こんにちは。データサイエンスチームの大山です。
前回の記事(以下リンク先)では、Azure ML デザイナー で時系列データの異常検知を行うにあたり、必要となる前提知識について解説しました(前回の解説した内容 : Azure ML デザイナー の概要、異常検知技術の概要、主成分分析による異常検知手法の説明、異常検知を時系列データに適用する方法)。
後編にあたる本記事では、前編で解説した知識を利用して、実際に Azure ML デザイナー で時系列データの異常検知を行う手順について解説していきます。
また、当社が提供する機械学習サービス ML Connect - Anomaly Detection では、Azure ML の機能を活用し、主にIoT 分野向けに時系列データの異常検知機能の提供をしています。そのため、ML Connect - Anomaly Detection の特徴や Azure ML を活用したことによる利点などについても本記事の最後に解説できればと思います。
【注意】 本記事は 2022年4月から5月上旬における、Azure ML スタジオのユーザーインターフェースを前提に解説しています。ただしその後、2022年5月下旬にかけて、Azure ML スタジオのユーザーインターフェースに改変が入り、特に今回説明するデザイナーの操作やインターフェースについて、本記事で解説している内容と差異が生じています(例えば、コンポーネントを選択するメニュー部分や、コンポーネントの設定を開く際に、これまでは左クリックのみで開いていましたが、ダブルクリックが必要になるなど、細かい部分に差異があります。また、これまで「実験(Experiment)」と呼ばれていた概念が「ジョブ(Job)」に名称が変更されています)。
それでは初めに、Azure ML デザイナー でデータを分析する際に必要となる準備について、解説していきたいと思います。
なお、Azure ML のリソースの作成や Azure ML スタジオ へのアクセス方法については、本記事での説明は行いません。Azure ML、およびとそれに付随して作成される各リソース : Storage Account、Container Registry、Key Vault、Application Insights、については、すでに作成済みであることを前提として解説していきます。
もし Azure ML のリソース作成や、Azure ML スタジオ へのアクセス方法について詳細を知りたい場合は、以下の Azure 公式チュートリアルページの「ワークスペースを作成する」の節を参照してください
Azure ML デザイナー でデータを利用するには、分析に使用するデータ(前編の記事で説明した正常データ、および異常を含むデータ、それぞれ2,000行分)について、Azure ML のデータセットにアップロードして登録する必要があります。以下の手順に従って、正常データ、および異常を含むデータを Azure ML のデータセットに登録してください。
1. 使用するデータをローカル PC にダウンロードする : 本記事では、前回の記事で説明した、正弦波 + 正規分布のノイズによって生成したデータを使っていきます。以下のリンクから、それらデータの CSV ファイルがダウンロードできますので、まずはこれらのデータをローカル PC の任意の作業用フォルダにダウンロードしてください。
2. Azure ML の データセットの管理画面を開く : Azure ML スタジオ の左側のメニュー項目から [データセット] を選択し、データセットの管理画面に移動してください
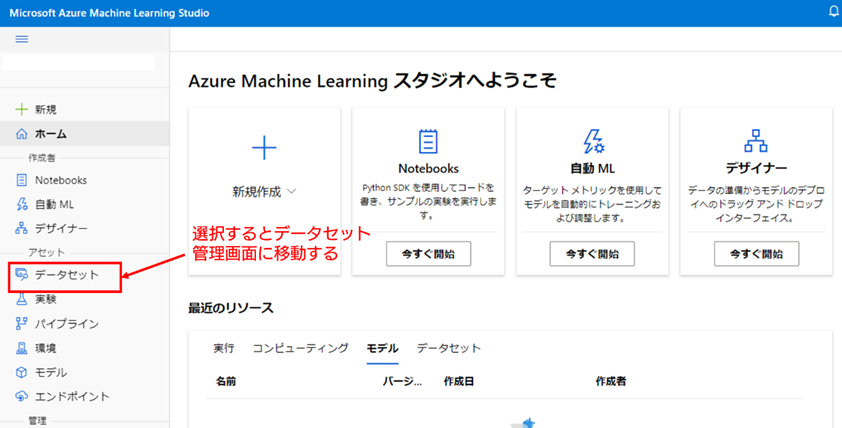
3. 正常データについて、データセットの新規作成を開始する : まずは、正常データからデータセットに登録していきます。[データセットの作成] のプルダウンを左クリックし、[ローカルファイルから] を選択して、データセットの登録画面を開いてください。
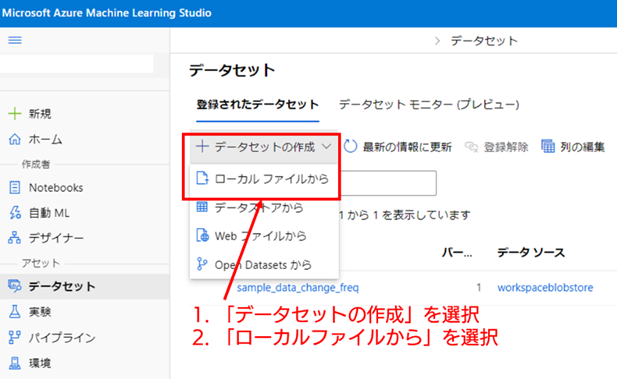
4. データセットの基本情報を入力する : データセットの新規作成画面では、初めに基本情報の入力を行います。[名前] と [データセットの種類] は必須項目です。ここでは正常データの登録を行うため、[名前] を「sine_wave_normal」と設定したとして説明していきます。なお、データセットの種類は、「表形式」から変えないで問題ありません。必須項目の入力が完了したら、[次へ] を選択してください。
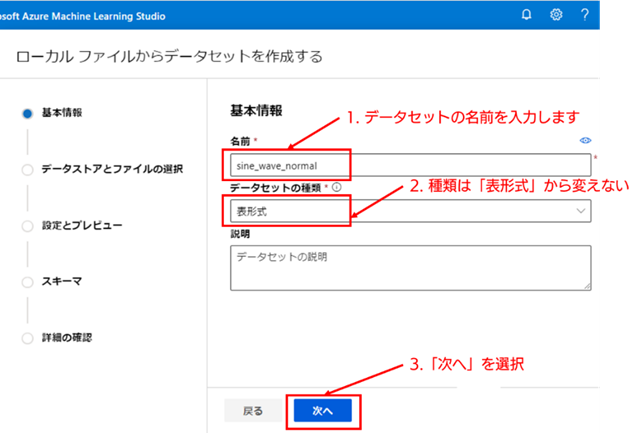
5. アップロードするローカル PC のファイルを選択する : [データストアとファイルの選択] 画面では、[参照] 項目のプルダウンを左クリックし、[ファイルの参照] を選択してください。選択すると、ローカル PC のファイルを選択するウィンドウが開くので、アップロード対象の正常データの CSV ファイル(data_change_freq_normal.csv)を選択してください。
