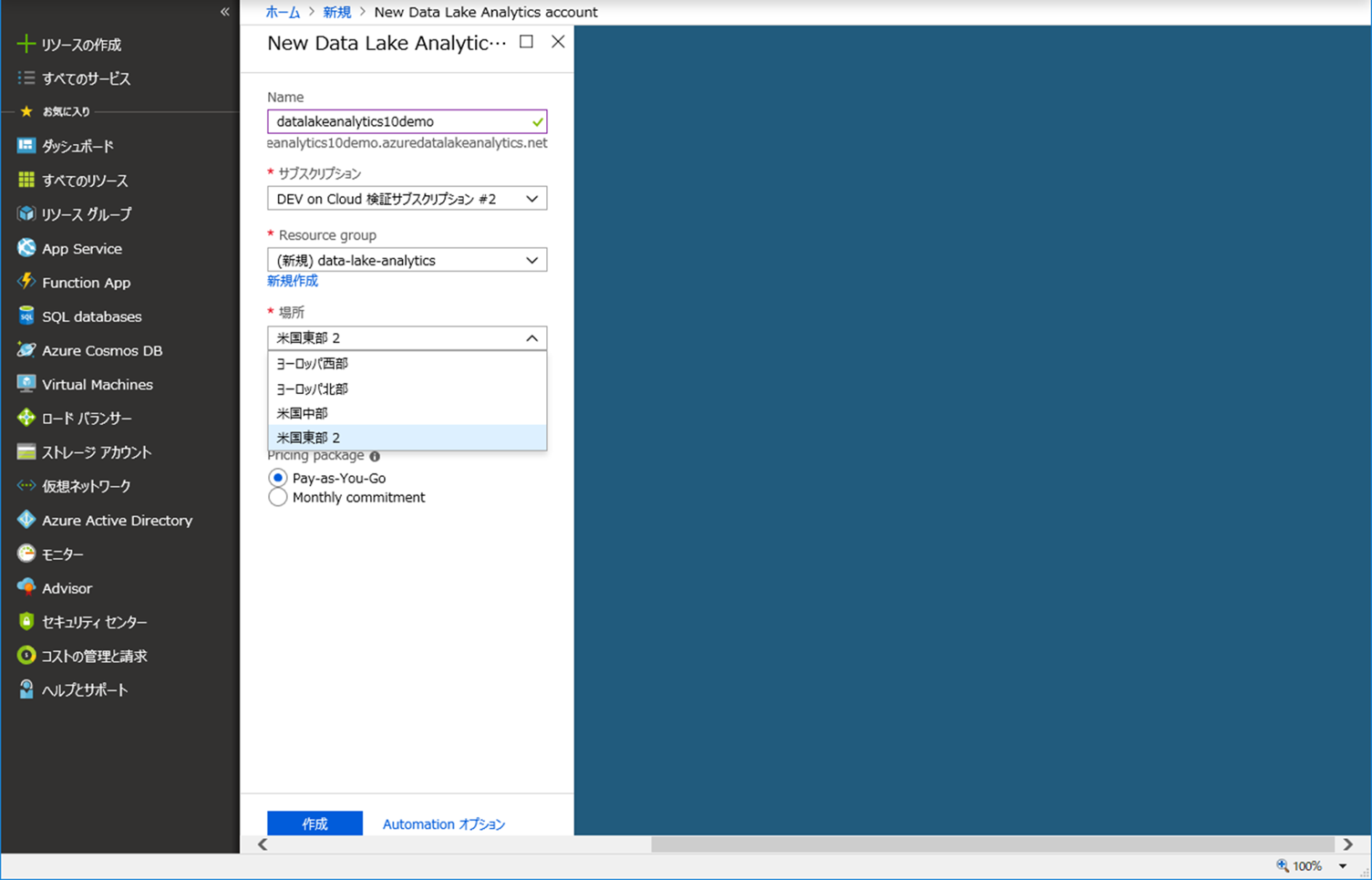
3.Data Lake Storage を選択します。既存の Data Lake Storage を選択することも可能ですが、今回は新規に作成します。
※ ここで選択可能な Data Lake Storage は Gen1 です。現在プレビュー版の Gen2 は選択できないようです。
以下を入力して、[OK] ボタンをクリックします。
左右にスクロールしてご覧ください。
| 項目 | 内容 |
|---|---|
| Name | Data Lake Storage の名前です。 半角英数字、かつ、3~24文字で入力してください。 |
| Pricing package | 課金体系を指定します。以下2種類が選択できます。
|
| Encryption Settings | Data Lake Storage を暗号化するかどうかを指定します。 デフォルトは [Enabled](暗号化有)になっています。 |
