みなさま、こんにちは。急に肌寒くなってまいりましたが、体調いかがでしょうか。 私は先日までの猛暑をエアコン無しで過ごし生命の危機を感じておりましたので、肌寒さをむしろ喜んで受け入れております。 (それはそれとして風邪は引きました。)
さて、前回の記事では Azure ML Studio と Azure ML Services の特徴を、両者を比較する形でご紹介しました。今回の記事では Azure ML Services に絞ってその構成についてご紹介します。と言いますのも、私自身、構成の理解が不十分なままチュートリアルをしていて「あれ今何をしているのだっけ?」となってしまった経験があるためです。
Azure ML Services は大きく、Azure ML Workbench、実験サービス、モデル管理サービスという3つのサービスから構成されています。それぞれのサービスの関係を簡単にまとめると、下図のようになります。
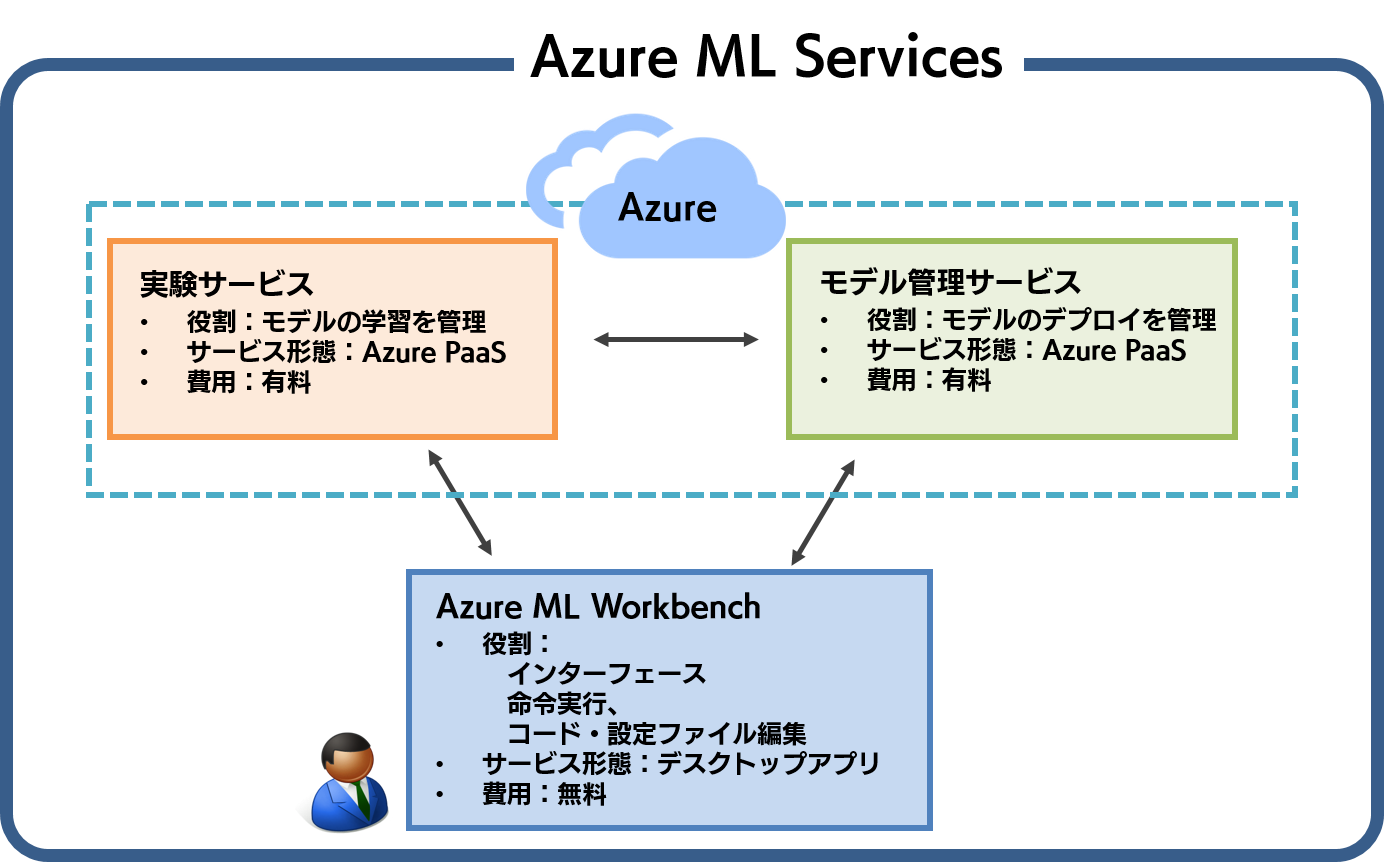
実験サービスは、モデルの学習を管理する Azure リソースで、基本的に有料です。モデル管理サービスは、学習済みモデルのデプロイ(API 化)を管理します。これもまた、基本有料の Azure リソースです。この二つに対して、Azure ML Workbench は無料で配布されているデスクトップアプリケーションで、インターフェースの役割を果たします。ローカルにインストールした Azure ML Workbench から、実験サービスやモデル管理サービスを実行したり、結果・状況の確認をしたりする、といった利用イメージです。