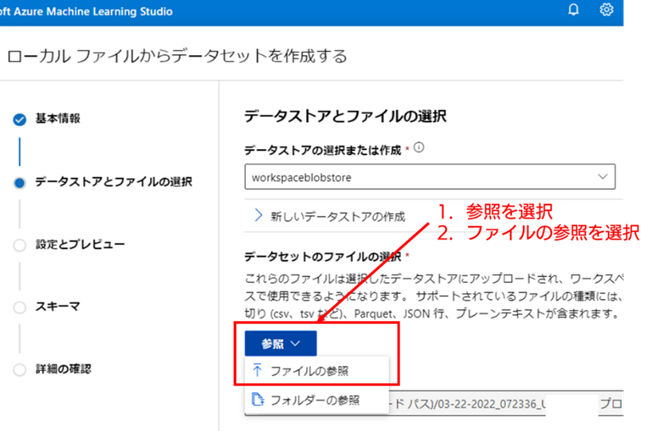
6. 選択したローカル PC のファイルをアップロードする : アップロードするローカルファイルを選択すると、[ファイル名] の下部に選択したファイルの名前が表示されます。表示されているファイルが正しければ、[次へ] を選択してファイルのアップロードを行ってください。
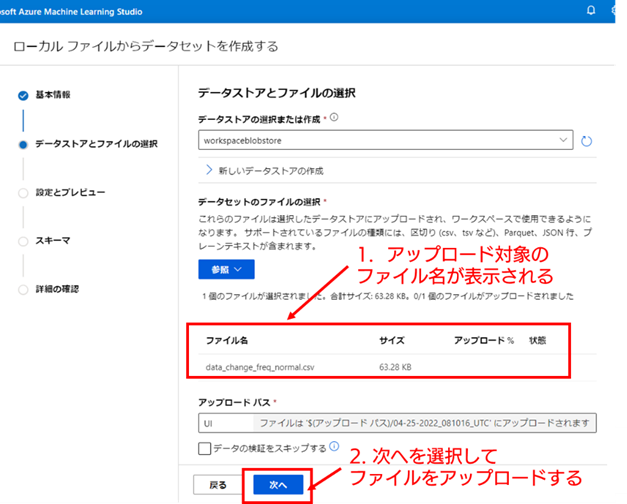
7. 設定とプレビューの確認 : ファイルをアップロードすると [設定とプレビュー] 画面に移動し、アップロードした CSV ファイルのサンプルがページ下部に表示されます。CSV ファイルの列名やデータの形式が意図した状態になっているか確認し、問題なければ [次へ] を選択してください。それ以外の設定項目については、今回は変更しないで問題ありません。
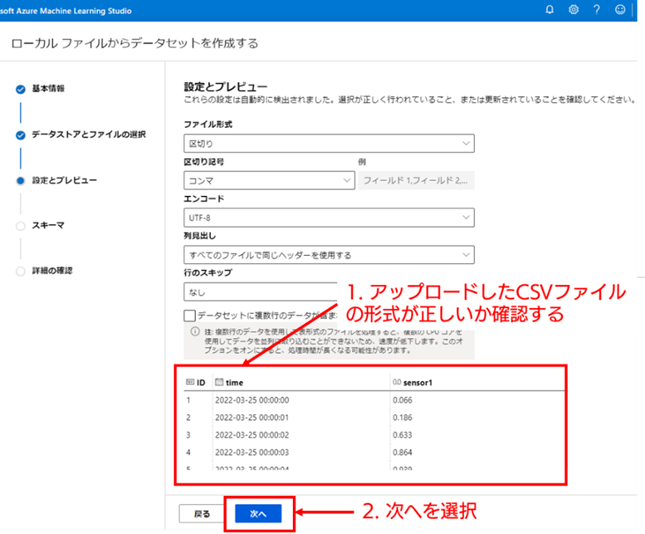
8. スキーマの確認 : [スキーマの設定] 画面では、データの各列についてデータセットに含めるかどうかや、列それぞれのデータ型を指定することができます。データ型については Azure ML がある程度推定してくれるため、今回は初期値のまま、特に変更しないで問題ありません。[次へ] を選択して次の画面に進んでください。
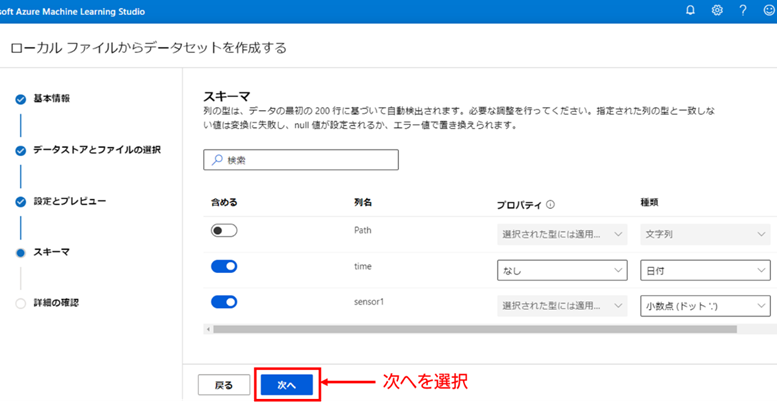
9. 詳細の確認 :「詳細の確認」画面では、これまで入力した各設定の設定値が表示されます。設定値が意図した値になっていることを確認したら、[作成] を選択してデータセットの登録を完了してください。
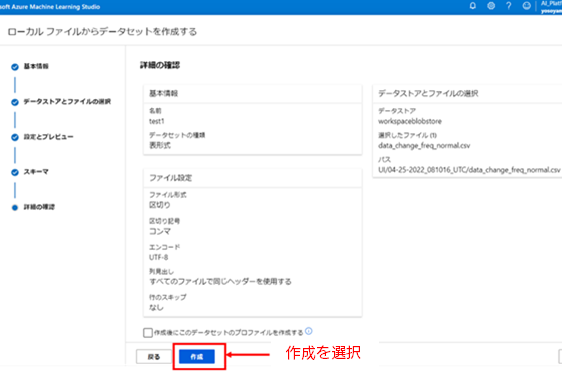
10. データセットの登録完了 : データセットへの登録が完了すると、データセットの管理画面が表示され、登録したデータセットの [名前] がデータセットの一覧に表示されます。
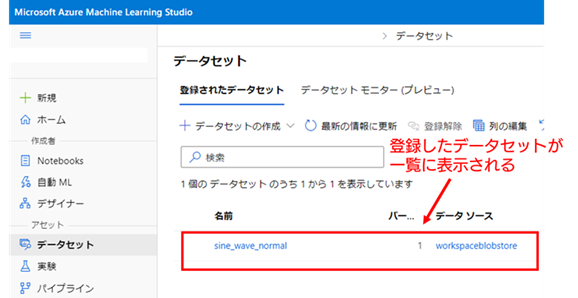
これで学習用の正常データの登録は完了です。検証用の異常を含むデータ(data_change_freq_anomaly.csv)についても全く同様の手順で登録してください。なお、異常を含むデータの名称は「sine_wave_anomaly」と登録したとして以降は説明していきます。
Azure ML デザイナー を利用するには、その処理を実行するためのコンピューティングリソースが必要になります。今回は、コンピューティング クラスターと呼ばれる、複数の仮想マシン(Virtual Machine : VM)で並列計算が可能な Azure ML 管理のコンピューティングリソースを利用します。
それでは、以下の手順でコンピューティング クラスターの作成をしていきます。
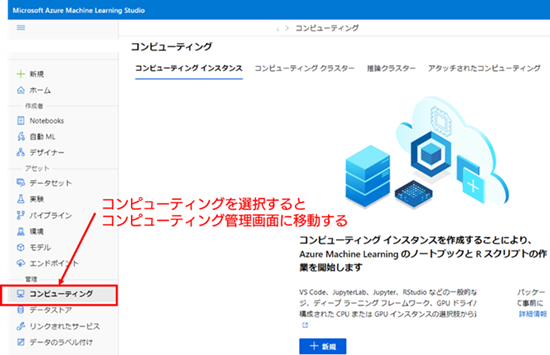
1. コンピューティング管理画面への移動 : Azure ML ではコンピューティングリソースの管理(コンピューティングリソースの新規作成、起動・停止、削除、ノード数の変更など)をコンピューティングの管理画面で行うことができます。Azure ML スタジオ の左側のメニュー項目から [コンピューティング] を選択し、コンピューティングの管理画面に移動してください。
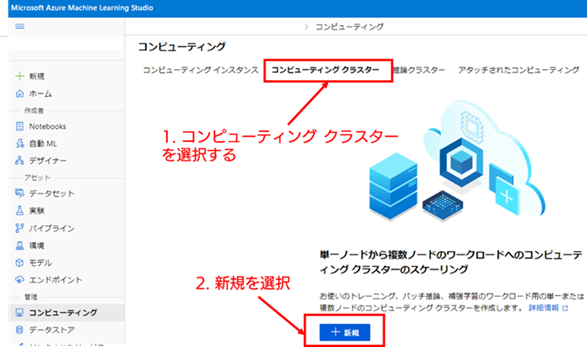
2. コンピューティング クラスターの新規作成を開始する : コンピューティング クラスターの管理画面に移動するため、画面の上側にある [コンピューティング クラスター] のタブを選択してください。画面が遷移すると、コンピューティング クラスターがまだ作成されていない場合、画面の下側に [新規] ボタンがあります。このボタンを選択して、コンピューティング クラスターの新規作成画面を表示してください。
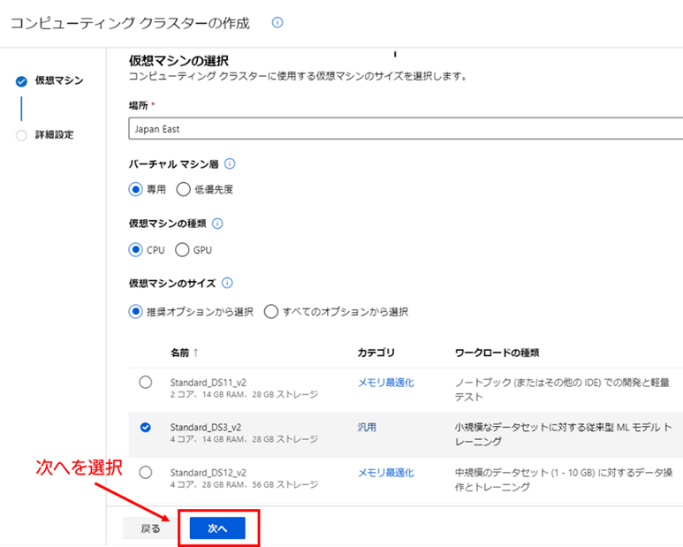
3. コンピューティング クラスターで使用する VM の設定 : 新規作成を開始すると、コンピューティング クラスターで使用する VM に関する設定画面が開きます。今回は初期値に指定されている設定値(場所(リージョン): Japan East、バーチャルマシン層 : 専用、仮想マシンの種類 : CPU、仮想マシンのサイズ : Standard_DS3_v2 )をそのまま使用します。設定値が合っているか確認したら、[次へ] を選択してください。
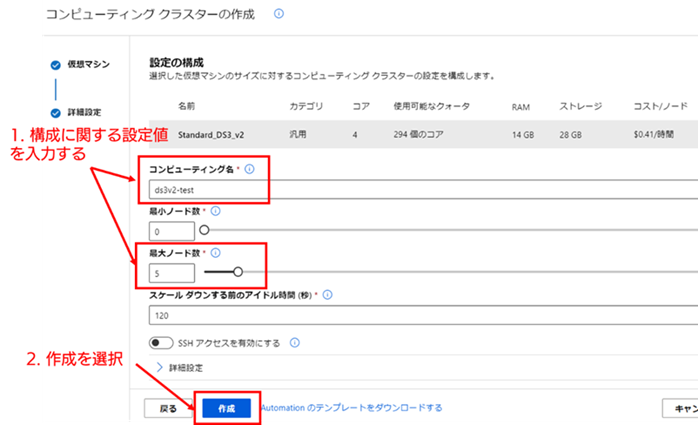
4. コンピューティング クラスターの構成に関する設定 : 次に表示される [設定の構成] 画面では、コンピューティング クラスターの名称や最小、最大ノード数、スケールダウンに関する設定が行えます。今回は、[コンピューティング名] と [最大ノード数] のみ初期値から変更します。それぞれ、以下の設定値を指定したとして、以降は解説していきます。
