画像分類、物体検出、セグメンテーションなどの画像認識を行う際、避けては通れないのが、学習に使用する正解データセットの生成です。
「機械学習導入支援サービス」の詳細はこちら
「機械学習導入支援サービス」に関する資料請求・お問い合わせはこちら
VoTT とは
VoTT(Visual Object Tagging Tool)は、Microsoft が提供する、動画・画像に対してアノテーションをおこなう無償のアノテーションツールです。
良い点
GUI 操作で誰でも早く簡単にタグ付けができる
Windows、Mac、Linux を問わずクロスプラットフォームで利用できる
画像と動画に対してタグ付け可能
特に動画に関してはトラッキングの機能があり、使いやすい
CNTK、Tensorflow(Pascal VOC)、YOLO のアルゴリズムを使用する場合は、そのまま使用できる形式で出力できる
気を付ける点
出力された json ファイルを画像切り出しに使う場合、ファイル名は格納されないため、別途ファイル名を取得する必要がある
CNTK、Tensorflow(Pascal VOC)、YOLO 以外のアルゴリズムで使用したい場合、別途データセットの加工が必要
https://github.com/Microsoft/VoTT/releases
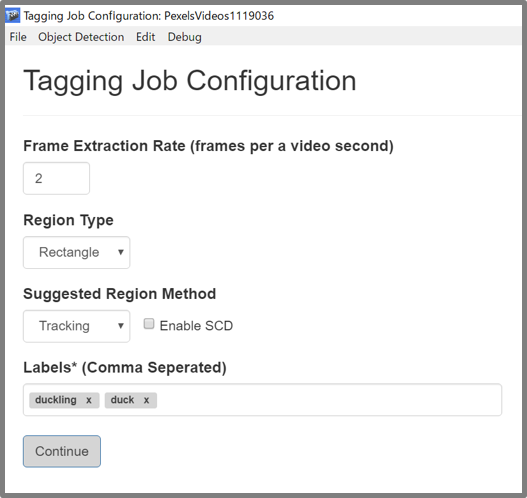
1. 設定
さっそく、アノテーションの設定を行っていきます。
動画を読み込んだら、以下のアノテーションの設定を行います。
Frame Extraction Rate:フレーム抽出率
Region Type:タグ付けを行うバウンディングボックスの種類
Rectangle(長方形):長辺、短辺の長さが任意のバウンディングボックス
Square(正方形):正方形のバウンディングボックスのみ
※ 特に制約などなければ、Rectangle でかまいません
Suggested Region Method:次のフレームの提案手法
Tracking:トラッキング
Copy Last Frame:前フレームをコピー
Enable SCD(Enable Scene Change Detection:シーン変化検出を有効にする)
Labels:ラベル(使用するタグの名前)
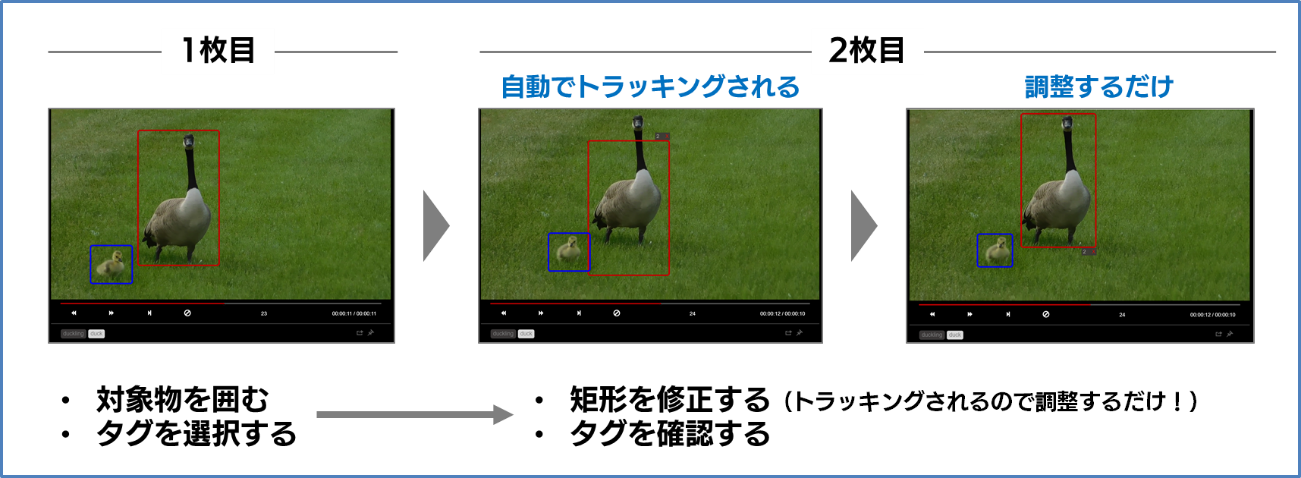
2. アノテーション
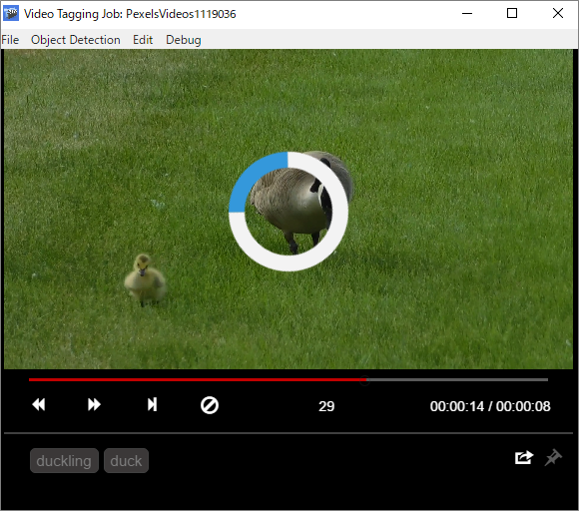
設定が完了したので、さっそくアノテーションを始めましょう。
主なタグ付けの手順としては、以下の3ステップを繰り返すだけです。
マウスで対象となる物体を囲む
タグを選択する
画像内のアノテーションがすべて終わったら、次に進むボタンをクリックする
前に戻る
次に進む
最初のタグ付けされていないフレームに移動する
フレーム内のタグをクリア
フレーム ID
現在の動画の時間
残りの動画の時間
タグ