![入力して、[OK] ボタンをクリック](/-/Media/SMC/special/blog/ms-azure_blog/2018/0071/dg03.png)
4. 3 で作成した Data Lake Storage が [Data Lake Storage Gen1] に設定されていることを確認し、[Pricing package] を選択して、[作成] ボタンをクリックすると、Azure Data Lake Analytics 環境が作成できます。
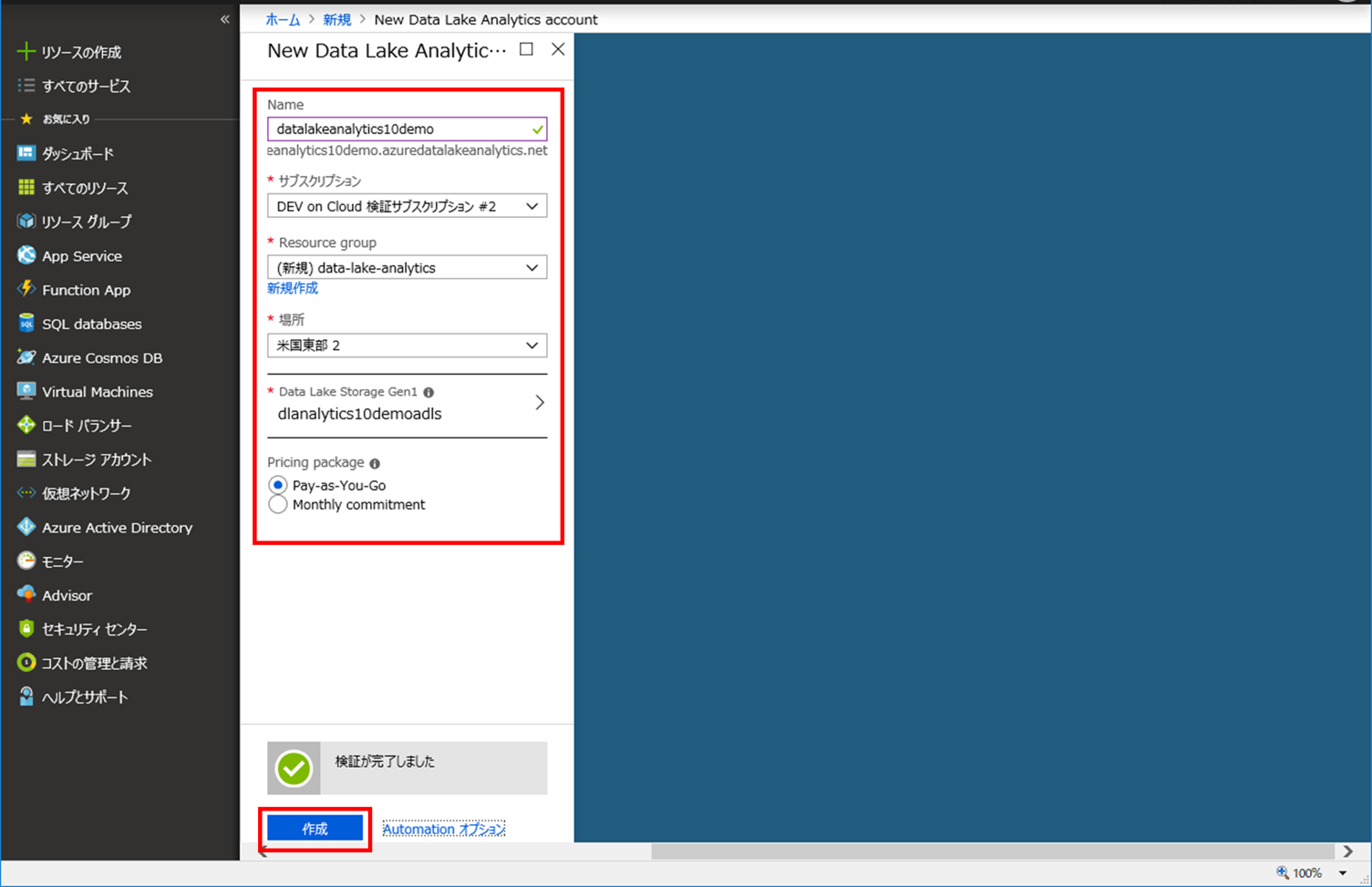
1.U-SQL を書いてみる
まずは簡単な処理から試してみましょう。
(1)作成した Azure Data Lake Analytics を開き、[New job] をクリックします。
![[New job] をクリック](/-/Media/SMC/special/blog/ms-azure_blog/2018/0071/dg05.png)
(2)[Job name] に名前を入れ、U-SQL を入力し [Submit] ボタンをクリックすると、分析が開始されます。
ここで記載した U-SQL は、以下のリンクよりコピーできます。