設定が終わったら、画面下の [作成] を選択してください。コンピューティング クラスターの作成処理が開始されます。
5. コンピューティング クラスターの作成が完了したことを確認する : [作成] を選択すると、コンピューティング クラスターの管理画面に画面が移動し、画面上の一覧に現在作成したコンピューティング クラスターの情報が表示されます。コンピューティング クラスターの作成が完了すると、[状態] の値が [成功しました] に変わりますので、それまで待機してください。
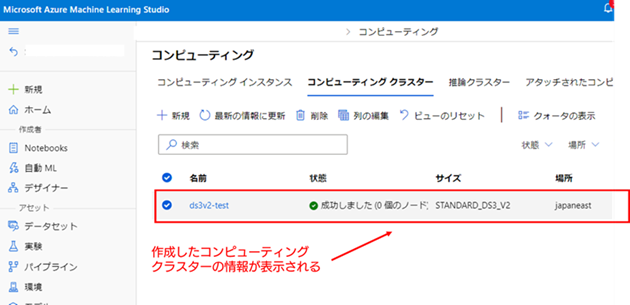
コンピューティング クラスターの作成まで完了したら、Azure ML デザイナー を使用する準備は完了です。次の節では、登録したデータセットと作成したコンピューティング クラスターを使い、時系列データの異常検知を Azure ML デザイナー で実際に行っていきたいと思います。
それでは、Azure ML デザイナー を使って、主成分分析による異常検知モデルを構築し、そのモデルを使って、異常を含む時系列データの異常部分の検知が、実際にできるかどうか検証していきたいと思います。
まずは、異常検知モデルの学習用のパイプラインの構築から行います。なお、Azure ML デザイナー では、学習用のパイプラインをトレーニング パイプラインと呼んでいるため、以降の説明ではそれに合わせて、トレーニング パイプラインと呼んでいきます。
1. Azure ML デザイナー へのアクセス : Azure ML スタジオ の左側のメニューから デザイナー を選択します(もしくは、ホーム画面のデザイナー下部の「今すぐ開始」を選択)。
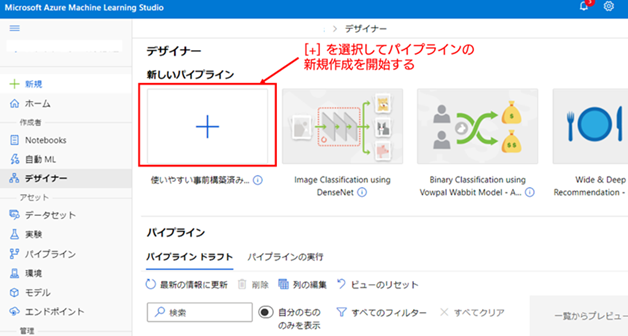
2. 新しいパイプラインの作成を開始する : Azure ML デザイナーの管理画面に移動したら、左上側の [新しいパイプライン] の項目の下にある [+] の項目を選択して、パイプラインの新規作成を開始します。
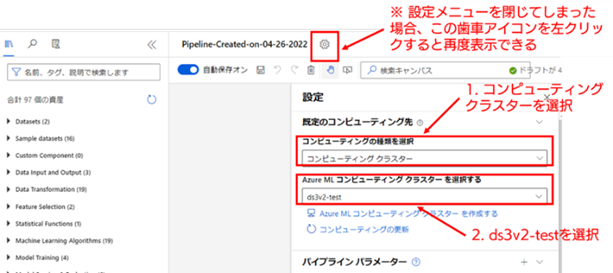
3. 既定のコンピューティング先を設定する : パイプラインの新規作成を開始すると、画面がトレーニング パイプラインの作成画面に移ります。この際、画面の右側に [設定] のメニューが表示されます。この設定メニューでは、パイプラインで使用する計算リソースの設定や、パイプライン(正確には後述するパイプライン ドラフト)の名称を変更することができます。今回は、事前に作成したコンピューティング クラスターを利用するため、[既定のコンピューティング先の設定] を以下の値に設定してください(本設定では、項目のプルダウンを選択すると、選択可能な設定が表示されるので、その中から指定したい設定を選択してください)。
なお、[設定]のメニューは、メニュー外部を左クリックしてしまうと閉じてしまいますが、画面上部の歯車のアイコンを選択すると再度表示することができます。
4. パイプライン ドラフトの名称を設定する : 作成するパイプラインの名称を設定します。名称は [設定] メニューを下にスクロールすると表示される [ドラフトの名称] から変更することができます。ここでは名称を「anomaly-detection-training-pipeline」と設定したとして、以降は説明していきます。
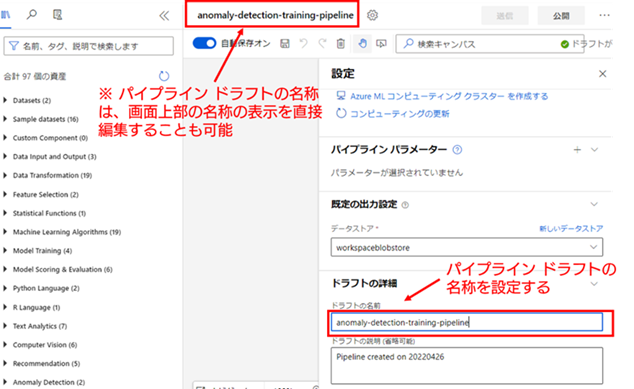
パイプライン ドラフト全体の設定が完了したら、[設定] メニュー以外の画面を左クリックして、[設定] メニューを閉じてください。そうすると、キャンバス(グレーの背景部分)の部分が広く表示されます。パイプライン ドラフトの構築は、このキャンバスの上に、処理が定義されたコンポーネントを左側の [資産] のメニューから選択して配置し、それらコンポーネント同士を連結することで構築していきます。
5. Azure ML デザイナーの基本操作の説明 : それでは、Azure ML デザイナー の操作方法について、学習用のデータセット(sine_wave_normal)の配置、および列を抽出するコンポーネント([Select Columns in Dataset])の配置、そしてその両者を連結する操作の手順を通して説明します。
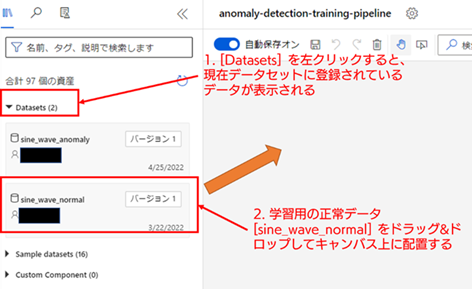
【学習用の正常データセットの配置】 [資産] メニューの [Datasets] を選択してください。[Datasets] を選択すると、登録されているデータセットのコンポーネントが一覧として表示されます。ここでは、学習用データセット(sine_wave_normal)をキャンバス上に配置します。コンポーネントをキャンバス上へ配置するには、配置したいコンポーネントをドラッグ & ドロップして、キャンバス上に移動させることで配置することができます。