また、トラッキング機能を設定することで、対象物を一から囲む手間がなくなり修正のみで済むので、より楽になります。
3. 出力
アノテーションが終わりましたら、VoTT でアノテーションした画像とその情報を出力します。方法としては、2つです。
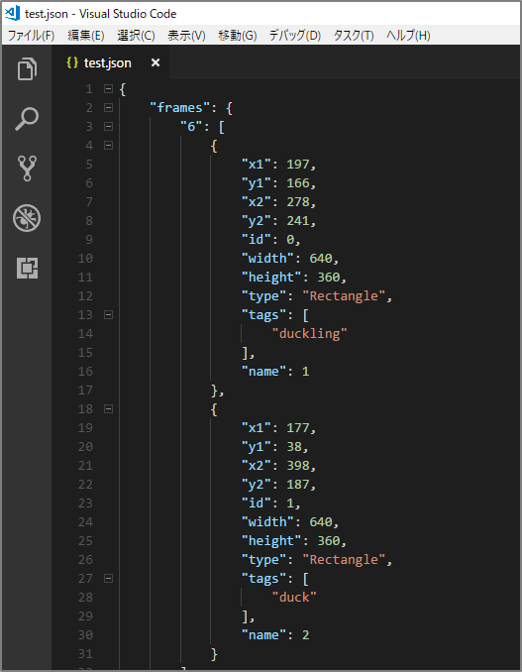
1. json 形式で出力する(自動)
自動的にタグやバウンディングボックスの座標が json ファイルで保存されます。
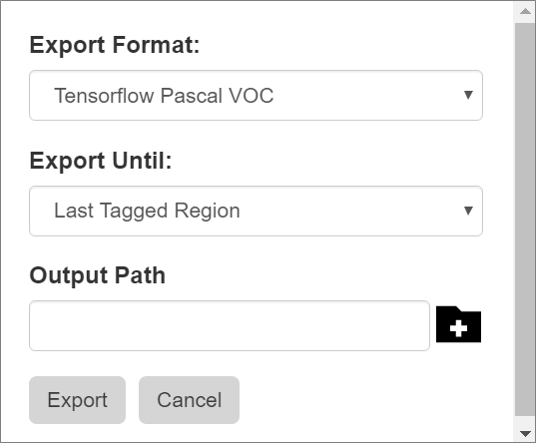
2. フォーマットを指定して、データセットとして出力する
[Object Detection]から、[Export Tags]を選択し、指定したアルゴリズムのデータセットとしてアノテーションした画像とその情報をエクスポートします。
Export Format
CNTK Fast-RCNN
Tensorflow(Pascal VOC)
YOLO
※ 全フレームの 20% をテスト用データセットとしてランダムに割り振ります
Export Until
Last Tagged Region:タグ付けした最後のフレームまで
Last Visited Frame:ユーザーが訪問した最後のフレームまで
Last Frame:すべてのフレーム
Training Path
出力には少し時間がかかることがありますが、気長に待ちます。
Annotations
タグ付けを行った画像ごとの情報(xml):画像のパス、サイズ、バウンディングボックスの座標等
ImageSets
学習、評価に使用する、タグごとのフレーム名(txt)
Pascal VOC は公開されている学習用データセットがありますので、そのデータセット以外で独自に検出したいものがある場合等に、VoTT でのアノテーション結果を追加して、一緒に学習させるというのも一つの手段です。こうすることで早く簡単に自分たちの状況にあったモデルを構築し、画像認識を行うことができます。
http://host.robots.ox.ac.uk/pascal/VOC/
「機械学習導入支援サービス」の詳細はこちら
さいごに
今回は、Microsoft 製のアノテーションツール VoTT をご紹介しました。少しでも早く簡単に、そしてすぐ使えるデータセットとして出力できるので大変便利ですよね。その他、公式 HP では、Docker を使用した学習等も紹介されており、運用も見据えた使い方も広がってくるでしょう。VoTT の機能も今後拡張される予定で、すでに予定されている機能としては、主に以下があります。
タグ付けプロジェクトのマネジメント
セグメンテーション
ズームイン/ズームアウト
画像認識に取り組んでみたいけど、なかなか動きだせない…というご担当者の皆様。ぜひこういったツールを活用しながら、一歩踏み出してみてはいかがでしょうか。データを整理し、溜める段階を超え、活用して課題解決する段階へと移行していきましょう。
次回予告