参考:Azure portal で Azure Data Lake Analytics の使用を開始する
https://docs.microsoft.com/ja-jp/azure/data-lake-analytics/data-lake-analytics-get-started-portal
![[Submit] ボタンをクリックすると、分析が開始](/-/Media/SMC/special/blog/ms-azure_blog/2018/0071/dg06.png)
U-SQL の解説は以下になります。
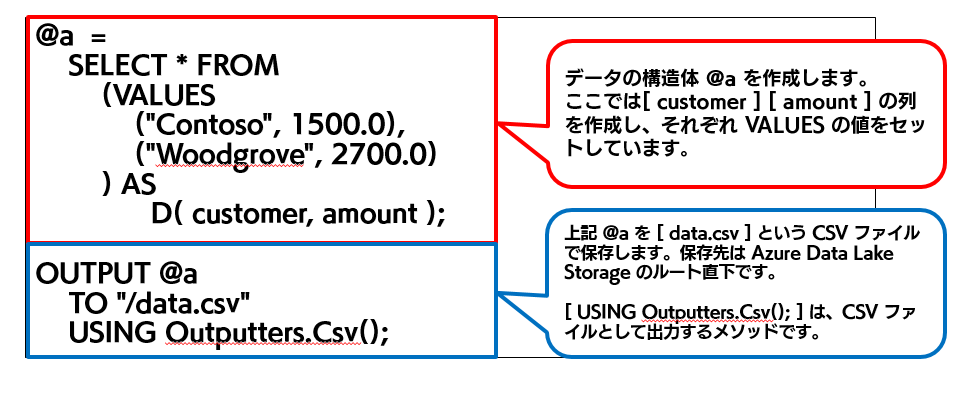
(3)解析が成功すると、以下のような画面が出力されます。
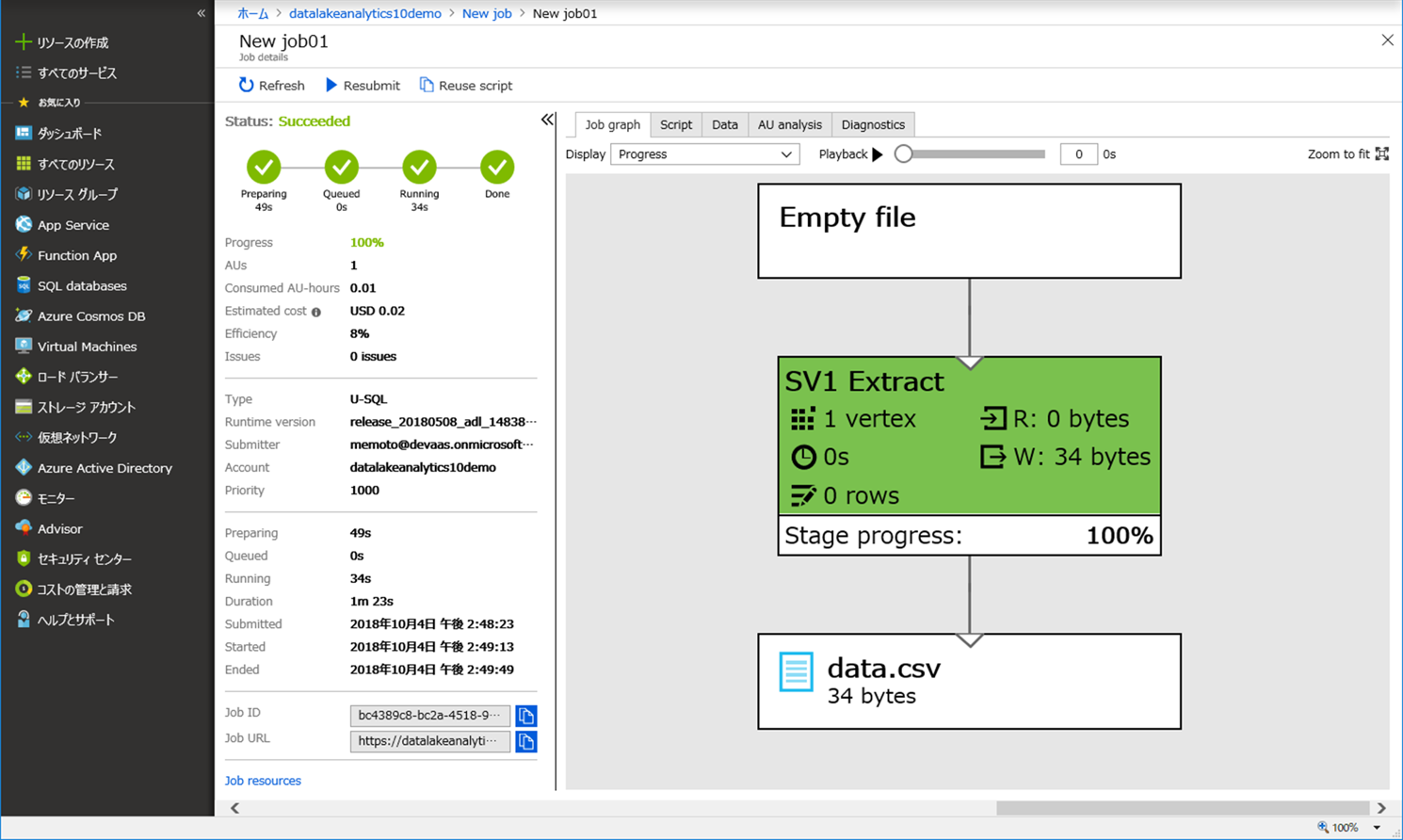
[Data] タブより、インプットデータ、アウトプットデータを確認することもできます。
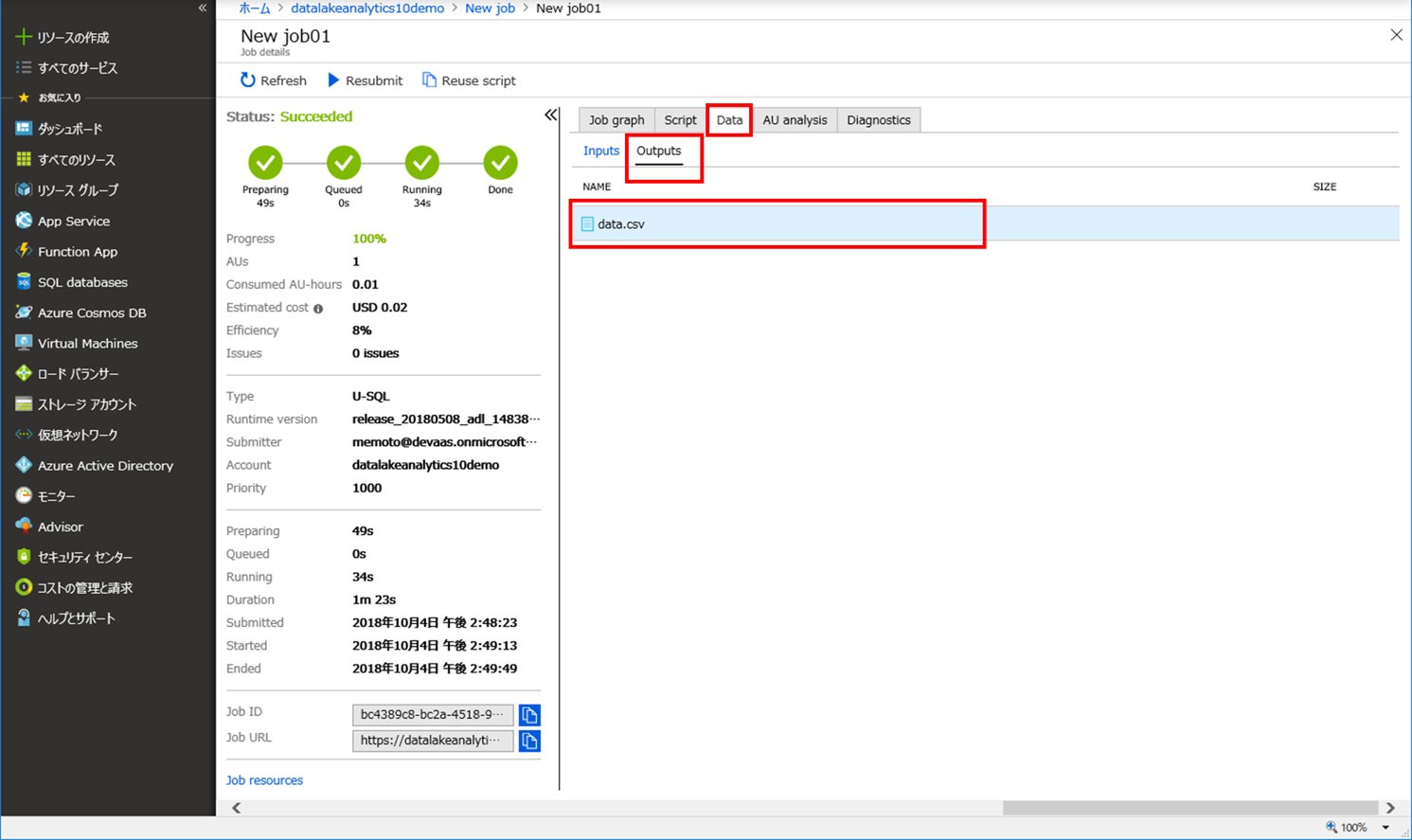
ここでデータをクリックすると、データのプレビューも確認できます。