正常にデータセットのコンポーネントが配置された後の図が以下となります。
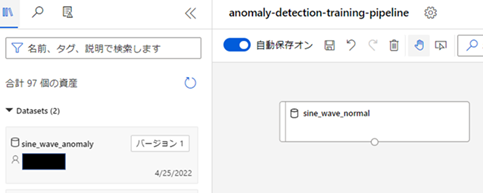
他のコンポーネントについても、今操作した方法と同様に、[資産] メニューから配置したいコンポーネントを探し、それをキャンバス上にドラック & ドロップすることで配置を行うことができます。
【列を抽出するコンポーネントの配置】 次に異常検知の対象とする列(sensor1 列)だけをデータから抜き出すために、列を抽出する処理 [Select Columns in Dataset] を配置して、データセットと連結する方法を説明します。
[Select Columns in Dataset] は、[Data Transformation] に属するので、そこから [Select Columns in Dataset] を探して、キャンバス上に配置してください(なお、資産メニュー上部の「名前、タグ、説明で検索します」と書かれている検索欄に探したいコンポーネント名を入力することでも探すことができます)。
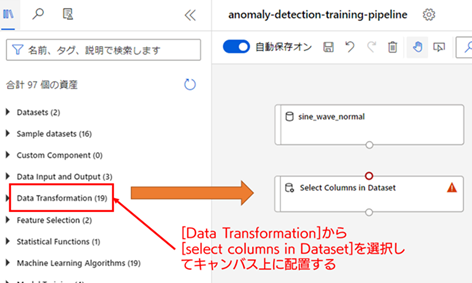
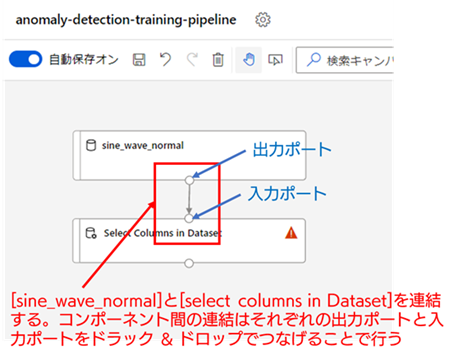
[Select Columns in Dataset] が配置できたら、[sine_wave_normal] と [Select Columns in Dataset] を連結します。コンポーネント間の連結は、それぞれの出力ポート(コンポーネントの下部の白丸部分)と入力ポート(コンポーネント上部の白丸部分)をドラック & ドロップで接続することで行います。
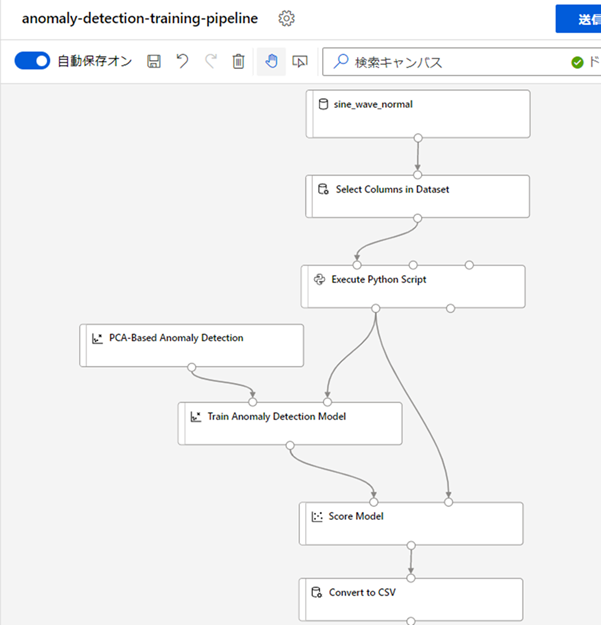
6. トレーニングパイプラインに必要なコンポーネントを全て配置して連結する : コンポーネントの配置と連結方法の説明を行ったので、次は今回トレーニングパイプラインで使用する全てのコンポーネントについて、全てキャンバス上に配置し連結してしまおうと思います。以下に記載するコンポーネントを、画像に記載する順番に従って、配置と連結を行ってください(特に、入出力のポートの位置に気を付けてください)。
各コンポーネントの連結を行ったら、次はコンポーネントそれぞれについて必要な設定を行っていきます。コンポーネントの設定の変更は、対象のコンポーネントを選択すると画面右端に表示される、設定変更メニューから行うことができます。
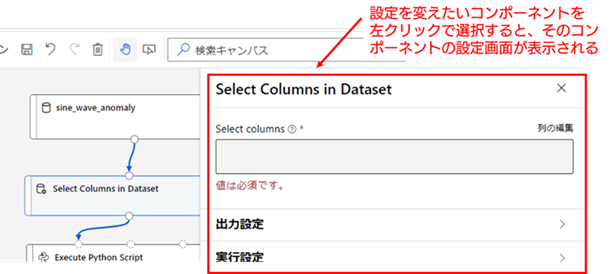
以降の手順では、以下のコンポーネントについて設定を変更していきます。
7. [Select Columns in Dataset] の設定 : まずは、[Select Columns in Dataset] について、抽出する列を選択します。抽出する列の選択は [Select Columns in Dataset] の設定メニューを開き、[Select columns] の項目の「列の変更」から行います。
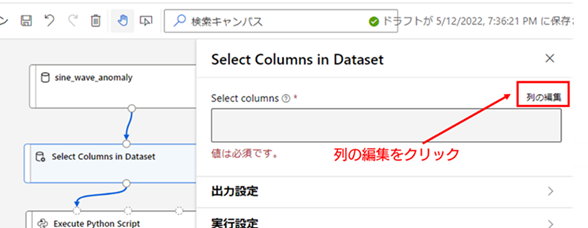
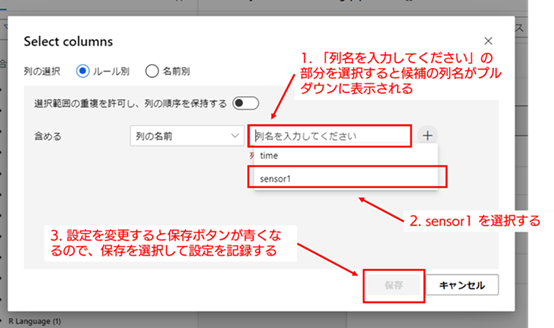
「列の変更」を選択すると、以下の画像の様に「Select columns」の設定メニュー画面が表示されます。「列名を入力してください」の項目を選択すると、「time」、「sensor1」の2列がプルダウンに表示されるので、その内「sensor1」だけを選択してください。列を選択すると、メニュー右下の「保存」ボタンが青色になり選択できる様になるので、「保存」を選択して変更した設定を確定してください。
設定が保存されると、以下の画像の様に「Select columns」の項目が「列の名前 sensor1」と表示されます。
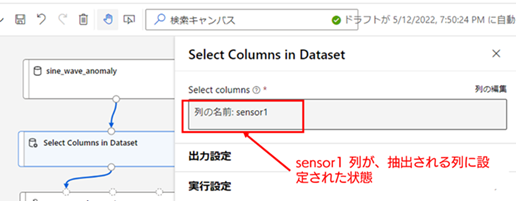
以上で、[Select Columns in Dataset] の設定は完了です。
8. [Execute Python Script] の設定 : 前回の記事で説明した部分時系列化の処理は、Azure ML デザイナーのコンポーネントには存在していません。そのため、この部分だけはプログラムを使った処理が必要になります。今回は、Python で記述された処理が実行できる [Execute Python Script] を利用して、部分時系列化の処理を行います。
まずは、配置した [Execute Python Script] の設定メニューを開いてください。メニューを表示すると、「Python script」の項目以下にテンプレート用の Python のコードが書かれているかと思います。
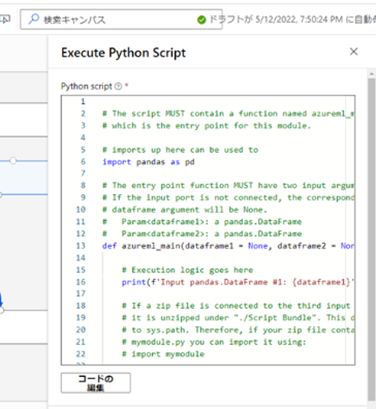
今回はこのテンプレートを使用しないため、一旦全て削除してしまいます。メモ帳などと同じ様に書き換え可能なので、例えば、CTRL + A で全選択し、Delete キーで全削除してください。