以降では、Azure 上のリソースである実験サービスとモデル管理サービスに絞り、重要な概念をご紹介します。Azure ML Workbench は便利なインターフェースという性質が強いため、概念学習よりも、実際に使って頂いた方が早く理解できると思います。
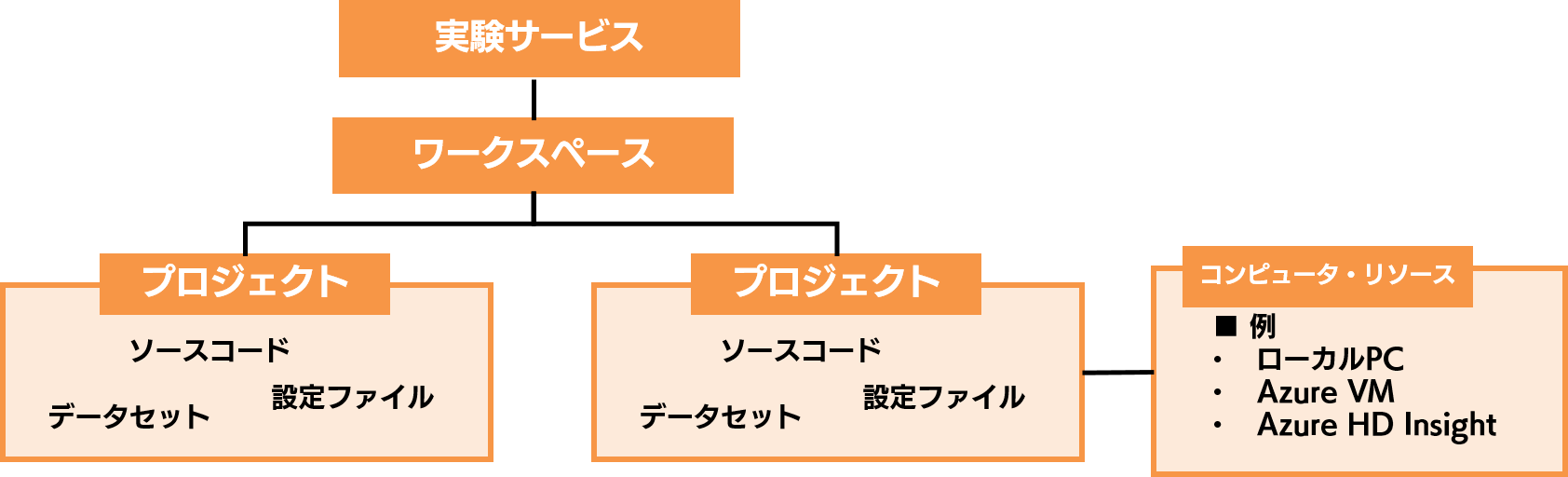
これからご説明する実験サービスの全体象を先に提示すると、下図のようになります。この全体図だけではよく分からないと思いますので、今から一つずつご説明していきます。
プロジェクト
まずは実験サービスの最も基本的な単位である、プロジェクトです。プロジェクトを一言で表せば、「モデルごとに必要なファイルをひとまとめにしたフォルダのようなもの」です。モデルごとに必要なファイルとしては、例えば以下のようなものが挙げられます。
モデルを構築したり実行したりするためのソースコード、モデル学習に使うデータセット、様々な設定情報や定義情報が格納されたファイル、そういったものがモデルごとに一つにまとまったものが、プロジェクトです。また、このプロジェクトは Git と連携することで、プロジェクト単位でバージョンを管理することも可能です。
ワークスペース
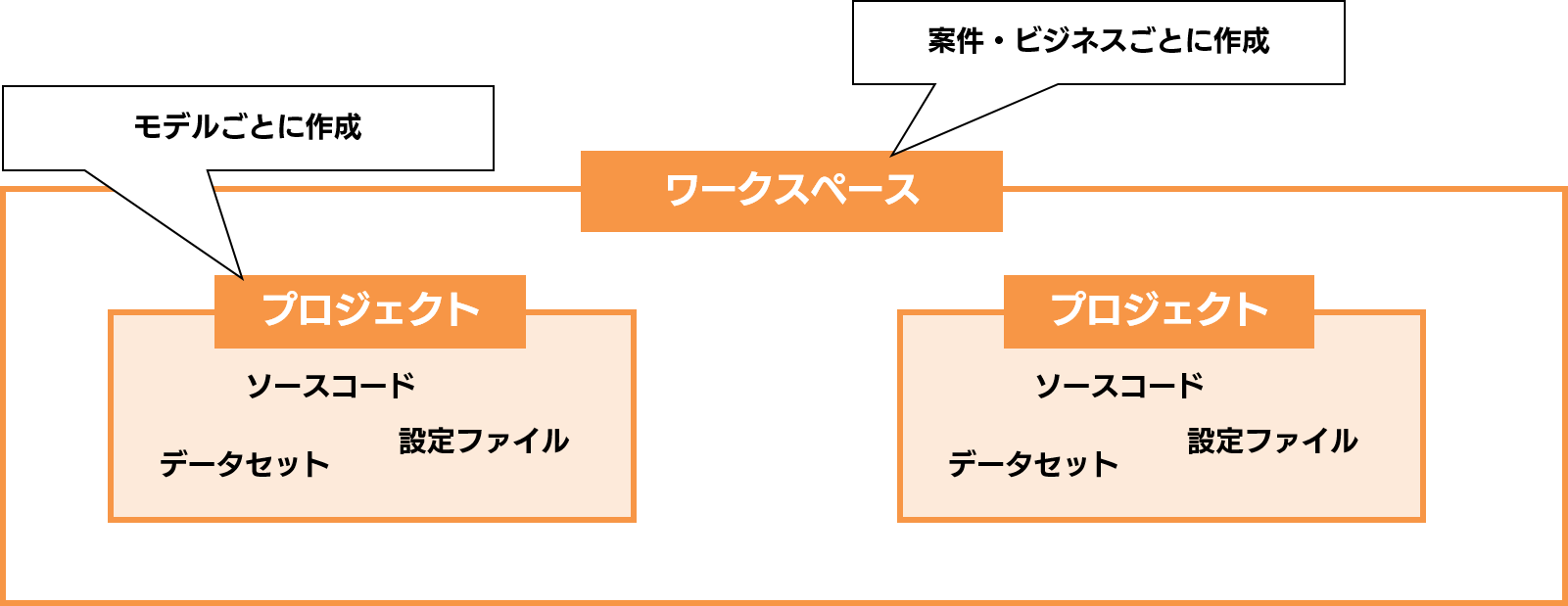