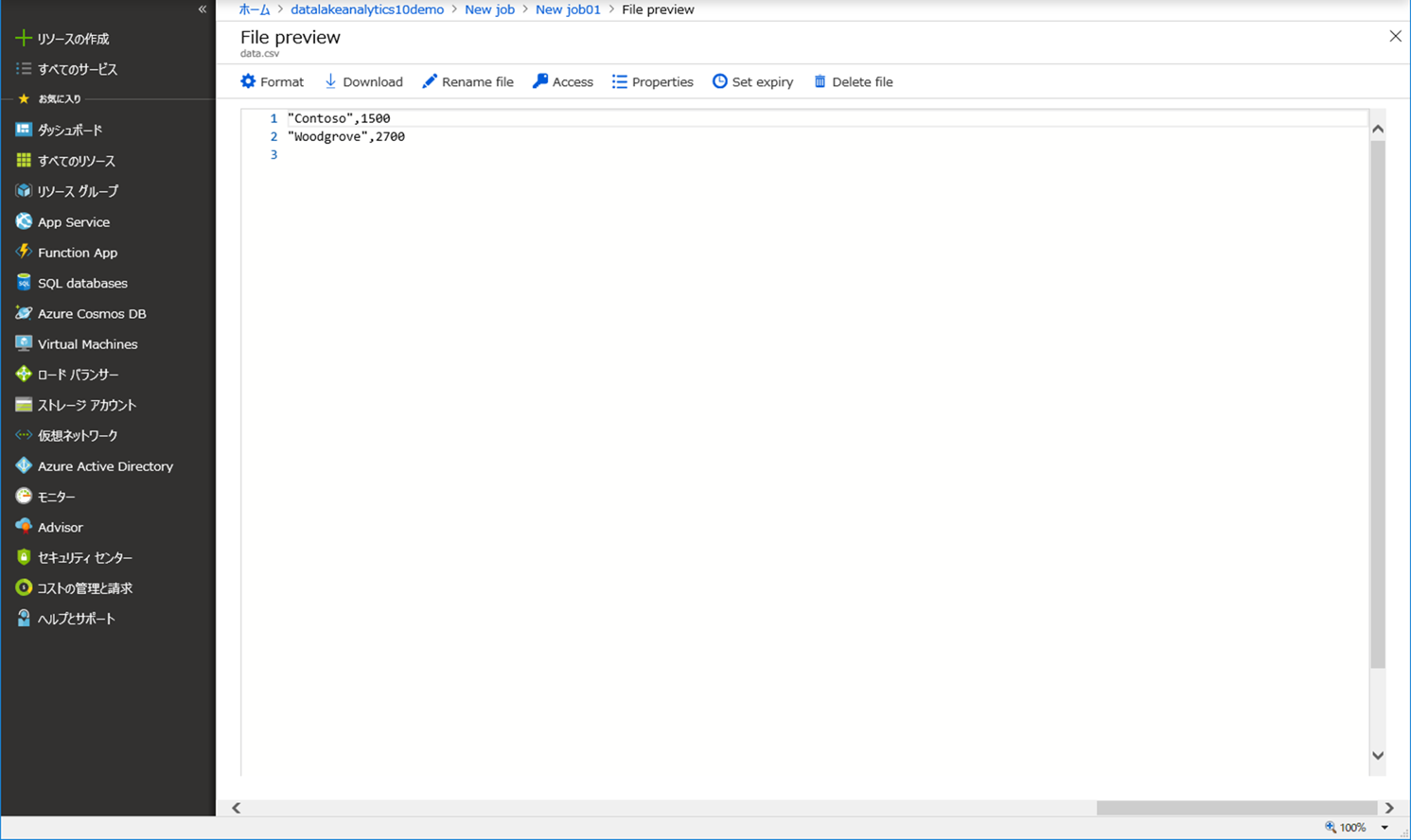
2.住所マスタ CSV ファイルから、特定の住所を抽出してみる
次は、Azure Data Lake Storage に配置した住所マスタ CSV ファイルから、特定の住所のみを抽出し、抽出結果を Azure Data Lake Storage 上の別のファイルに保存することを実施してみます。
ここで言う住所マスタ CSV ファイルとは、郵便番号データのことを指しています。日本郵政のホームページにオープンデータがあるので、そこから取得しました。今回は東京都のみを取得しています。
~以下、前準備となります~
(1)住所マスタ CSV ファイルを Azure Data Lake Storage に配置します。 Azure Data Lake Storage を選択し、[Upload] をクリックします。
![Azure Data Lake Storage を選択し、[Upload] をクリック](/-/Media/SMC/special/blog/ms-azure_blog/2018/0071/dg11.png)