削除したら、[Python script] の領域に、以下の部分時系列化を行う Python スクリプトをコピーして貼り付けてください。
# The script MUST contain a function named azureml_main
# which is the entry point for this module.
# imports up here can be used to
import pandas as pd
import numpy as np
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be None.
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None):
#### parameters ####
window_size = 24 # window size
####################
# Execution logic goes here
##### 部分時系列変換
# ※出力形式がpd.DataFrame に固定されているので、入力データは1次元時系列データのみ対応
partial_ts_array = transform_partial_timeseries_vector(dataframe1, window_size, axis=0)
# 出力は pdandas.DataFrame である必要があるため、numpy array -> pd.DataFrameに変換
output_df = pd.DataFrame(partial_ts_array[:,:,0])
# Return value must be of a sequence of pandas.DataFrame
return output_df,
### 部分時系列ベクトルを作る関数
# X_df: 元の入力データ 2次元Dataframe
# window: window size
def transform_partial_timeseries_vector(X_df, window, axis=0):
lst = X_df.values
x_out_l = []
x_out_l_append = x_out_l.append
for i in range(lst.shape[axis] - window + 1):
tmp = lst[i:i+window]
x_out_l_append(tmp)
x_out_array = np.array(x_out_l)# numpy array
return x_out_array
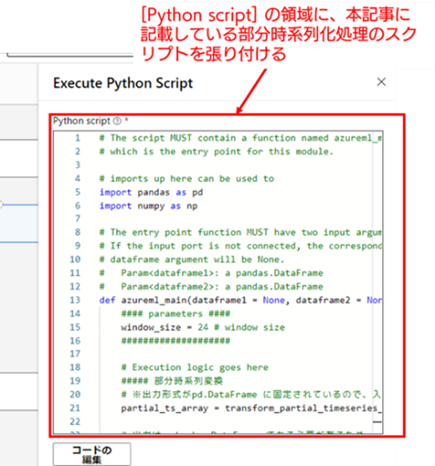
上記のコードを入力した状態が以下の画像となります(特に保存ボタンなどを押す必要はなく、書き換えるだけで設定は保持されます)。これで、部分時系列化処理を行うための [Execute Python Script] の設定が完了です。
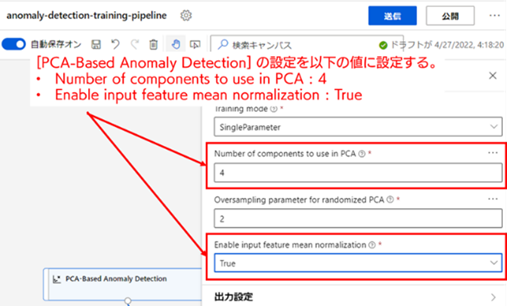
9. [PCA-Based Anomaly Detection] の設定 : それでは次に、主成分分析による異常検知モデルを定義している [PCA-Based Anomaly Detection] の設定を変更していきます。設定メニューを開いたら、以下の設定値について、記載している値に変更してください。
1 つめの「Number of components to use in PCA」の設定値は、主成分分析で次元削減した後の主部分空間の次元の数です。この設定の場合、元の24次元空間(部分時系列の長さ)の入力データを4次元の空間に次元削減するということを示しています。
また、「Enable input feature mean normalization」の設定は、データの正規化処理を実行するかどうかを指定する設定値です。正規化とはデータのスケールの変化などを行い、数値的に取り扱いやすくする処理のことです。正規化には複数の種類がありますが、Azure ML デザイナー の [PCA-Based Anomaly Detection] の場合、平均正規化(列ごとにデータの平均値を引いた後、列ごとの最大値 と最小値の差で割るスケーリング処理)が実行されます。
これで [PCA-Based Anomaly Detection] の設定も完了です(こちらも、特に保存ボタンなどを押す必要はなく、書き換えるだけで設定は保持されます)。
以上で全てのコンポーネントの設定が終わりました。これで、トレーニング用のパイプライン ドラフトの構築は完了です。次はついに、構築したパイプライン ドラフトを元にして、異常検知モデルの学習を実行していきます。
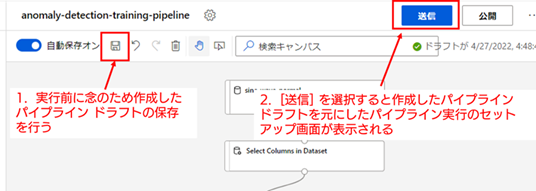
10. 異常検知モデルの学習の実行 : 実行の前に、一度作成したパイプライン ドラフトの保存を行ってください(キャンバスの左上辺りにある保存アイコンで保存できます。なお、自動保存がオンであれば自動で進捗が保存されているため、あくまで念のための操作ということになります)。
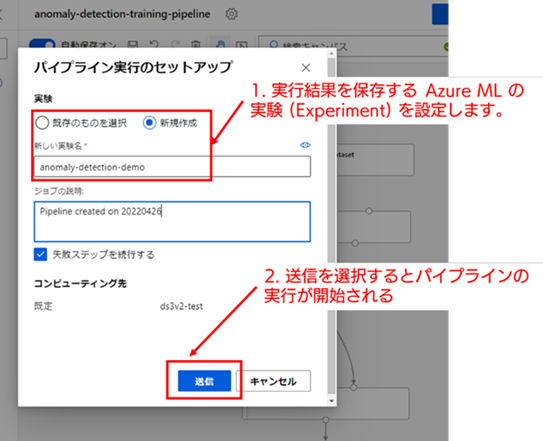
それでは、構築したパイプライン ドラフトをトレーニング パイプラインとして実行します。キャンバスの右上にある、[送信] ボタンを選択すると、パイプライン実行のセットアップ画面が表示されます。
パイプライン実行のセットアップ画面では、パイプラインの実行結果を保存するための Azure ML の実験(Experiment)を指定する必要があります。今回は初めての実行なので、[新規作成] を選択します。ここでは、実験の名称を「anomaly-detection-demo」とします。実験の名称を [新しい実験名] に入力してください。