ワークスペースは、「プロジェクトが複数集まったフォルダのようなもの」です。複数の全く異なるモデルを構築する場合には、モデルごとにプロジェクトを複数作成し、ワークスペースにまとめることが出来るのです。
では、ワークスペースとプロジェクトはどのように使い分けるのでしょうか。これは私の個人的な使い分けイメージですが、案件や個別のビジネスごとにワークスペースを作り、その案件やビジネスで構築するモデルごとにプロジェクトを作ると良いかもしれません。言い換えると、ワークスペース = 案件・ビジネス用のフォルダ、プロジェクト = 個別のモデル用のフォルダ、というイメージです。そしてこのワークスペースの上に、「実験サービス」というリソースが存在しています。
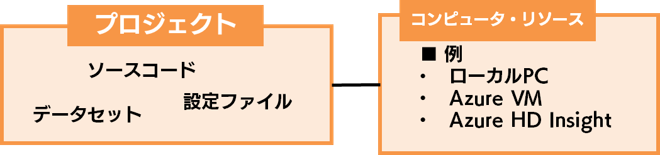
コンピュータ・リソース
コンピュータ・リソースは、モデル学習などの処理が実行される環境です。モデル実験サービスを利用すると、ローカル、VM、HD Insight などさまざまなコンピュータ・リソースで処理を行うことが出来ます。そのため、例えば「ローカルで学習すると時間がかかるな・・・。そうだ、分散環境で学習させよう!」といったことが簡単に行えるのです。
それぞれのコンピュータ・リソースは、本来は実験サービスとは独立に立てられたものです。それらを実験サービスのプロジェクトに登録することで、複数の環境で処理を行うことが可能になります。
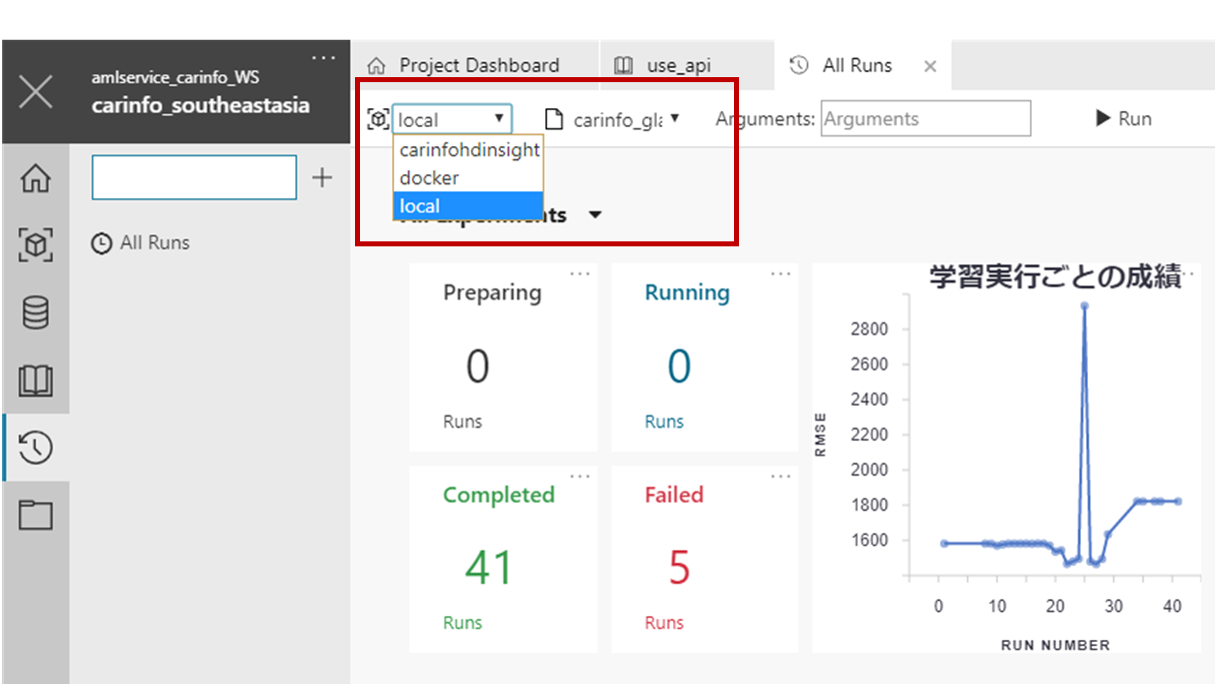