右側のフォルダマークより、住所マスタ CSV ファイルを選択し、[Add selected files] ボタンをクリックします。これで住所マスタ CSV ファイルが Azure Data Lake Storage にアップロードされます。
![住所マスタ CSV ファイルを選択し、[Add selected files] ボタンをクリック](/-/Media/SMC/special/blog/ms-azure_blog/2018/0071/dg12.png)
(2)「1. U-SQL を書いてみる」の(1)で実施した手順と同じく、Azure Data Lake Analytics を開き、[New job] をクリックします。[Job name] に任意の名前を入れ、U-SQL を入力し [Submit] ボタンをクリックすると、解析が実施されます。
![[Job name] に任意の名前を入れ、U-SQL を入力し [Submit] ボタンをクリック](/-/Media/SMC/special/blog/ms-azure_blog/2018/0071/dg13.png)
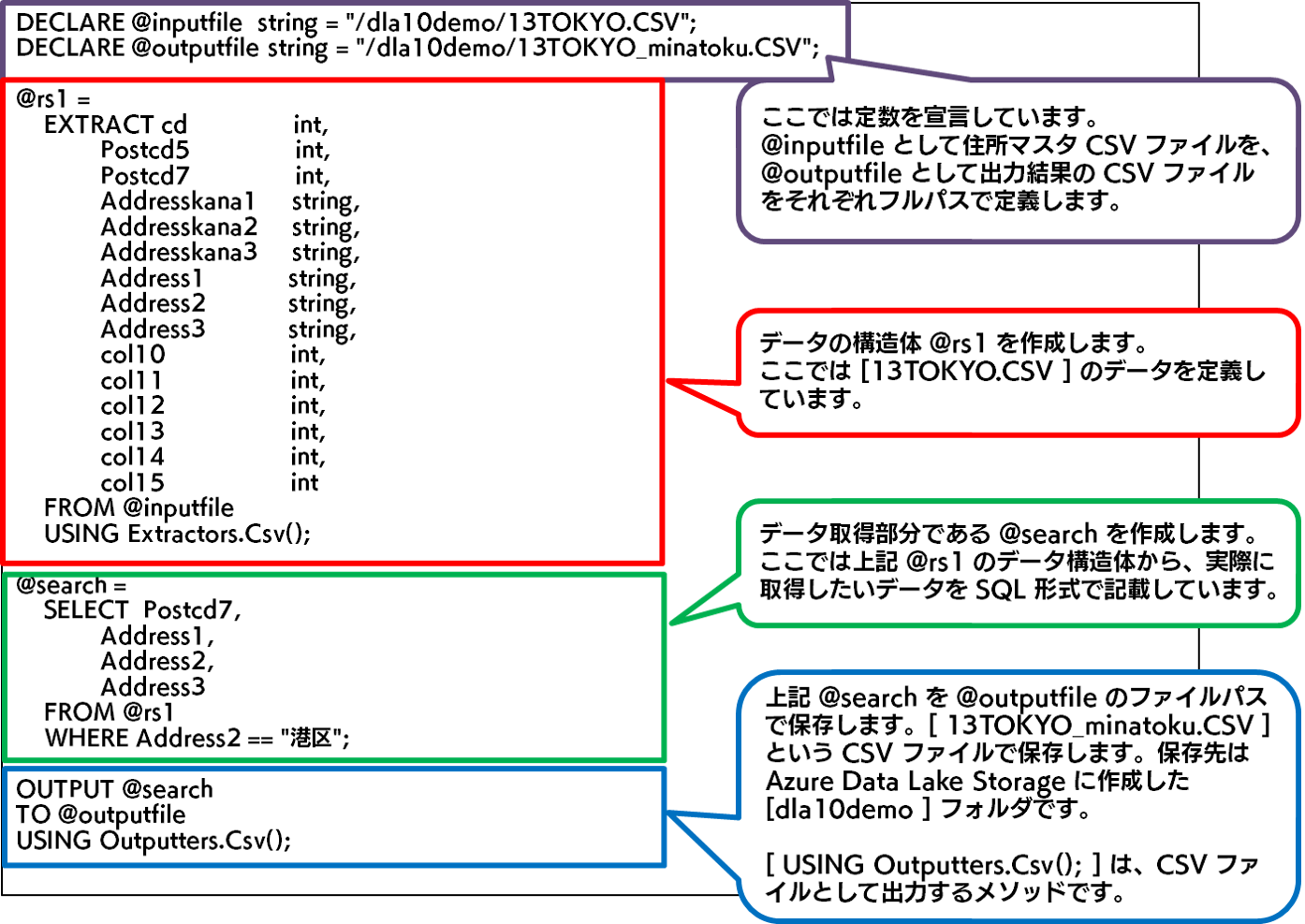
発行する U-SQL は以下です。今回は、住所マスタ CSV ファイルから「港区」のものだけを抽出し、別の CSV ファイルとして出力する処理を実行します。
DECLARE @inputfile string = "/dla10demo/13TOKYO.CSV";
DECLARE @outputfile string = "/dla10demo/13TOKYO_minatoku.CSV";
@rs1 =
EXTRACT cd int,
Postcd5 int,
Postcd7 int,
Addresskana1 string,
Addresskana2 string,
Addresskana3 string,
Address1 string,
Address2 string,
Address3 string,
col10 int,
col11 int,
col12 int,
col13 int,
col14 int,