実験の指定が終わったら、トレーニング パイプラインの実行準備は完了です。送信を選択して、トレーニング パイプラインの実行を開始してください。
パイプラインの実行が開始されると、上側に配置されたコンポーネントから順番に処理が行われていきます。この処理には、コンピューティング クラスターの起動時間やコンポーネントごとの計算処理にある程度時間がかかります。全てのコンポーネントの実行が完了するまで、しばらく待機してください(今回のデータは、あまり大きなデータではないので、数分程度で全ての処理が完了するかと思います)。
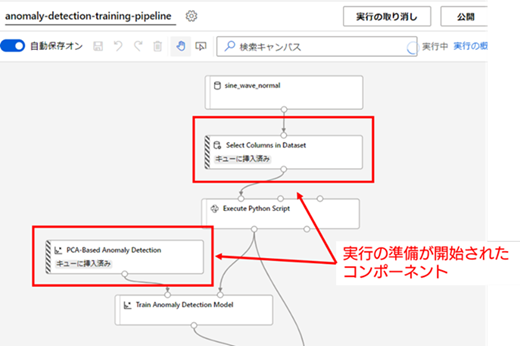
コンポーネントの実行が完了すると、左端が緑色に変わります。データセット以外の全てのコンポーネントの実行が完了したら、トレーニング パイプラインの実行は完了です。
11. 学習用データに対する異常検知結果の確認 : それでは、学習用データに対して、異常検知モデルの推論結果がどの様になっているか確認してみましょう。異常検知モデルによる推論結果を Azure ML デザイナー上で確認するには、[Score Model] の出力ポートを「右クリック」して表示されるメニューから「データを表示する」を選択してください。
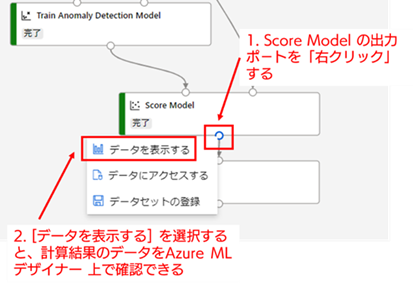
データを表示すると、入力データ列(部分時系列化したデータ)と、その右端に異常検知の計算結果の列が追加されたテーブルが表示されます(右端まで画面に入っていないと思うので、右端までスクロールしてください)。
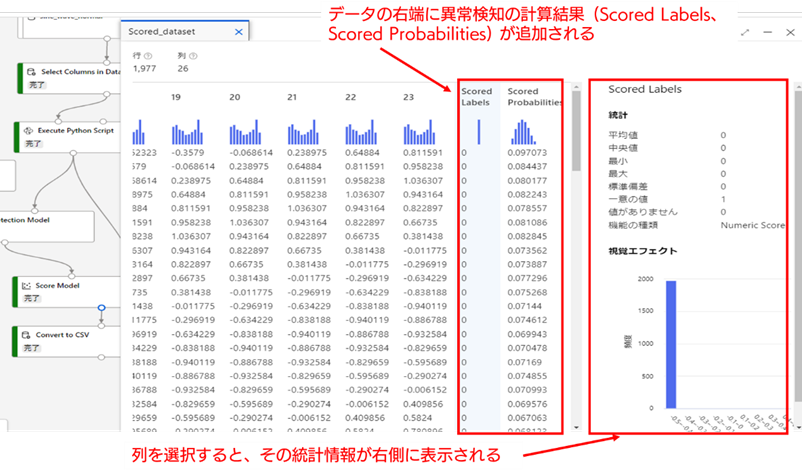
Scored Labels は正常・異常の判定結果(正常:0、異常:1)、Scored Probabilities は学習済みの異常検知モデルによって計算された異常の確率( 0-1 に規格化)を表しています(Azure ML デザイナー では、Scored Probabilities が 0.5 より大きい場合、異常と判定されます)。
上記データについて、Scored Labels の統計情報(列を左クリックすると右側に表示されます)を確認してみます。全てのデータが 0 と判定されており、学習用データは全て正常と判定されていることがわかります。これは、学習用データを正常データとして学習したため、想定通りの結果です。当然の結果の様に思うかもしれませんが、異常検知モデルが上手く学習できていない場合、学習用データについても異常であると誤検知してしまうことがあります。学習用データが正しく正常であると判定できているかどうか確認することは、モデルの妥当性を判断する上で重要なポイントの一つです。
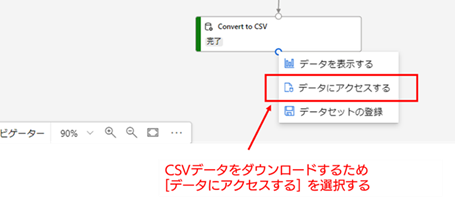
では、推論結果のCSVファイルをローカルPCにダウンロードして、中身のデータを確認してみます。[Convert to CSV] の出力ポートを「右クリック」してメニューを表示し、「データにアクセス」を選択してください。
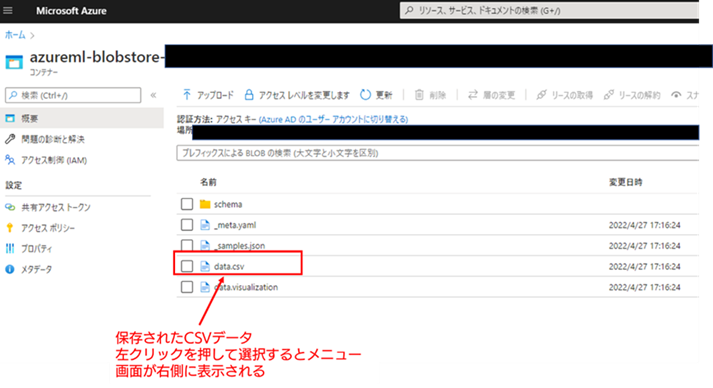
「データにアクセス」を選択するとブラウザに新しいタブが開き、以下の画面の様に、Azure 上で 対象のCSV ファイル が保存されている Storage Account の管理画面(Blob Storageの コンテナ)に遷移します。保存されている CSV ファイルの名称は「data.csv」です。
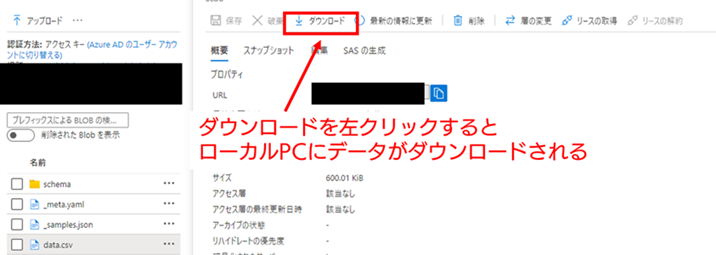
この対象の CSV データを左クリックで選択すると、画面の右側に以下の様なメニュー画面が表示されます。メニュー画面の上部にある、「ダウンロード」を選択すると、対象の CSV ファイルがローカル PC 上にダウンロードすることができます。
12. ダウンロードした学習用データの異常検知結果を可視化 : 対象のファイルをダウンロードすると「data.csv」という名称のファイルが、ダウンロード先のフォルダに保存されます。CSV ファイルのため、Microsoft Excel などを用いることで、グラフとして結果を可視化することができます。
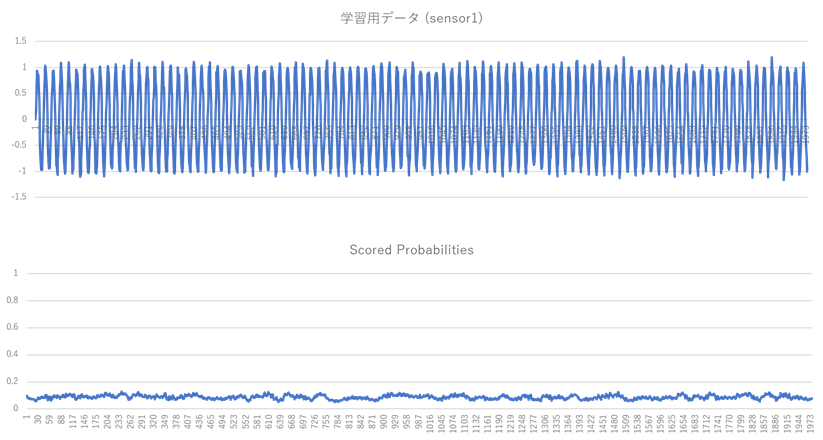
ここでは元データの sensor1 列 と data.csv の異常確率(Scored Probabilities 列)をグラフにして比較し、結果の妥当性を確認してみます。以下が横軸を時間にして、sensor1 列(上図)と Scored Probabilities 列(下図)をグラフにした図です。Scored Probabilities は0-1の範囲を取り、0.5以上が異常を表します。このグラフから、全ての時刻について Scored Probabilities は0に近い値を取っており、学習用データについては、全ての時刻で正常であると、正しく判定できていることが確認できました。
異常検知モデルの学習ができたので、次は異常を含む検証用のデータを用いて、データの正常でない部分を異常であると正しく検知できるか確認してみます。そのために、まずはトレーニング パイプラインのパイプライン ドラフトを元にして、推論用のパイプライン ドラフトを作成します。
1. バッチ推論パイプラインのパイプライン ドラフトの作成 : それでは、学習の実行をしたトレーニング パイプライン(anomaly-detection-training-pipeline)の画面に戻ってください。キャンバス領域の上部に、[推論パイプラインの作成] の項目がありますので、それを選択してプルダウンを表示してください。
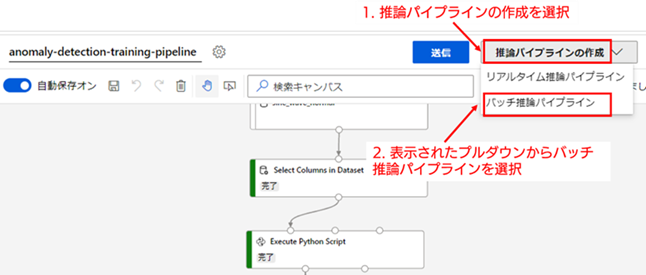