さらに Azure ML Workbench を使えば、下図のようなインターフェースで処理を実行させるコンピュータ・リソースを選ぶことができます。
実験サービスの構成まとめ
最後に、ここまで個別にご紹介した概念を頭の中で更に具体的に理解して頂くために、実験サービスでモデルを構築する際の流れを掲載しておきます。
▼実験サービスでモデルを構築する流れ
続いて、モデルのデプロイを司るモデル実験サービスの構成をご紹介します。先に全体図を示すと、下図のようになります。
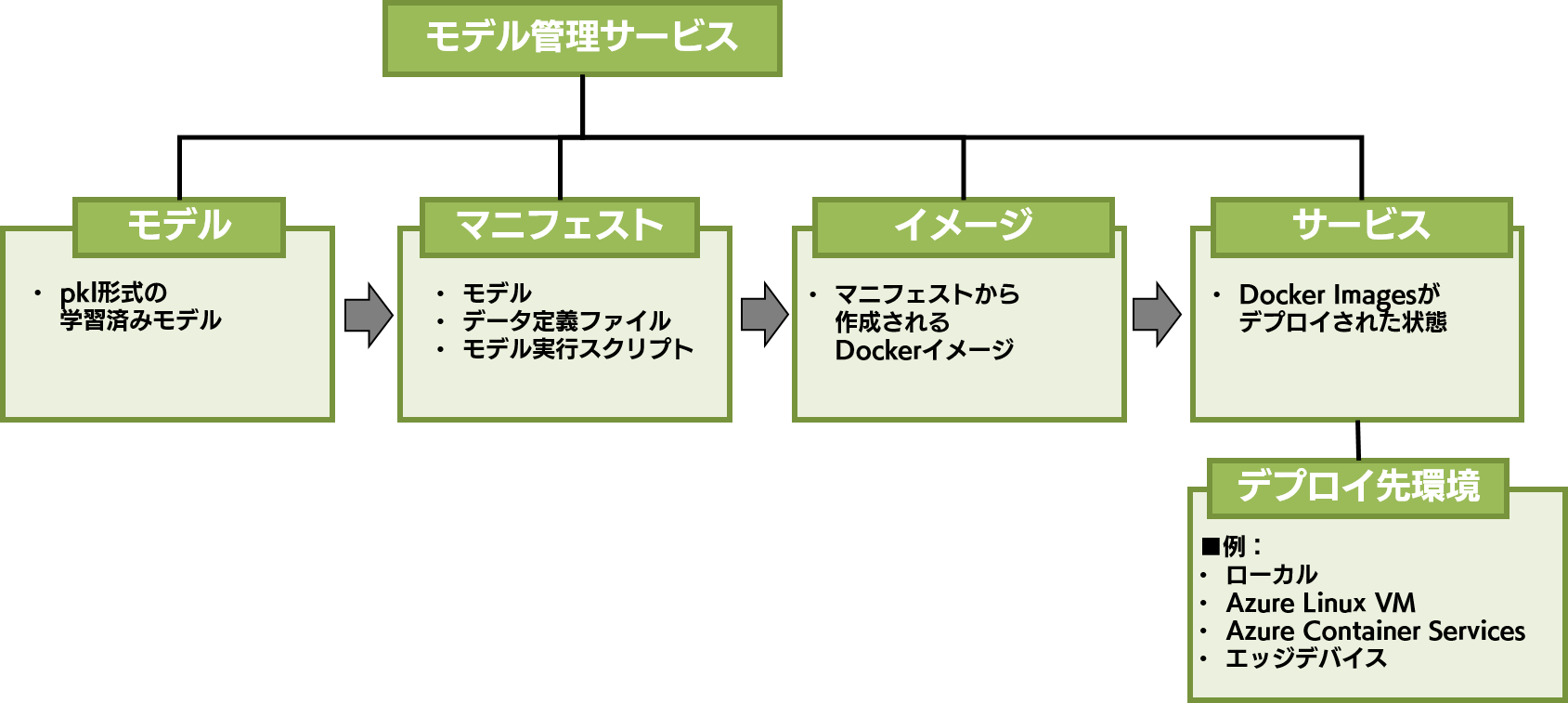
モデル
モデルは、もともとは .pkl という形式で出力された学習済みモデルです。最初のステップとして、まずこのモデルをモデル管理サービスにアップロードして登録します。
マニフェスト
モデルを登録しただけでは、何も動きません。そこで、このモデルに入力するデータの形式情報や、モデルを動かすスクリプトなど、モデルで予測をするのに必要なファイルを登録します。このようにモデル、データ定義、モデル実行スクリプトを合わせたものが「マニフェスト」となります。このマニフェストは、Docker イメージを作るためのレシピのようなものです。
イメージ
イメージとは、マニフェストが Docker イメージ化された状態のものです。マニフェストにはモデルを Web API 化するにあたって十分な情報がありますが、特定の環境でしか動かすことが出来ません。このマニフェストを Docker イメージ化することでさまざまな環境で動かすことができるようになるのです。