col15 int
FROM @inputfile
USING Extractors.Csv();
@search =
SELECT Postcd7,
Address1,
Address2,
Address3
FROM @rs1
WHERE Address2 == "港区";
OUTPUT @search
TO @outputfile
USING Outputters.Csv();
今回発行する U-SQL の解説は以下になります。
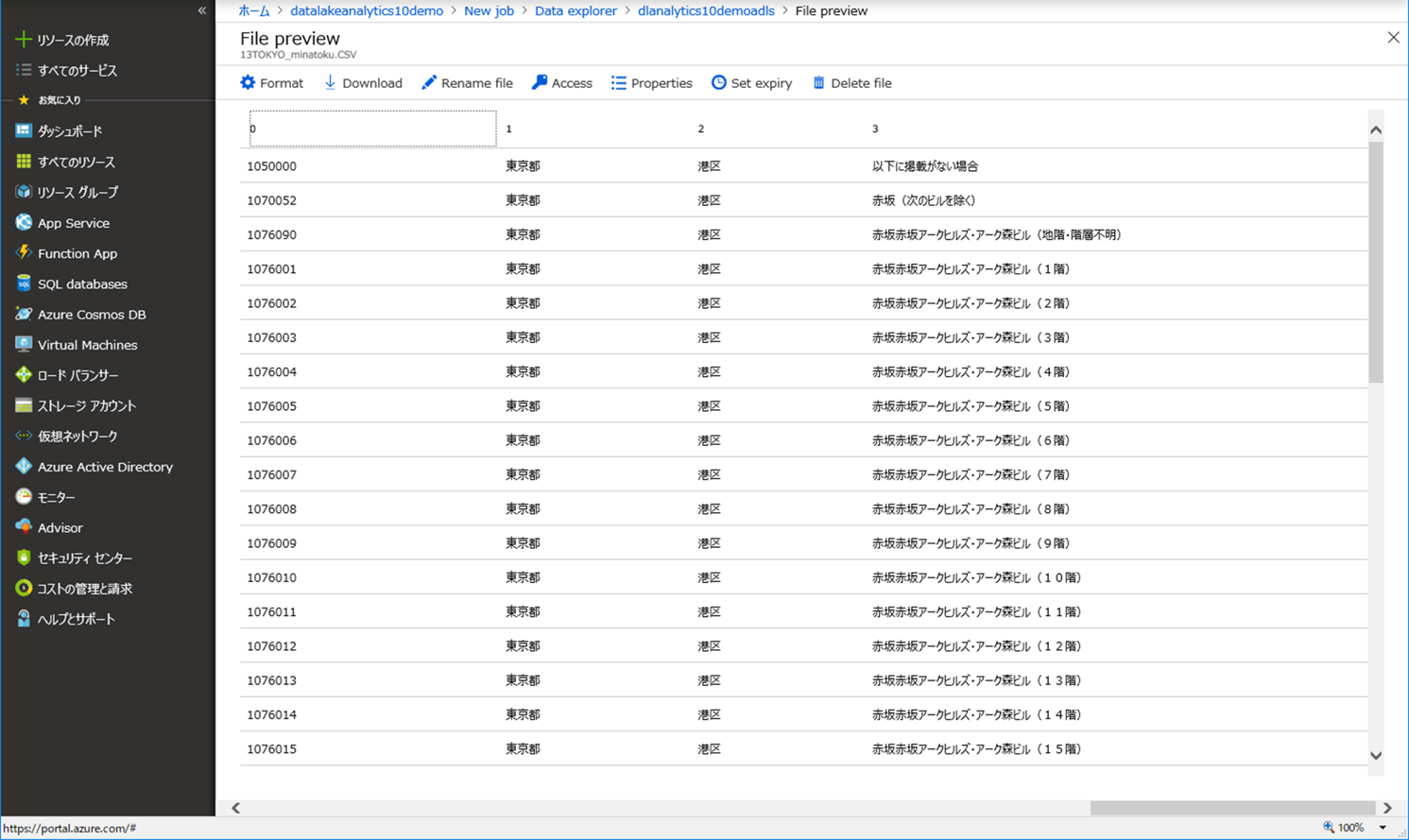
(3)ジョブが成功し、Azure Data Lake Storage を確認すると、別の CSV ファイルが作成されていました。
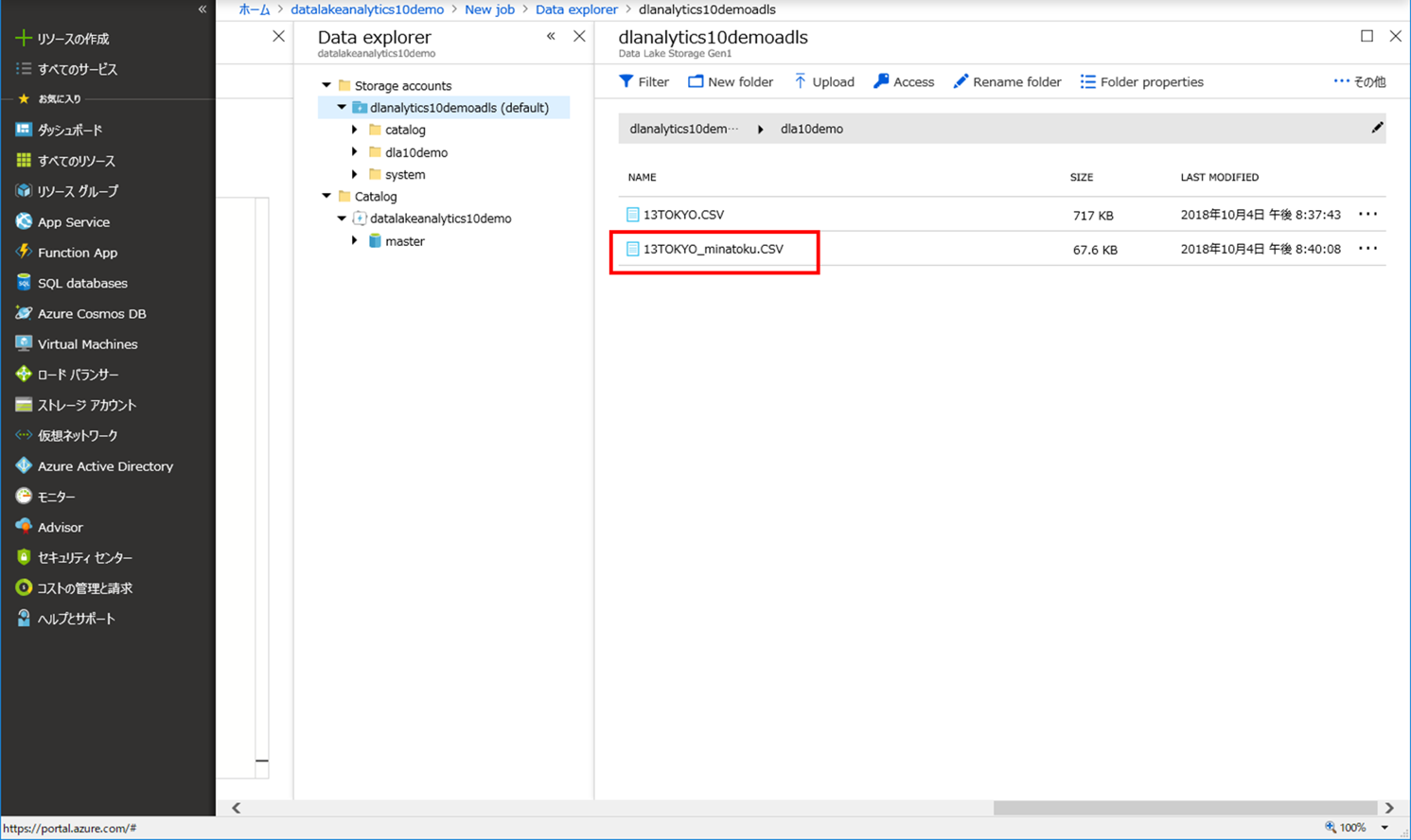
ファイルを選択し中を確認すると、「港区」だけの住所が抽出されています。
今回は Azure ポータル上で U-SQL を実行しましたが、Visual Studio や Visual Studio Code を使用して C# 等のカスタム開発も可能です。
残念ながら、現時点で日本リージョンでのサービスは開始されていないのですが、ジョブの実行にかかった時間分課金される分析サービスという点は興味深いです。
全ての Azure データに対応している点も魅力的です。解析したいデータを下記のいずれかに格納しておけば、Azure Data Lake Analytics で解析が可能となります。
<解析したいデータの格納場所>
今回、ビッグデータというほど大きなデータを使用していないのですが、U-SQL を発行し、処理が完了するまでかなり時間を要したように感じました。
Azure Data Lake Analytics は大容量のデータ分析に強い、という触れ込みなので、TB 級のデータを解析した際にどれぐらいのパフォーマンスが出るのかは気になります。
Azure Data Lake Analytics については、以下のリンクが参考になりました。具体的な手順や U-SQL 等のリファレンスも記載されていますので、もし興味があれば参考にして Azure Data Lake Analytics を触ってみてください。