今回は、バッチ推論パイプラインという種類の推論パイプラインを作成します。バッチ推論パイプラインは、学習パイプラインとほぼ同じ機能を持ち、定期的に一定量のデータを推論するのに向いたパイプラインです。一方で、異常検知に限らず、リアルタイムな推論の実行には向いていません。リアルタイムな推論が必要な場合は、リアルタイム推論パイプラインを使用してください。
バッチ推論パイプラインは、プルダウンの [バッチ推論パイプライン] を選択することで作成することができます。選択すると以下の画像の様に、バッチ推論パイプラインのパイプライン ドラフトの画面に、画面が遷移します。なお、推論パイプライン ドラフトは、トレーニング パイプライン ドラフトの名称に「-batch inference」という suffix が付与された名称が自動で初期名称として設定されます。
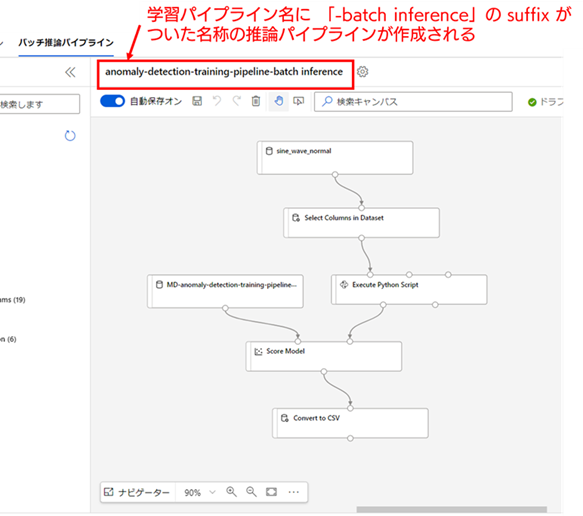
今回、トレーニング パイプライン ドラフトの名称を「anomaly-detection-training-pipeline」としたため、推論パイプライン ドラフトの名称にも「training」が入ってしまっています。これは少々紛らわしいので、以降は名称を「anomaly-detection-pipeline-batch inference」に変更したとして説明していきます。名称の変更方法は、トレーニング パイプライン ドラフトと同じです。
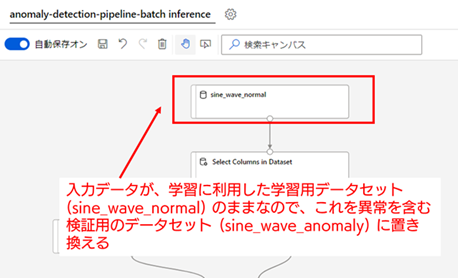
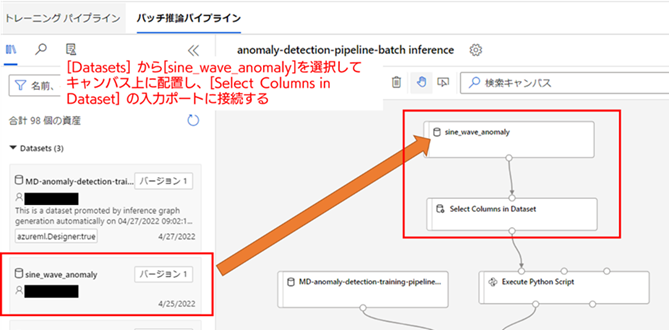
2. 入力元のデータセットを検証用データセット(sine_wave_anomaly)に置き換える : 作成された推論パイプライン ドラフトでは、入力元のデータセットが、学習用データセットのままになっています。そのため、この入力データセットを検証用の異常を含むデータセット(sine_wave_anomaly)に置き換える必要があります。
コンポーネントの削除は、削除したいコンポーネントを選択し、キャンバス上部にある削除ボタンを押すことで削除できます。もしくはコンポーネントを右クリックして表示されるメニューにある [削除] を選択することでも削除できます(なお、選択してからキーボードの Delete キーを押すだけでも削除できます)。
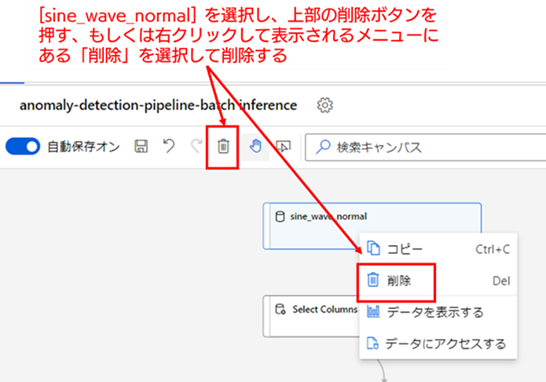
[sine_wave_normal] をキャンバス上から削除したら、検証用データセットである [sine_wave_anomaly] をキャンバス上に配置して、[Select Columns in Dataset] の入力ポートと連結してください。
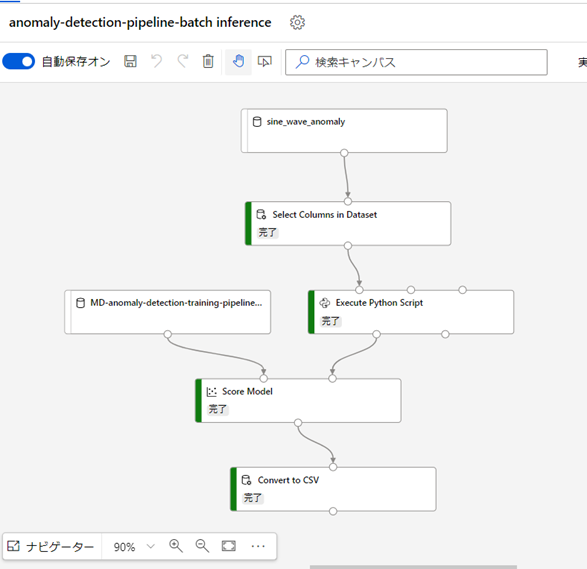
以上で、検証用データに対して推論パイプラインを使い異常検知を行う準備ができました。
3. 検証用データに対して、異常検知を実行する : バッチ推論パイプラインの実行手順は、トレーニング パイプラインの場合と全く同じです。
キャンバス上部の [送信] を選択すると、パイプライン実行のセットアップ画面が表示されるので、実行を記録する実験名を選択した後に、[送信] を選択してください。この際、実験については、すでに「anomaly-detection-demo」を作成しているので、今回はそれを選択します。すでに存在する実験を選択するには、[既存のものを選択] を選択した上で、[既存の実験] のプルダウンから対象の実験を選ぶことで指定できます。
推論パイプラインの実行を開始すると、トレーニング パイプラインと同じ様に、コンポーネントが順番に実行されていきます。推論パイプラインでも、全てのコンポーネントの実行には数分程度かかるので、完了するまで待機してください。
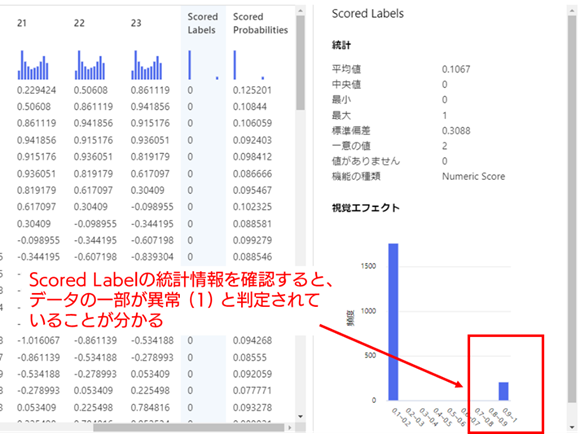
4. 検証用データに対する異常検知結果の確認 : 学習用データと同じ手順で、検証用データに対する異常検知結果を確認します。
まずは、デザイナーの画面上で結果のデータを表示してみます。[Score Model] の出力ポートからトレーニング パイプラインの時と同様の手順でデータを表示し、Scored Label 列の統計情報を確認してください。すると、学習用データの時と異なり、異常(数値は1)と判定されているデータが存在していることがわかります。
ただし、これだけではどのデータが異常と判断されたかわからないため、推論結果の CSV ファイル(ファイル名はトレーニング パイプラインの時と同様に data.csv)をダウンロードし、グラフとして可視化してみます。
以下の図は、横軸を時間として、検証用データの sensor1 列(上図)と、異常検知結果である異常確率(Scored Probabilities 列、0.5以上が異常に分類される)(下図)をグラフにして比較した図になります。それぞれのグラフを比較すると、ちょうど振動数が変化している異常部分において、Scored Probabilities が、ほぼ1に近い値を示しています。これは想定通りに、異常部分を正しく異常として検知できていることを示しています。
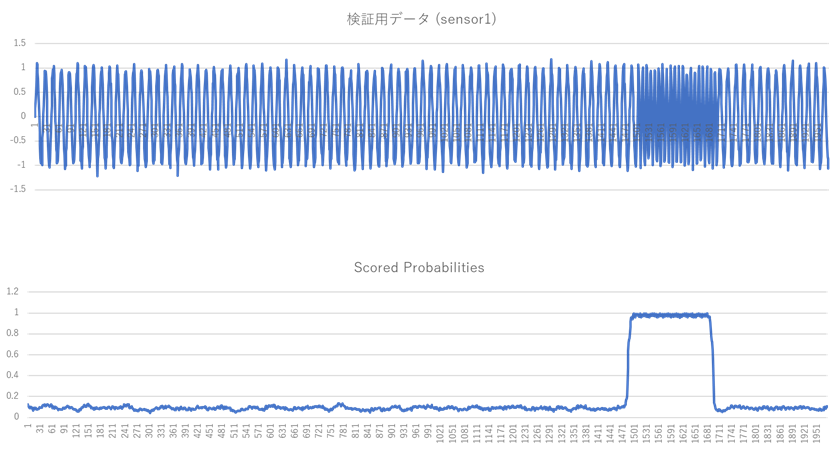
この様に、Azure ML デザイナー を使用すれば、今回は一部 Python スクリプトによる処理が必要でしたが、ほとんどの作業についてコードを書くことなく、機械学習を用いた異常検知が実施できてしまうということが体感できたかと思います。
Azure のサービスは従量課金制であり、特に一部のサービスはリソースが存在するだけでも料金が発生してしまうため、意図しない課金が発生する可能性があります。Azure ML の場合は、Azure ML のリソースに付随して作成される Storage Account や Container Registry、また今回は使用していませんが、コンピューティング インスタンスの作成を行うと、たとえ起動していなくても VM の managed disk 分の料金がかかることになります。