サービス
イメージが何らかの環境にデプロイされた状態のものが、サービスです。この状態になることで、構築したモデルを Web API として利用することが出来ます。また、ここまで紹介したモデル、マニフェスト、イメージ、サービスは、全てバージョン管理をすることが可能です。したがって、例えばサービスを誤ってデプロイしてしまったとしても、前のバージョンで再デプロイすることなどが簡単に行えます。
デプロイ先環境
デプロイ先環境は、名前の通り、Docker イメージがデプロイされ、サービスとして動いている環境です。デプロイ先の環境としては、以下のようなものが挙げられます。
例えば、Azure VM や AKS にデプロイすれば、サービスの利用状況に応じて簡単にスケールすることが可能です。また、デバイス上にデプロイをすれば AI 搭載デバイスを作成することもできてしまいます。
モデル管理サービスまとめ
後に、これまで個別に紹介したモデル管理サービスの概念をより具体的に理解するために、モデルをデプロイする際の流れを簡単にご紹介しておきます。
▼モデルをデプロイする際の流れ
今回は、Azure ML Services の構成についてご紹介しました。今後の記事では Azure ML Services の具体的な使い方も紹介する予定ですが、それまではこの記事を片手に 公式のチュートリアル などを試して、実際に動かして頂ければ Azure ML Services に対する理解がより深まると思います。
次回予告