そのため、もし今後頻繁に利用する予定がないのであれば、Azure ML を作成したリソース グループについて、内部に属するリソースごと全て削除してしまうのが安全です。以下の手順は、Azure ML のチュートリアルに記載されている、チュートリアル実施後のリソースの削除手順となります。今後、作成したリソースを使用する予定がないのであれば、以下の手順に従って、リソースの削除を行ってください。
当社では、IoT 領域における時系列データの異常検知向け機械学習システムとして、ML Connect - Anomaly Detection をサービスとして提供しています。ML Connect とは、要約すると機械学習による学習と推論の自動化システムであり、時系列データの異常検知向けに ML Connect - Anomaly Detection、時系列データの将来値予測向けに ML Connect - Forecast の 2 種類のサービスを提供しています。
ML Connect - Anomaly Detection は、IoT データ基盤と連携することにより、以下の機能が実現できるサービスとなります。
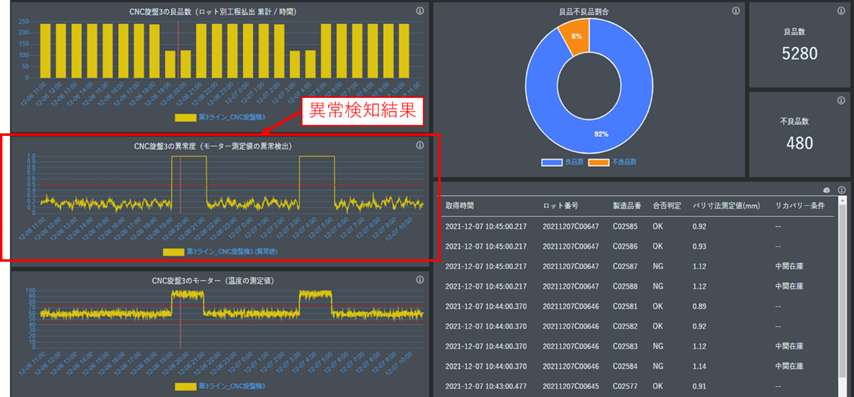
また、ML Connect - Anomaly Detectionは当社が提供する IoT 基盤サービスである IoT Core Connect(ICC)と連携して運用することを想定して設計されています。ICC とデータ連携することにより、ゲートウェイデバイスのデータ取得から、機械学習モデルによる学習と推論の実行、そして推論結果の可視化まで一貫したサービスとして提供することが可能となっています。以下の画像は、ML Connect - Anomaly Detection の異常検知結果を ICC で可視化した際のレポート画面のサンプルとなります。
本サービスにて構築できる異常検知モデルの主な活用先としては、以下に記載する様な各種センシングデータを活用した、機器の予知保全が挙げられます(予知保全 : 設備の状態を連続的に監視することで設備の劣化状態を把握・予知して、部品を交換したり修理したりする保全方式)。
1. 多変量かつ複雑な時系列構造を持つデータの異常検知を実現 : 本記事では主成分分析を利用した異常検知手法を紹介しましたが、主成分分析は線形変換を基礎とした手法のため、複雑な時系列構造を持つデータに適用することが難しいという課題があります。また、多変量時系列データにおける相関異常を検知することも困難です。
一方、ML Connect - Anomaly Detection では、より発展的な深層学習を用いた再構成ベースの異常検知手法を採用しています。このため、時系列構造の特徴をデータから学習することができ、より複雑な時系列データや多変量の時系列データについても異常検知が適用可能となっています。
2. Azure ML パイプラインを利用することによる低い利用コストの実現 : ML Connect - Anomaly Detection は、本記事で紹介した Azure ML のパイプライン上で動作するシステムとして構築されているため、計算リソースの効率的な自動スケーリング化が可能です。そのため、複数のデータの異常検知について並列処理を実行する際も、運用コストの低下を実現しています。
Azure ML のパイプライン機能を活用したことによる ML Connect - Anomaly Detection の利点は、以下の様にまとめられます。
一方で、以下に記載する様に、ML Connect - Anomaly Detectionによる異常検知が向かないデータやサポート外となる対象も存在します。
もし、以上の様な条件での時系列異常検知に関するご要望がある場合は、当社の機械学習導入支援サービスにて、異常検知モデル構築の実証実験(PoC)段階からサポートすることが可能です。そのため、この様なご要望がある場合でも、ぜひ当社にご相談いただければと思います。
本記事では、前編の記事で説明した時系列データの異常検知に関する知識をもとにして、Azure ML デザイナー 上で時系列データの異常検知を実施する具体的な手順について解説していきました。そして、簡単なサンプルデータについてではありますが、実際にある程度上手く異常検知ができるということを確認することができました。異常検知技術は、製造業における予知保全を目的とした利用だけでなく、システムの正常性監視やネットワーク監視など、多くの業界で需要がある技術です。本記事が、異常検知技術の概念やイメージをつかむ上で、少しでも皆様の参考になれば幸いです。
また、当社では時系列データを対象とした機械学習システムとして、本記事の最後に紹介した時系列データの異常検知向けの ML Connect - Anomaly Detection、および時系列データの将来値予測向けの ML Connect - Forecast、という2種類のサービスを提供しています。もし、自社で取得している時系列データについて、その活用方法を見出せていないなどの課題をお持ちの担当者の方がいましたら、ぜひ当社までお問い合わせください。
なお、当社では時系列データに限らず、画像、言語、マーケティング、Web サイト、IoT 機器のセンサーデータなど、様々な領域のデータについて、AI や機械学習を活用するための支援を行っています。業務で収集しているデータを活用したい、AI を使用してみたいが何をすればよいかわからない、やりたいことのイメージはあるがどの様なデータを取得すればよいか判断できないなど、データ活用に関する課題であれば広くサポートしますので、その際はぜひ当社までお気軽にご相談いただければと思います。
関連ページ |
